Sistemi esperti: MYCIN, XCON e l'era d'oro dell'AI commerciale
Tra il 1976 e il 1987 l’AI esce per la prima volta dai laboratori, rinuncia al sogno della macchina universalmente intelligente, e produce business reale: aziende, mercati, ROI misurabili. La parola d’ordine cambia da “general intelligence” a “knowledge is power”, e i sistemi esperti diventano per quasi un decennio l’unica AI che fattura.
Perché questo capitolo
Sezione intitolata “Perché questo capitolo”Aprile 1986: il fatturato annuo dell’industria mondiale dei sistemi esperti tocca quota stimata di un miliardo di dollari. Symbolics e Lisp Machines Inc. valgono centinaia di milioni in borsa, IntelliCorp e Inference Corp quotano in crescita, decine di nuove startup compaiono ogni trimestre. È la prima volta nella storia che qualcuno guadagna soldi veri facendo AI: non grant universitari, non promesse, contratti firmati da clienti aziendali. Quattro anni dopo, nel 1990, quasi tutta quella industria è scomparsa o ridotta a frammenti. Lisp Machines fallisce nel 1987, Symbolics nel 1992, le shell commerciali si svalutano del 90% nel giro di pochi trimestri.
I sistemi esperti meritano un capitolo per due ragioni che si tengono. La prima è filiazione: hanno introdotto la separazione fra conoscenza e ragionatore come principio architetturale, hanno definito il mestiere del knowledge engineering, hanno costruito il primo vocabolario industriale della knowledge representation. Una parte di quel vocabolario è discesa, attraverso strade indirette, fino agli strumenti contemporanei. La seconda è contro-esempio: il paradigma è fallito in modi specifici e ben documentati — knowledge acquisition bottleneck, brittleness, maintenance explosion, assenza di apprendimento, hardware proprietario obsoleto. Ognuno di questi modi di fallire ricompare con regolarità nelle ondate AI successive, sotto altri vestiti. Il confronto puntuale con le tecniche odierne è in “Applicazioni pratiche”.
Contesto
Sezione intitolata “Contesto”Questo capitolo prende il filo dalla fine di primo-inverno-ai. Tra il 1973 e il 1980 la AI pubblica e accademica era in pieno congelamento: il rapporto Lighthill aveva amputato i fondi britannici, ALPAC aveva chiuso la machine translation negli USA, “Perceptrons” aveva raffreddato il connessionismo. Ma sotto la neve non era tutto morto. A Stanford, a CMU, a SRI International alcuni gruppi avevano continuato a lavorare, cambiando agenda: invece di puntare alla general intelligence, avevano scelto domini specifici dove un’AI ristretta poteva produrre risultati misurabili.
Il pivot lo formula con più chiarezza Edward Feigenbaum (informatico statunitense, 1936-, premio Turing 1994, a Stanford dopo il PhD a Carnegie Tech con Herbert Simon). Nella sua Computers and Thought Lecture del 1977, alla quinta IJCAI di Cambridge in Massachusetts, Feigenbaum sintetizza la nuova agenda in una frase che diventerà slogan: “in the knowledge lies the power”. La tesi è chirurgica. L’intelligenza utile in un dominio non viene da algoritmi generali sofisticati, ma dall’accumulo di tanta conoscenza specifica al dominio. Il compito del ricercatore AI cambia natura: non è più inventare nuovi algoritmi di ricerca, è estrarre, organizzare e codificare la conoscenza degli esperti umani. Feigenbaum chiama la disciplina knowledge engineering.
Su questo sfondo si muovono i nomi che incontreremo. Bruce Buchanan (informatico statunitense, 1940-2025), filosofo di formazione e poi informatico a Stanford, è il principale collaboratore di Feigenbaum su DENDRAL e MYCIN. Joshua Lederberg (genetista statunitense, premio Nobel per la medicina nel 1958, 1925-2008) porta la motivazione applicativa di DENDRAL: identificare strutture molecolari da spettrometria di massa. Carl Djerassi (chimico organico austriaco-statunitense, 1923-2015, padre della pillola contraccettiva) è il chimico esperto la cui conoscenza viene codificata in regole. Edward “Ted” Shortliffe (informatico-medico statunitense, 1947-) sviluppa MYCIN per la sua tesi di dottorato a Stanford, con Buchanan e Stanley Cohen come supervisori. John P. McDermott (informatico statunitense, 1942-) costruisce a Carnegie Mellon il sistema R1 — poi rinominato XCON — per Digital Equipment Corporation (DEC), uno dei maggiori produttori di minicomputer dell’epoca. Richard Duda, Peter Hart e Nils Nilsson (informatico statunitense, 1933-2019) costruiscono PROSPECTOR a SRI International, il think tank di Menlo Park separatosi da Stanford nel 1970.
Le date che inquadrano l’era sono indicative ma utili come scheletro. DENDRAL parte nel 1965 ed è il primo sistema esperto della storia, ancorche embrionale. MYCIN vive tra il 1972 e il 1980 come progetto di ricerca a Stanford. PROSPECTOR opera dal 1974 al 1983. R1/XCON entra in produzione DEC nel 1980 e ci resta fino al 1989. Il Fifth Generation Computer System Project giapponese parte nel 1981 e chiude ufficialmente nel 1992. Il mercato commerciale dei sistemi esperti esplode tra il 1983 e il 1986, e collassa tra il 1987 e il 1990.

Vale la pena notare un fatto sociologico. Nel 1980 la AI accademica era piccola e ancora ferita dall’inverno. Il mercato dei sistemi esperti emerge in larga parte spin-off di pochi laboratori: IntelliCorp nasce da Stanford, Teknowledge da Stanford, Inference Corp da MIT/USC, Symbolics dal MIT AI Lab. Una manciata di persone con accesso a poche workstation Lisp diventa, per qualche anno, l’industria mondiale dell’AI commerciale. Quando la bolla scoppiera nel 1987, sarà la stessa manciata a subire il crollo.
L’intuizione
Sezione intitolata “L’intuizione”Angolo filosofico: rinuncia al generale per ottenere il particolare
Sezione intitolata “Angolo filosofico: rinuncia al generale per ottenere il particolare”I primi vent’anni dell’AI (1956-1976) avevano puntato all’intelligenza generale. Il Logic Theorist e il General Problem Solver di Allen Newell e Herbert Simon, SHRDLU di Terry Winograd, gli studi sul checker-playing di Arthur Samuel: tutti tentativi di trovare principi computazionali general-purpose che, una volta scoperti, avrebbero spiegato e prodotto intelligenza in qualunque dominio. La promessa di Herbert Simon nel 1965 — machines will be capable, within twenty years, of doing any work a man can do — appartiene a questa stagione.
La combinatorial explosion e il primo inverno hanno mostrato che la promessa non reggeva. Gli algoritmi di ricerca generali esplodevano in problemi reali; i microworlds non si scalavano; il common sense reasoning sul mondo aperto sembrava intrattabile. La via generalista era bloccata, e il finanziamento si stava esaurendo.
I sistemi esperti emergono come risposta pragmatica e quasi rassegnata. La tesi di Feigenbaum si può riformulare così: dato che l’AI generale non funziona, smettiamo di cercarla e costruiamo AI ristretta che funziona. Scegliamo un dominio dove valgono tre condizioni. Primo: c’è un esperto identificabile la cui performance vale soldi (un internista che diagnostica infezioni, un assemblatore di VAX, un geologo di prospezione). Secondo: la conoscenza dell’esperto si può articolare in regole (almeno in una percentuale significativa, anche se non tutta). Terzo: il problema è chiuso abbastanza da non richiedere common sense reasoning sul mondo intero.
È un’inversione di prospettiva. Prima si cercava un algoritmo generale; ora si cerca un dominio con un esperto da imitare. Il programma non capisce il mondo; sa fare una cosa specifica meglio di un giovane medico, di un tecnico junior, di un geologo di campo. La generalita viene barattata per la profondità.
Lo stesso baratto attraversa, in forme nuove, ogni volta che si discute “AI general-purpose” contro “AI specializzata”. La discussione contemporanea è ripresa in “Applicazioni pratiche”.
Angolo operativo: la regola IF-THEN come unita di conoscenza
Sezione intitolata “Angolo operativo: la regola IF-THEN come unita di conoscenza”Il secondo angolo è artigianale. Una regola IF-THEN dice: “se vedi questi sintomi, sospetta questa diagnosi”. È la forma in cui un internista insegna a uno specializzando, in cui un meccanico esperto spiega a un apprendista, in cui un compliance officer documenta una policy. Codificare il sapere in regole è tradurre l’oralita esperta in qualcosa che una macchina può applicare.
L’inference engine è un orchestratore di regole. Da un punto di vista operativo lavora in due modi principali. Forward chaining: parto dai fatti che ho, applico tutte le regole le cui premesse sono soddisfatte, derivo nuovi fatti, ripeto fino a convergenza. Backward chaining: parto da un’ipotesi, cerco regole che la concluderebbero, verifico se le loro premesse sono vere; se non lo sono ma sono a loro volta concludibili da altre regole, ricorro; se non lo sono e non sono concludibili, le chiedo all’utente.
L’eleganza dell’architettura è la separazione knowledge / control. La stessa inference engine può girare su KB diverse: un MYCIN smontato dalla sua KB di infezioni è E-MYCIN (Empty MYCIN, 1980), pronto a ricevere KB di domini differenti. Nasce qui l’idea di expert system shell: un prodotto commerciale che fornisce inference engine, interfaccia utente e tool di knowledge editing, da personalizzare con regole del proprio dominio. KEE di IntelliCorp, ART di Inference Corp, OPS5 di Forgy a CMU, CLIPS della NASA: tutti shell di questa famiglia.
La separazione knowledge / control è una delle invenzioni intellettualmente più importanti dell’era. È un principio architetturale generale (modulo che decide / modulo che sa), non legato alla specifica tecnologia delle production rules. Le sue ricadute nelle architetture contemporanee sono discusse in “Applicazioni pratiche”.

La meccanica
Sezione intitolata “La meccanica”Architettura generica
Sezione intitolata “Architettura generica”Un sistema esperto nella forma canonica ha cinque componenti.
La knowledge base è la rappresentazione esplicita della conoscenza del dominio. Negli anni Settanta-Ottanta il formato dominante è la production rule (regola IF-THEN), introdotta da Allen Newell e Herbert Simon nel framework dei production systems. Una regola ha la forma: se queste premesse sono vere, allora concludi questi fatti / esegui queste azioni. Formati alternativi includono frames (proposti da Marvin Minsky nel paper “A Framework for Representing Knowledge”, 1974, MIT AI Lab Memo 306), semantic networks (Quillian 1968, Schank 1972) e logica predicativa (Prolog, formalismi di description logic). Per il filo principale di questo capitolo restiamo sulle production rules: è il formato di MYCIN, di XCON e della grande maggioranza dei sistemi commerciali.
L’inference engine è il meccanismo che applica le regole della KB ai fatti del problema corrente. Implementa forward chaining, backward chaining, o entrambi. Dal punto di vista algoritmico è un loop di pattern matching: a ogni passo identifica quali regole “scattano” (le cui premesse matchano i fatti correnti) e ne sceglie una da applicare secondo una conflict resolution strategy (recency, specificity, priority esplicita, refractoriness).
La working memory è lo spazio dove vivono i fatti del problema corrente: sia quelli forniti dall’utente all’inizio (i sintomi del paziente, l’ordine cliente per il VAX, i dati geologici di un’area), sia quelli derivati dall’inference engine durante l’esecuzione. La working memory cresce nel tempo e di solito non viene mai compattata: i fatti derivati restano per supportare le spiegazioni.
La user interface negli anni Settanta-Ottanta è tipicamente un dialogo testuale a domande. MYCIN chiedeva al medico una serie di domande sul paziente, il medico rispondeva con valori (numerici, categorici, o “unknown”), MYCIN procedeva. Per i sistemi commerciali più tardi (KEE, ART) emergono interfacce grafiche su Lisp Machines, ma il pattern interrogativo resta dominante.
L’explanation module è una caratteristica distintiva del paradigma. Il programma può spiegare perché sta facendo una certa domanda — “sto cercando di determinare se l’organismo è Gram-negativo, perché se lo è la regola R23 si applica” — e come è arrivato a una conclusione — “ho concluso X applicando R12, R23, R45 sui fatti Y, Z”. Nei sistemi rule-based questa capacità è nativa: l’inference engine sa quali regole ha applicato e in che ordine; l’explanation è un dump strutturato del proof tree. (Il confronto con le forme di “spiegazione” disponibili nei sistemi probabilistici contemporanei è in “Applicazioni pratiche”.)
Forward vs backward chaining
Sezione intitolata “Forward vs backward chaining”I due regimi dell’inference engine si distinguono per direzione di inferenza.
Il forward chaining parte dai fatti e va verso le conclusioni. Pseudo-codice:
function forward_chain(rules, facts): changed = True while changed: changed = False for rule in rules: if rule.premises subset of facts and rule.conclusion not in facts: facts.add(rule.conclusion) changed = True return factsL’algoritmo termina quando un’iterazione completa non aggiunge nessun fatto nuovo. È adatto a problemi data-driven dove i fatti iniziali sono molti e si vogliono derivare tutte le conseguenze. Esempio canonico: XCON. L’ordine cliente del VAX include centinaia di componenti scelti dal cliente; XCON applica forward chaining per derivare tutti i componenti aggiuntivi necessari (cavi, controller, slot, cabinets) e per validare che non ci siano conflitti.
Il costo computazionale ingenuo del forward chaining è per iterazione, con numero di regole e numero di fatti. Per KB grandi diventa proibitivo. Charles Forgy (informatico statunitense, allievo di Newell a CMU) introduce nel 1982 nel paper “Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem” l’algoritmo RETE, che indicizza le premesse delle regole in una rete di pattern-matching e riusa lo stato di matching tra iterazioni successive. RETE è la base di OPS5 (in cui XCON è scritto), e oggi vive in CLIPS, Drools, Jess, IBM ODM. È un caso raro di algoritmo degli anni Ottanta che è ancora produzione vera quarant’anni dopo.
Il backward chaining parte da un goal (un’ipotesi) e va verso le premesse. Pseudo-codice:
function backward_chain(goal, rules, facts, asked): if goal in facts: return True if goal in asked: return ask_user(goal) for rule in rules where rule.conclusion == goal: if all backward_chain(p, rules, facts, asked) for p in rule.premises: facts.add(goal) return True return FalseÈ adatto a problemi goal-driven dove le ipotesi sono poche e i fatti potenzialmente molti, e si vuole evitare di chiedere all’utente fatti irrilevanti per il goal corrente. Esempio canonico: MYCIN. Il medico vuole sapere se il paziente ha meningite batterica e quale antibiotico somministrare; MYCIN sceglie il goal “il paziente ha meningite batterica?” e backward-chaina, chiedendo al medico solo le informazioni necessarie a confermare o smentire questo specifico goal.

La scelta tra i due dipende dalla forma del problema. Quando i fatti iniziali sono pochi e le ipotesi sono molte, forward chaining è uno spreco (deriva tutte le conseguenze, anche irrilevanti). Quando i fatti iniziali sono molti e le ipotesi sono poche, backward chaining è inefficiente (riconsidera ogni ipotesi separatamente). Alcuni sistemi (CLIPS, Soar) supportano entrambi i regimi e li alternano.
DENDRAL: il nonno
Sezione intitolata “DENDRAL: il nonno”DENDRAL parte a Stanford nel 1965. Nasce da una collaborazione insolita per l’epoca: un genetista premio Nobel (Lederberg), due informatici (Feigenbaum e Buchanan), un chimico organico (Djerassi). La motivazione viene da Lederberg: la NASA stava per inviare sonde su Marte; tra gli strumenti di bordo ci sarebbero stati spettrometri di massa per analizzare campioni di atmosfera e suolo; serviva un programma che identificasse strutture molecolari dai dati spettroscopici, perché il bandwidth con la Terra non avrebbe permesso di rimandare i dati grezzi.
Il problema in astratto. Data una formula chimica e uno spettro di massa, trovare la struttura molecolare (la connettivita degli atomi) consistente con i dati. Lo spazio delle strutture possibili per una formula chimica anche modesta è enorme — milioni o miliardi di candidati. Un chimico esperto non enumera lo spazio: usa euristiche, sa “a colpo d’occhio” che certe sotto-strutture sono comuni, certe sono rare, certe sono chimicamente impossibili.
DENDRAL ha due componenti. Heuristic DENDRAL è un generatore + filtro: enumera strutture in modo esaustivo ma ordinato, e applica regole esperte (estratte da Djerassi) per scartare quelle implausibili. Meta-DENDRAL (sviluppato dal 1976 da Bruce Buchanan e Tom Mitchell, allora dottorando a Stanford) impara automaticamente nuove regole dai dati spettroscopici di molecole note. Meta-DENDRAL è uno dei primi sistemi di machine learning applicati a un dominio reale, decenni prima che il termine “machine learning” diventasse popolare.
DENDRAL ha pubblicato risultati su riviste di chimica come autore. Questa è la prima volta nella storia che un programma è coautore di una pubblicazione scientifica come strumento esperto, non solo come strumento computazionale.
MYCIN: il sistema esperto più studiato della storia
Sezione intitolata “MYCIN: il sistema esperto più studiato della storia”Tra il 1972 e il 1974 Ted Shortliffe sviluppa MYCIN per il suo PhD a Stanford. Shortliffe stava facendo MD/PhD parallelo: medico e informatico insieme, una traiettoria rara all’epoca. Supervisori: Buchanan (informatico) e Stanley Cohen (medico, Stanford Hospital). Il dominio: diagnosi di infezioni batteriche del sangue (batteriemia) e meningiti batteriche, con raccomandazione di terapia antibiotica.
La scelta del dominio non è casuale. La diagnosi di infezione batterica e la scelta dell’antibiotico hanno caratteristiche ideali per un sistema esperto. Il problema è chiuso: c’è un numero finito di organismi patogeni, un numero finito di antibiotici, vincoli noti. La conoscenza dell’esperto si articola bene in regole (che antibiotico dare se l’organismo è X, se il paziente è allergico a Y). Le decisioni sono ad alto valore (un’infezione del sangue trattata male uccide). E i medici junior sbagliavano spesso: una baseline contro cui mostrare miglioramento c’era.
L’architettura. Knowledge base: circa 600 regole IF-THEN con certainty factors. Inference engine: backward chaining puro. Working memory: i fatti del paziente corrente. Interfaccia: dialogo testuale a domande. Explanation: WHY (spiega perché sta chiedendo questa domanda) e HOW (spiega come ha derivato una conclusione).
Esempio di regola, semplificato dal formalismo originale di MYCIN:
RULE 280:IF the infection is meningitis AND the type of infection is bacterial AND the patient has undergone surgery AND the patient has undergone neurosurgery AND the neurosurgery-time was less than 2 months ago AND the patient got a ventricular-urethral shuntTHEN there is suggestive evidence (CF 0.8) that the organism is e.coli or staphylococcus-coag-posI certainty factors (CF) sono numeri tra e . CF significa “certo che vero”, CF “certo che falso”, CF “nessuna evidenza”. Ogni regola ha un CF associato che ne misura la forza. Quando più regole concludono lo stesso fatto, i loro CF si combinano con formule ad hoc (non bayesiane). Per due CF positivi e la combinazione è:
In parole povere: il secondo CF “riempie” parte di ciò che resta da . Per due CF di segno opposto la formula è diversa, e per le catene di regole il CF della premessa moltiplica il CF della regola.
I CF erano un compromesso pratico. La via teoricamente corretta — la probabilita bayesiana completa — richiedeva di elicitare dai medici prior, likelihood, e probabilita condizionate per ogni combinazione di fatti. In pratica i medici non sapevano dare quei numeri (e quando ci provavano, davano numeri inconsistenti). I CF di Shortliffe e Buchanan erano numeri singoli, intuitivi, che il medico poteva fornire pensando a una regola alla volta. Funzionavano. David Heckerman, in “Probabilistic Interpretations for MYCIN’s Certainty Factors” (Uncertainty in AI, 1986), dimostra che i CF sono coerenti con Bayes solo sotto assunzioni di indipendenza condizionale forti, raramente vere nei domini reali. Il successore teorico arriva con le reti bayesiane di Judea Pearl (“Probabilistic Reasoning in Intelligent Systems”, Morgan Kaufmann, 1988), che permettono di rappresentare esplicitamente le dipendenze condizionali e di calcolare l’inferenza in modo principled.

Performance. Lo studio più citato è Yu et al. 1979, “Antimicrobial Selection by a Computer”, JAMA. In valutazione cieca con la facolta di Stanford Medical (esperti di malattie infettive valutavano le terapie suggerite senza sapere se venissero da MYCIN o da medici reali), le terapie suggerite da MYCIN furono giudicate accettabili nel 65-69% dei casi, comparabile o superiore ai medici junior della specializzazione di malattie infettive, e nello stesso ordine di grandezza degli specialisti senior.
Eppure MYCIN non è mai stato usato in clinica. È uno dei punti che genera più confusione nella divulgazione. Il sistema funzionava, era più accurato di un giovane medico, e ciononostante non ha mai diagnosticato un paziente vero. Le ragioni del non-deployment sono tre, intrecciate. Legali: chi paga se MYCIN sbaglia? Negli anni Settanta il quadro normativo per software medicale non esisteva; nessun ospedale voleva essere il primo a essere citato in giudizio. Pratiche: MYCIN girava su un terminale a tempo condiviso del Stanford Medical Center, l’interazione era lenta, il dialogo a domande prendeva 20-30 minuti per caso; un medico esperto pensava più in fretta. Istituzionali: l’ospedale non aveva infrastruttura informatica al letto del paziente; le cartelle cliniche erano cartacee; nessuna integrazione possibile.
È un caso paradigmatico di “tecnicamente funziona, socialmente non funziona”. La lezione attraversa decenni: anche oggi un modello che vince un benchmark non è un prodotto, e la distanza tra benchmark e produzione è fatta di legali, integrazione, workflow, cultura organizzativa.
L’eredità di MYCIN viene da un’altra parte. Nel 1980 William van Melle, dottorando a Stanford, smonta MYCIN dalla sua KB di infezioni e ne pubblica lo scheletro come E-MYCIN (Empty MYCIN). È il primo expert system shell della storia: l’inference engine di MYCIN, riusabile in altri domini. Da E-MYCIN derivano PUFF (diagnosi di malattie polmonari, deployato a Pacific Medical Center di San Francisco nel 1979 — uno dei pochi expert system clinici davvero usati, anche se in nicchia), CADUCEUS, SACON e altri.
XCON e DEC: l’AI che fattura
Sezione intitolata “XCON e DEC: l’AI che fattura”R1 nasce a Carnegie Mellon nel 1978. John P. McDermott, all’epoca professore associato di informatica a CMU, ha un cliente reale: Digital Equipment Corporation, il secondo produttore mondiale di computer dopo IBM, specializzato in minicomputer della famiglia VAX (VMS-Architecture eXtended, lanciata nel 1977). Il problema di DEC è concreto e costoso. Un cliente che ordina un VAX sceglie tra decine di migliaia di componenti: CPU di vari modelli, banchi di memoria, disk drive, controller di I/O, cabinet, cavi, alimentatori. I componenti hanno vincoli di compatibilità: questa CPU richiede questo backplane, questo disk drive richiede questo controller dedicato, questo cabinet ha tot slot per controller, questo controller occupa tre slot consecutivi.
Un assemblatore umano impiegava ore a configurare un VAX, e sbagliava nel 10-30% dei casi. Un errore aveva conseguenze economiche pesanti: spedizione di componenti sbagliati al cliente, ri-spedizione di parti mancanti, ritardi, customer dissatisfaction. McDermott convinse DEC che un sistema basato su regole poteva fare meglio.
R1 viene scritto in OPS5, il linguaggio di production rules di Charles Forgy a CMU. Forward chaining con algoritmo RETE. Il nome “R1” viene da una battuta di McDermott (riferito all’idea che “tre anni fa non sapevo nemmeno cosa fosse un computer, e ora ne sono uno”). Quando passa in produzione DEC nel 1980 viene rinominato XCON, eXpert CONfigurer.
Crescita della knowledge base. McDermott documenta nei suoi paper:
- 1979: ~750 regole (R1 in fase di test).
- 1984: ~2500 regole (XCON in produzione, copre la maggior parte dei VAX).
- 1986: ~8000 regole (XCON è il sistema esperto in produzione più grande del mondo).
- Verso fine vita (1989): oltre 17000 regole, con team dedicato di knowledge engineer.
ROI per DEC. Le stime ufficiali, riportate da McDermott e da Barker e O’Connor in “Expert systems for configuration at Digital: XCON and beyond” (Communications of the ACM, vol. 32, n. 3, 1989), parlano di 25-40 milioni di dollari l’anno di risparmi diretti, calcolati come somma di: errori di configurazione ridotti, tempo di assemblaggio ridotto, costi di customer support ridotti. Cumulativo nella vita del sistema: “centinaia di milioni di dollari”. Le cifre esatte sono difficili da verificare a posteriori (DEC è stata acquisita da Compaq nel 1998, poi da HP nel 2002), ma l’ordine di grandezza è accettato dalla letteratura.
XCON è il caso più citato di expert system con ROI dimostrato. Insieme a PROSPECTOR (di cui parliamo subito sotto), è la prova industriale che fa partire il boom commerciale dei sistemi esperti tra il 1983 e il 1986.
Però XCON ha rivelato anche il lato oscuro che diventerà la causa principale del crollo del paradigma: il knowledge engineering bottleneck in produzione. Mantenere migliaia di regole, aggiornarle quando il catalogo VAX cambiava (ogni 6-12 mesi DEC introduceva nuovi componenti e ne ritirava altri), evitare che una regola nuova entrasse in conflitto con regole esistenti — divento’ un problema operativo gigantesco. DEC dovette costruire un team dedicato di circa 50 knowledge engineer per mantenere XCON. Il costo di manutenzione cresceva più rapidamente del valore aggiunto. A meta degli anni Novanta XCON viene gradualmente smantellato; DEC stessa, per ragioni indipendenti (l’avvento di PC e workstation Unix che erodevano il mercato dei minicomputer), entra in declino.

PROSPECTOR e il giacimento di molibdeno
Sezione intitolata “PROSPECTOR e il giacimento di molibdeno”PROSPECTOR nasce a SRI International nel 1974, sotto la direzione di Richard Duda, Peter Hart e con la supervisione di Nils Nilsson. Dominio: prospezione mineraria. Input: dati geologici di superficie di un’area (formazioni rocciose, alterazioni, anomalie magnetiche, geochimica). Output: stima della probabilita che l’area contenga un giacimento di un certo tipo (rame porfirico, molibdeno, oro epitermale, ecc.) e indicazioni su dove perforare per verificare.
A differenza di MYCIN, PROSPECTOR usa inferenza bayesiana esplicita. Ogni evidenza geologica ha un peso bayesiano (likelihood ratio) per ogni tipo di giacimento; il sistema combina i pesi con il teorema di Bayes per aggiornare la probabilita posteriore. È tecnicamente più corretto dei certainty factors, ma richiede di elicitare dai geologi numeri probabilistici che i geologi davano malvolentieri.
L’episodio più citato. Nel 1982 PROSPECTOR identifica una zona promettente a Mount Tolman (Washington state), in un’area di proprieta della Phelps Dodge Corporation. La perforazione conferma l’esistenza di un giacimento di molibdeno di valore stimato intorno a 100 milioni di dollari. È il primo caso documentato di “expert system trova denaro vero” e diventa parte della letteratura standard sui sistemi esperti.
(Caveat storiografico: alcuni revisionisti successivi hanno fatto notare che la zona era già sospetta da indagini geologiche umane, e che PROSPECTOR ha confermato piuttosto che scoperto. Resta vero che il sistema ha fornito un contributo decisionale rilevante e che la cifra era reale.)
L’industria 1980-1987
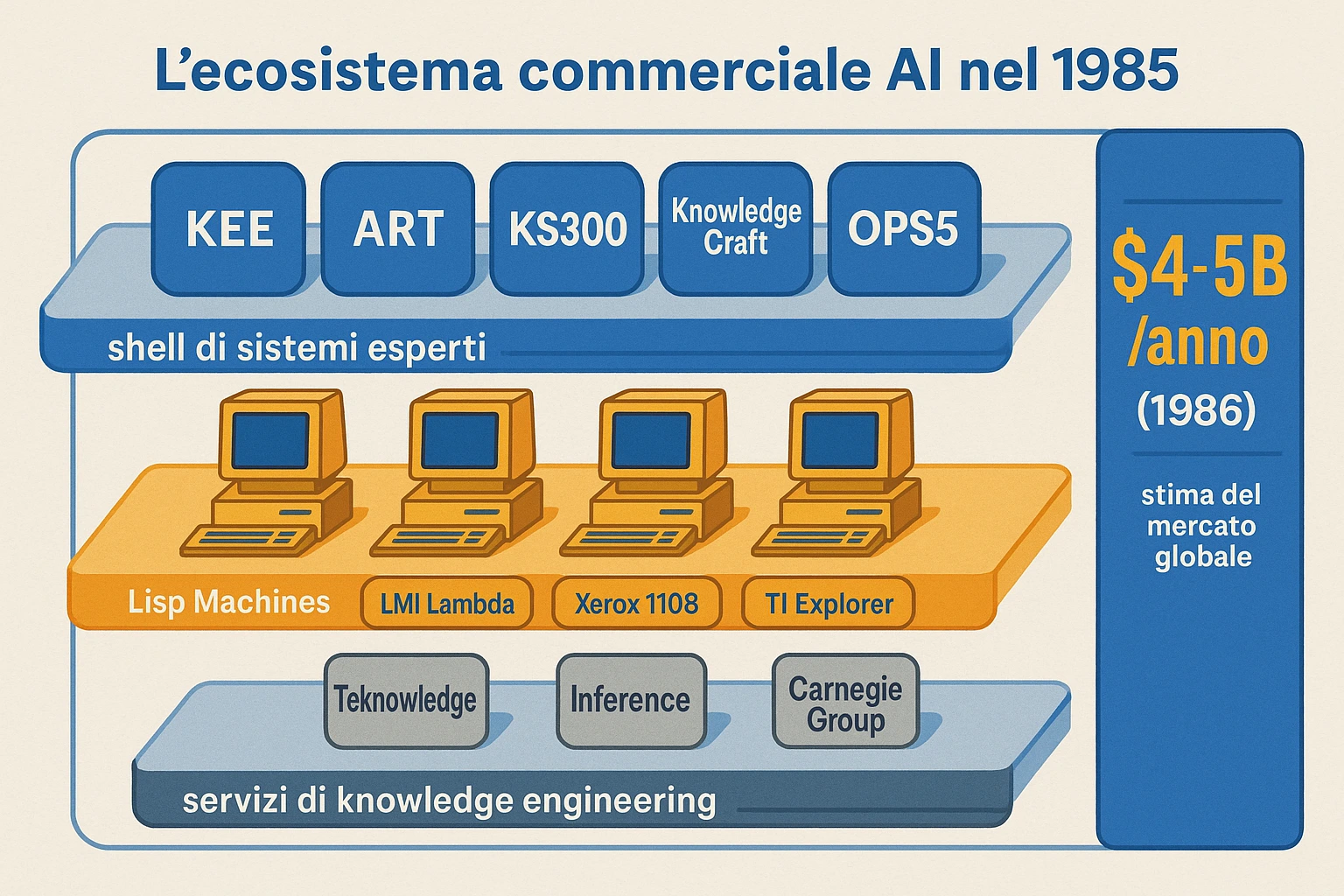
Sezione intitolata “L’industria 1980-1987”Tra il 1980 e il 1987 nasce un’intera industria intorno ai sistemi esperti. Le aziende principali:
- IntelliCorp (1980, Menlo Park, spin-off Stanford). Prodotto: KEE (Knowledge Engineering Environment), expert system shell con frames + rules + GUI su Lisp Machines. Cliente tipico: Fortune 500 in finanza, manifattura, difesa.
- Inference Corporation (1979, Los Angeles). Prodotto: ART (Automated Reasoning Tool), shell competitor di KEE.
- Teknowledge (1981, Palo Alto, spin-off Stanford). Prodotto: KS300 (basato su E-MYCIN), poi M.4. Servizi di knowledge engineering.
- Carnegie Group (1983, Pittsburgh, spin-off CMU). Prodotto: Knowledge Craft.
- Symbolics (1980, MIT spin-off, Cambridge MA). Hardware: Lisp Machines. Le loro workstation 3600 series e Ivory series, dedicate all’esecuzione veloce di Lisp, costavano tra 50.000 e 200.000 dollari ed erano la piattaforma standard per i sistemi esperti seri.
- Lisp Machines Inc (LMI, 1979, MIT spin-off). Concorrente di Symbolics con hardware analogo.
Il mercato totale dei sistemi esperti nel 1986-87 era stimato intorno a 4-5 miliardi di dollari annui, considerando hardware Lisp Machines, software shell, servizi di consulenza. Per il contesto: un mercato sostanziale, comparabile (in dollari nominali) a una mid-cap industry. Il fatto che si tratti di una bolla diventerà chiaro solo dopo.
A questa lista commerciale va aggiunto CLIPS (C Language Integrated Production System), sviluppato dalla NASA al Johnson Space Center a partire dal 1985 in risposta al fatto che i sistemi commerciali erano costosi e proprietari. CLIPS è open source dal 1996 ed è ancora attivo nel 2026. È la prova vivente che il paradigma rule-based non è morto: è diventato infrastruttura.
Linguaggi e tool
Sezione intitolata “Linguaggi e tool”I linguaggi dell’era hanno un peso storico. Lisp (John McCarthy, 1958) era il linguaggio dominante per la AI accademica statunitense; le Lisp Machines lo eseguivano nativamente in hardware. Common Lisp standardizzato nel 1984 (ANSI X3.226 nel 1994) consolida la frammentazione dei dialetti. Prolog (Alain Colmerauer e Philippe Roussel, Marsiglia 1972) è il linguaggio dominante per la AI accademica europea e per il Fifth Generation Project giapponese: programmazione logica, backward chaining built-in, unificazione come operazione primitiva. OPS5 (Forgy, CMU, 1977-1981) è il linguaggio di production rules con RETE: è quello in cui XCON è scritto. CLIPS (NASA, 1985) è il successore in C di OPS5.
La distinzione Lisp / Prolog ha anche valenza geopolitica. Negli USA i sistemi esperti commerciali sono quasi tutti su Lisp Machines (hardware + software made-in-USA). In Giappone il Fifth Generation Project punta su Prolog e su hardware parallelo dedicato all’inferenza logica. In Europa, soprattutto Francia, Regno Unito e Germania, c’è una tradizione Prolog forte (Edimburgo ha sviluppato la sintassi standard “Edinburgh Prolog”). Le scelte di linguaggio non sono solo tecniche; riflettono comunità di ricerca, finanziatori, ambizioni nazionali.
Vale anche la pena segnalare i tool di knowledge editing che accompagnano gli shell. KEE di IntelliCorp introduce un’interfaccia grafica che permette al knowledge engineer di navigare la KB come un grafo di frame e regole, di editarla visualmente, di lanciare query di test. ART di Inference Corp aggiunge un debugger di regole con breakpoint sull’attivazione. Questi tool, costosissimi (una licenza KEE su Symbolics costava decine di migliaia di dollari l’anno), erano lo stato dell’arte degli IDE per AI dell’epoca. Quando la bolla scoppia, scompaiono insieme alle aziende. Ciò che resta come traccia sono i moderni rule editor di Drools e di IBM ODM, che ricalcano molte delle stesse idee in versione web e a costo enormemente più basso.
Fifth Generation Computer System Project
Sezione intitolata “Fifth Generation Computer System Project”Nel 1981 il MITI giapponese (Ministry of International Trade and Industry, oggi METI) annuncia un mega-progetto pluriennale: il Fifth Generation Computer System Project (FGCS, 1981-1992). Budget previsto: circa 57 miliardi di yen in dieci anni (a tassi di cambio dell’epoca, qualcosa nell’ordine di 400-850 milioni di dollari, a seconda del periodo). Direzione: ICOT (Institute for New Generation Computer Technology), guidato da Kazuhiro Fuchi.
Obiettivo dichiarato: costruire una nuova generazione di computer basati su programmazione logica concorrente, con hardware parallelo dedicato all’esecuzione di Prolog, knowledge bases massive, interfacce in linguaggio naturale. La promessa era una macchina che avrebbe “ragionato” alla velocità di centinaia di milioni di logical inferences per second (LIPS), e che avrebbe portato il Giappone alla leadership mondiale nell’AI commerciale.
La reazione occidentale è allarmata. Negli USA Edward Feigenbaum e Pamela McCorduck pubblicano nel 1983 il libro “The Fifth Generation: Artificial Intelligence and Japan’s Computer Challenge to the World” (Addison-Wesley), che agita lo spettro di un sorpasso giapponese. La risposta istituzionale è rapida: MCC (Microelectronics and Computer Technology Corporation) viene fondata negli USA nel 1983 come consorzio industriale di ricerca pre-competitiva. Nel Regno Unito parte l’Alvey Programme (1983-1990). In Europa parte ESPRIT.
L’esito del FGCS è didatticamente prezioso: non riesce in nessuno dei suoi obiettivi principali. L’hardware parallelo dedicato a Prolog viene costruito ma non raggiunge le performance promesse, soprattutto perché le workstation Unix con CPU general-purpose stanno crescendo più in fretta. Le knowledge bases massive non emergono. L’interfaccia in linguaggio naturale resta elusiva. Nel 1992 il progetto chiude ufficialmente; il New York Times (Andrew Pollack, 5 giugno 1992) titola “‘Fifth Generation’ Became Japan’s Lost Generation”.
L’eredità tecnica diretta del FGCS è modesta. Qualche contributo a programmazione logica concorrente (Concurrent Prolog, KL1), qualche idea su parallel inference. Indirettamente, MCC e Alvey (le risposte occidentali) hanno prodotto più risultati del FGCS stesso. La lezione è un classico studio di caso: megaprogetto top-down con obiettivi sbagliati. La scelta di puntare tutto su programmazione logica come paradigma di ragionamento è risultata, in retrospettiva, una scommessa persa: il futuro era (ed è) statistico, non logico.
Esempio 1 — Una regola MYCIN per meningite
Sezione intitolata “Esempio 1 — Una regola MYCIN per meningite”Ricostruiamo una regola realistica nel formalismo MYCIN, leggermente semplificata. Il dominio è diagnosi di meningite batterica. Il goal corrente che MYCIN sta cercando di concludere è “qual è l’organismo causale dell’infezione?”.
RULE 543:IF the site of the culture is csf AND the gram stain of the organism is gramneg AND the morphology of the organism is rod AND the patient is a compromised hostTHEN there is suggestive evidence (CF 0.6) that the identity of the organism is pseudomonas-aeruginosaIn parole povere: se l’organismo viene da liquido cerebro-spinale (CSF), è Gram-negativo, ha morfologia a bastoncello, e il paziente è immunocompromesso, allora c’è evidenza moderata-forte che l’organismo sia Pseudomonas aeruginosa. Il certainty factor 0.6 dice “forte ma non certa”.
Quando MYCIN attiva questa regola, due cose succedono. Primo: aggiunge il fatto “organism = pseudomonas-aeruginosa” alla working memory con CF 0.6 (eventualmente da combinare con CF da altre regole che concludono la stessa cosa). Secondo: traccia nel proof tree quale regola ha applicato e su quali fatti, in modo che il modulo di explanation possa rispondere a un eventuale “WHY did you conclude pseudomonas?” del medico.
Backward chaining in azione: per applicare R543 MYCIN deve sapere il sito della coltura (Gram stain, morfologia, immunostatus). Se non li sa, li chiede al medico una alla volta: “What is the site of the culture?” “What is the gram stain of the organism?” eccetera. Se il medico risponde “unknown” a una domanda chiave, MYCIN passa ad altre regole, oppure conclude con CF basso.
Esempio 2 — Configurazione VAX semplificata
Sezione intitolata “Esempio 2 — Configurazione VAX semplificata”Mostriamo una micro-versione di XCON con tre componenti e due vincoli. Il cliente ha ordinato:
- 1 CPU modello VAX-11/780.
- 1 banco di memoria 4MB.
- 1 disk drive RP06.
Le regole nel KB di XCON:
RULE C1:IF customer ordered cpu VAX-11-780THEN add to configuration: cabinet H9602 AND add to configuration: power-supply H7100
RULE C2:IF configuration includes disk-drive RP06 AND configuration does not include controller RH780THEN add to configuration: controller RH780
RULE C3:IF configuration includes controller RH780 AND configuration includes cabinet H9602 AND cabinet H9602 has fewer than 3 slots usedTHEN install controller RH780 in cabinet H9602 AND mark slot usedXCON parte con la working memory contenente i tre fatti dell’ordine. Forward chaining:
- Iterazione 1: scatta C1, aggiunge cabinet H9602 e power-supply H7100.
- Iterazione 2: scatta C2, aggiunge controller RH780.
- Iterazione 3: scatta C3, installa controller RH780 in cabinet H9602.
- Iterazione 4: nessuna nuova regola si applica, terminato.
Output: una distinta base completa di tutti i componenti necessari + dove vanno fisicamente installati. In una configurazione reale XCON girava decine di migliaia di iterazioni per ordini complessi, applicando regole per ogni famiglia di componente. Il knowledge engineer DEC doveva mantenere migliaia di regole simili, ognuna corrispondente a un vincolo di compatibilità o a una raccomandazione di installazione.
Esempio 3 — Knowledge acquisition fail
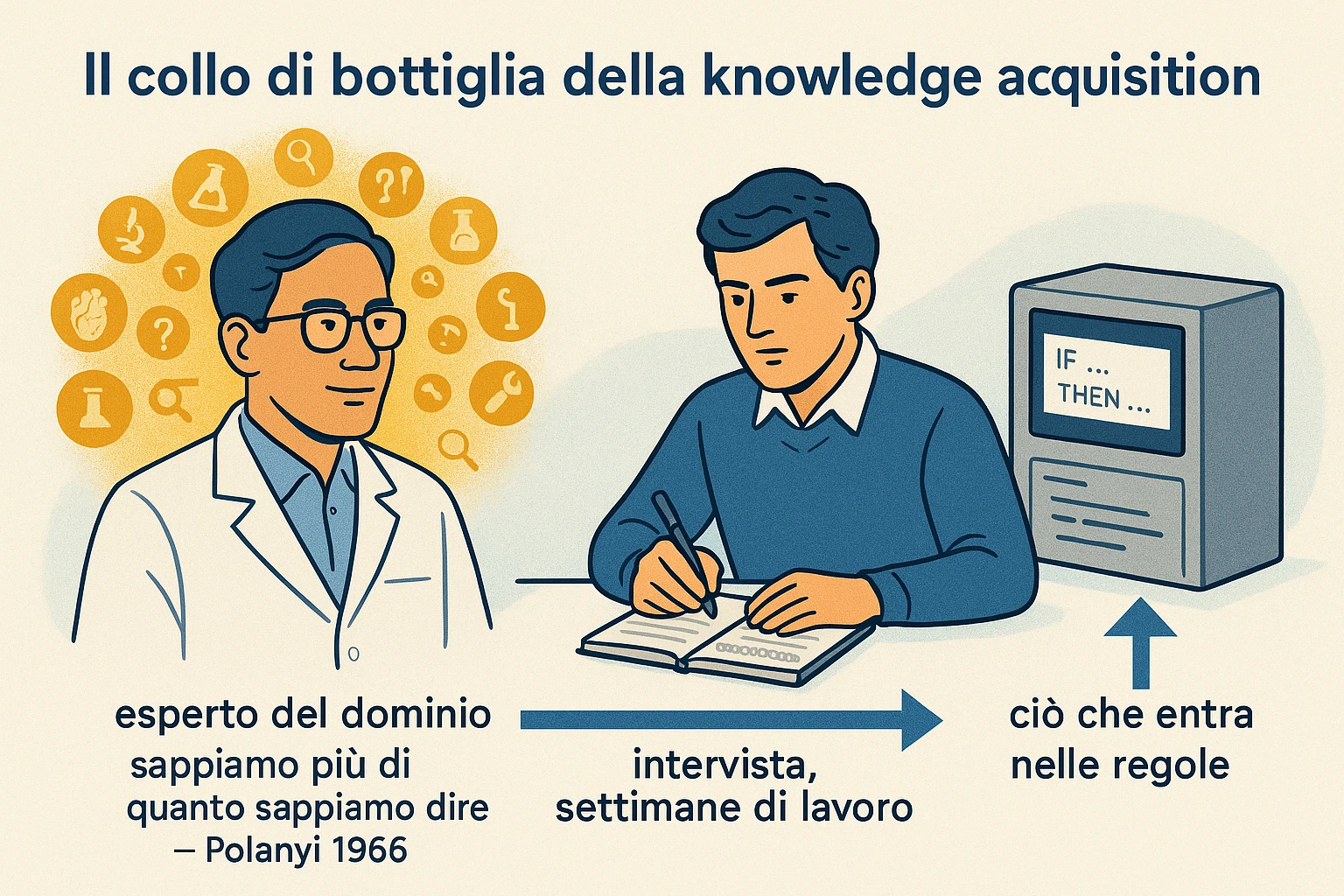
Sezione intitolata “Esempio 3 — Knowledge acquisition fail”Il pattern più doloroso del knowledge engineering. Scenario: il knowledge engineer (KE) intervista il medico esperto (l’informant) per estrarre regole su una diagnosi specifica.
KE: “Dottoressa, quando vede un paziente con febbre alta, rigidita nucale e cefalea, cosa pensa per prima cosa?”
Medico: “Penso meningite. Va trattato subito.”
KE: “Bene. Allora codifichiamo: SE febbre alta E rigidita nucale E cefalea ALLORA meningite. CF 0.9. Va bene?”
Medico: “Beh, dipende. Se il paziente è giovane e ha appena viaggiato, penso anche encefalite virale. Se è anziano e ha tumore noto, penso meningite carcinomatosa. Se è immunocompromesso, penso anche fungina.”
KE: “OK, aggiungo regole per ciascun caso. Quando dice ‘giovane’, che eta intende?”
Medico: “Eh, dipende. Sotto i 40, di solito. Ma anche un 50enne sportivo che torna dall’Africa potrebbe rientrare. È una questione di gestalt clinica.”
Il punto. Il medico esperto ha una conoscenza tacita che non si riduce a regole esplicite. Sa “a colpo d’occhio” cosa pensare, ma quando il KE le chiede di esplicitare la regola, scopre che la regola ha decine di eccezioni, di sfumature, di “dipende dal contesto”, di gestalt non articolabili. Il filosofo della scienza Michael Polanyi (1891-1976) aveva chiamato questo fenomeno tacit knowledge: “we know more than we can tell” (in “The Tacit Dimension”, 1966). Una porzione della competenza esperta esiste solo come riconoscimento di pattern incarnato nell’esperto, e si perde quando si tenta di trascriverla in regole.
È il knowledge acquisition bottleneck in forma concentrata. Estrarre regole da un esperto è lento, costoso, e produce sempre una caricatura della sua competenza. Una regola scritta da un KE in un giorno richiede settimane di interviste e iterazioni per essere validata. Una KB di 600 regole richiede anni di lavoro full-time. E quando l’esperto cambia idea (perché c’è nuova letteratura medica), tutta la KB deve essere rivista. La scalabilità umana del paradigma è intrinsecamente limitata.
Applicazioni pratiche
Sezione intitolata “Applicazioni pratiche”L’eredità dei sistemi esperti non è un museo. Continua a operare oggi, in forme spesso non riconosciute.
Business Rules Engines (BRE). Drools (open source, Red Hat / IBM, basato su una variante di RETE), IBM Operational Decision Manager (ex iLog JRules), Red Hat Decision Manager. Sono expert system shell moderni applicati a logica di business: pricing dinamico in e-commerce, risk scoring in banche, compliance check in assicurazioni, fraud detection in carte di credito. Quando una banca ti dice “la tua transazione è stata rifiutata per ragioni di rischio”, spesso sotto c’è una regola scritta in Drools da un risk officer che non conosce nemmeno il termine “expert system”. L’algoritmo RETE di Forgy gira ancora oggi su miliardi di transazioni l’ora.
Decision support medico. UpToDate (acquisita da Wolters Kluwer) è una knowledge base curata di raccomandazioni cliniche evidence-based, consultata da milioni di medici nel mondo. Isabel (Isabel Healthcare) è un differential diagnosis assistant. Non sono pure rule-based — usano oggi anche tecniche statistiche e LLM per interfaccia — ma ereditano direttamente il paradigma “knowledge curation + ragionamento al letto del paziente” che MYCIN aveva inaugurato. La differenza chiave: hanno risolto il problema dell’integrazione (sono dentro la cartella clinica elettronica) e il problema legale (non sostituiscono il medico, lo informano).
CLIPS della NASA, sviluppato dal 1985, è ancora attivo. Usato in applicazioni embedded di rule-based reasoning, in didattica universitaria, in sistemi di controllo per veicoli autonomi e per la International Space Station. È la prova che il paradigma rule-based, nel suo contesto giusto (regole esplicite, dominio chiuso, garanzie di tracciabilità), non ha sostituti.
Cyc di Doug Lenat (informatico statunitense, 1950-2023). Lenat fonda Cycorp nel 1984 con l’obiettivo di codificare a mano milioni di assiomi di common sense knowledge (i liquidi cadono, gli oggetti continuano a esistere quando non li guardi, la gente non passa attraverso i muri). È il tentativo più ambizioso di scalare il paradigma knowledge-based al common sense generale. Dopo quasi 40 anni di lavoro, Cyc resta inferiore in flessibilità ai LLM moderni che hanno “imparato” common sense statisticamente da terabyte di testo. Cycorp chiude nel 2023; Lenat muore lo stesso anno. È un caso di studio del limite del paradigma simbolico applicato al common sense.
RAG come “expert system 2.0”. L’analogia va maneggiata con cura. Sia un sistema RAG sia un expert system separano “conoscenza” (KB di documenti vs KB di regole) da “ragionatore” (LLM generatore vs inference engine). Sia RAG sia ES hanno il problema della knowledge curation (selezionare cosa includere, mantenere aggiornato il corpus, evitare contraddizioni). Le differenze tecniche sono profonde. RAG usa similarity search (continua, soft, basata su embedding) invece di pattern matching (discreta, hard). RAG non ha forward/backward chaining esplicito: il LLM “ragiona” in modo opaco. RAG non ha un explanation module nativo: la chain-of-thought generata è al massimo una post-hoc rationalization. L’analogia è utile per insegnare ma tecnicamente debole.
Ciò nondimeno, c’è una continuita filosofica forte. Quando oggi parliamo di context engineering per un agente — selezionare quali documenti, quali tool, quali esempi few-shot mettere nel context window per massimizzare la performance del LLM su un task specifico — stiamo facendo un’attività strutturalmente simile al knowledge engineering del 1980. Selezioniamo conoscenza pertinente, la organizziamo in forma utilizzabile dal ragionatore, valutiamo iterativamente. L’unita di conoscenza è diversa (non più regole IF-THEN, ma documenti o esempi); l’attività umana è la stessa.
Hybrid neuro-simbolico. Wolfram Alpha + LLM (Stephen Wolfram l’ha proposto pubblicamente nel 2023), OpenAI con tool use, Claude con MCP (Model Context Protocol, 2024). L’idea ricorrente: il LLM è bravo a parlare e a interfacciare ma sbaglia su fatti precisi e su catene di ragionamento lunghe; il sistema simbolico (calcolatore, KB, solver SAT) garantisce correttezza nel suo dominio ristretto; la combinazione è più robusta di entrambi separati. È una rivendicazione parziale del paradigma simbolico, in versione subordinata e modulare invece che dominante.
Dove si rompe
Sezione intitolata “Dove si rompe”Il knowledge acquisition bottleneck
Sezione intitolata “Il knowledge acquisition bottleneck”Il limite più profondo del paradigma. Estrarre regole da esperti umani è un’attività lenta, costosa, e fondamentalmente limitata da ciò che l’esperto può articolare. Polanyi 1966 lo aveva diagnosticato in chiave filosofica: we know more than we can tell. Una porzione della competenza esperta è tacita, gestaltica, non riducibile a regole esplicite enumerabili. Il knowledge engineer può solo catturare la parte articolabile, e produce inevitabilmente una caricatura della competenza.
In termini economici: una KB seria (qualche centinaio di regole) richiede anni-uomo di knowledge engineer + esperto. Per dominio. E quando il dominio cambia (nuova letteratura medica, nuovo catalogo prodotti) la KB va revisionata. La scalabilità umana è intrinseca. Negli anni Ottanta si sperava in tool di automazione (Meta-DENDRAL, ROGET di van Melle, induzione di regole da casi); nessuno ha funzionato bene abbastanza.
Brittleness e zero common sense
Sezione intitolata “Brittleness e zero common sense”Un sistema esperto è brittle: funziona bene sui casi previsti dalla KB, fallisce in modi spesso silenziosi sui casi non previsti. Un MYCIN a cui chiedi una diagnosi pediatrica risponde con regole calibrate sull’adulto, senza accorgersi della mancata applicabilita. Un XCON a cui dai un componente non in catalogo va in errore o produce configurazioni assurde, senza riconoscere che è fuori dominio.
L’origine della brittleness è l’assenza di common sense reasoning sul mondo aperto. Un essere umano sa che un paziente di 6 mesi è diverso da uno di 60 anni in molti modi non scritti nelle regole; il sistema esperto sa solo ciò che è nelle regole. Il fallimento non è “lascia il problema irrisolto”: è “produce risposte sbagliate con apparente sicurezza”.
La patologia “il sistema non sa di non sapere” non è specifica del paradigma simbolico: ricompare, in forma analoga, in qualunque sistema che non abbia un meccanismo esplicito di abstention. Le forme contemporanee del problema (hallucinations, output assertivi su contenuto fabbricato) sono trattate in “Applicazioni pratiche”.
Maintenance explosion
Sezione intitolata “Maintenance explosion”Il caso XCON è paradigmatico. Mantenere una KB cresce in difficoltà in modo super-lineare con il numero di regole. Non solo per il volume (8000 regole sono fisicamente tante da rivedere), ma soprattutto per le interazioni: una regola nuova può entrare in conflitto con regole esistenti in modi non ovvi, generando comportamenti emergent indesiderati. La “regression testing” su una KB di rule-based richiede di rieseguire tutti i casi storici dopo ogni modifica.
Il team di knowledge engineer di DEC (~50 persone) era essenzialmente un team di manutenzione software con caratteristiche peculiari. Quando il paradigma è uscito di moda, queste persone hanno avuto difficoltà a riconvertirsi: knowledge engineering era una skill specifica che non si traduceva facilmente in altre forme di software engineering.
Nessun apprendimento
Sezione intitolata “Nessun apprendimento”I sistemi esperti classici non imparano. Una KB è fissa, modificata solo da knowledge engineer umani. Non c’è adattamento ai nuovi casi, non c’è drift detection, non c’è online learning. Meta-DENDRAL fu un tentativo isolato in questa direzione e non si generalizzo.
È un limite enorme. Qualunque dominio reale evolve: nuove patologie, nuovi prodotti, nuovi pattern di frode. Un sistema esperto fissato al 1985 è un fossile nel 1995. Confrontalo con un sistema ML moderno, che almeno in linea di principio può essere riaddestrato su nuovi dati con relativa facilita.
Hardware Lisp Machines: scommessa persa
Sezione intitolata “Hardware Lisp Machines: scommessa persa”Le Lisp Machines (Symbolics, LMI, Xerox 1108, TI Explorer) erano workstation specializzate, ottimizzate per eseguire Lisp veloce in hardware. Negli anni 1980-86 sembravano la piattaforma giusta per la AI seria: $50-200K a unita, performance superiori a workstation general-purpose dell’epoca. Erano lo status symbol del laboratorio AI ben finanziato.
A meta degli anni Ottanta accade qualcosa che i fondatori non avevano previsto. Le workstation Unix (Sun Microsystems, Apollo, MIPS) crescono in performance più velocemente delle Lisp Machines, costano meno (10-20K), e con la standardizzazione di Common Lisp nel 1984 possono eseguire Lisp ad accettabile velocità. Il vantaggio hardware delle Lisp Machines svanisce in pochi anni. Symbolics, che aveva avuto un picco di revenue intorno a $110 milioni nel 1986, va in bancarotta tecnica nel 1987 e sopravvive come ombra fino al 1996. LMI muore prima.
È una lezione classica di disruptive innovation: una piattaforma specializzata viene mangiata da una piattaforma general-purpose che cresce più in fretta. La parallela storica con le GPU vs ASIC dell’AI moderna (Nvidia vs Google TPU vs Cerebras vs Groq) è ovvia. Quando la performance general-purpose è “abbastanza”, la specializzazione hardware perde il suo vantaggio.
Hype-and-bust e secondo inverno
Sezione intitolata “Hype-and-bust e secondo inverno”Il mercato dei sistemi esperti tra il 1983 e il 1986 ha vissuto una bolla hype simile a quelle che oggi conosciamo bene. Magazine come BusinessWeek, Fortune, Newsweek pubblicavano cover stories sull’AI che avrebbe rivoluzionato ogni industria. Aziende lanciavano “AI initiatives” senza capire cosa stavano facendo. Consulenti vendevano expert system shell a clienti che poi non sapevano riempire la KB. La frase canonica “we need to do AI” risuonava nelle salete di consigli di amministrazione di aziende manifatturiere, finanziarie, farmaceutiche, senza che nessuno avesse mappato un caso d’uso concreto.
Quando i clienti hanno cominciato a vedere che (1) costruire una KB seria costava molto più del previsto, spesso 2-5 volte il preventivo iniziale, (2) la manutenzione era un incubo che cresceva con il numero di regole, (3) la performance in produzione spesso non valeva l’investimento, (4) i sistemi installati invecchiavano male perché non apprendevano dai nuovi casi — la fiducia è crollata in fretta. Tipico ciclo: pilot di sei mesi che funziona, deployment di un anno che scala male, secondo anno in cui i costi di manutenzione superano i benefici, terzo anno in cui il sistema viene silenziosamente decommissionato.
Il secondo inverno dell’AI parte intorno al 1987-1990 con il crollo di Symbolics, il ridimensionamento di IntelliCorp e Teknowledge, la chiusura di molte AI initiative aziendali. La parola “AI” diventa di nuovo un marker di hype eccessivo. Per un decennio (1990-2000 circa) chi faceva AI seria preferiva chiamarla “machine learning”, “data mining”, “knowledge management”, “intelligent systems”, “decision support”. Il dettaglio del crollo, delle sue cause specifiche, e delle ripercussioni accademiche e industriali sarà nel capitolo [secondo-inverno-ai].
Il pattern “azienda lancia AI initiative senza caso d’uso, spende milioni, decommissiona dopo due anni” non è nato negli anni Ottanta: è il primo grande caso di studio documentato di questo ciclo, che si ripete a ogni nuova ondata. Le lezioni operative — scegliere casi d’uso narrow con metriche concrete, separare R&D da produzione, evitare di scalare prima di aver validato — sono nei case study di quell’epoca, e sono riproponibili a ogni replica.
Mito da sfatare: MYCIN nella clinica
Sezione intitolata “Mito da sfatare: MYCIN nella clinica”Periodicamente in articoli divulgativi compare l’affermazione che MYCIN sia stato deployato in ospedale. È falso. MYCIN ha prodotto solo studi accademici di valutazione. Nessun ospedale lo ha mai usato per diagnosticare un paziente vero. Le ragioni — legali, pratiche, istituzionali — sono spiegate nella sezione su MYCIN sopra. La leggenda nasce probabilmente dalla confusione tra “sistema funzionante in laboratorio” e “sistema in uso clinico”. È una distinzione importante. Vale anche oggi per qualunque AI medicale: passare da paper benchmark a deployment ospedaliero richiede un ordine di magnitudo in più di lavoro, e questo lavoro è spesso non tecnico.
Collegamenti
Sezione intitolata “Collegamenti”- primo-inverno-ai — i sistemi esperti sono la risposta pragmatica all’inverno: rinuncia all’AGI in cambio di domini ristretti redditizi. Capire le cause del primo inverno spiega il pivot di Feigenbaum.
- ai-simbolica-anni-60 — l’eredità tecnica diretta. Le production rules vengono dal lavoro di Newell e Simon sui production systems; l’inference engine è un discendente del General Problem Solver; l’idea di separare conoscenza e controllo nasce qui.
- dartmouth-1956 — Feigenbaum era stato studente di Simon a Carnegie Tech. La traiettoria personale del pivot inizia a Dartmouth.
- secondo-inverno-ai (Parte I, futuro) — il crollo 1987-1993 è direttamente causato dai limiti dei sistemi esperti che emergono in produzione. Senza capire i sistemi esperti, il secondo inverno sembra incomprensibile.
- rinascita-statistica-90 (Parte I, futuro) — la reazione tecnica al fallimento del paradigma simbolico-rule-based è lo spostamento verso metodi statistici e probabilistici (HMM, reti bayesiane, ML statistico).
- sistemi-esperti-dettaglio (Parte VII, futuro) — approfondimento tecnico sull’algoritmo RETE, sui frames di Minsky, sulle description logics. Qui abbiamo dato la storia; li la meccanica avanzata.
- bayesian-networks (Parte VII, futuro) — Pearl 1988 risolve in modo principled il problema dell’incertezza che i certainty factors di MYCIN risolvevano in modo ad hoc. Continuita storica diretta.
- rappresentazione-conoscenza (Parte VII, futuro) — frames, semantic networks, description logics, ontologie: lo zoo della knowledge representation che esplode negli anni Ottanta intorno ai sistemi esperti.
- rag-base (Parte XIV, futuro) — KB di documenti + LLM come ragionatore è una rilettura del paradigma KB + inference engine, con embedding al posto di pattern matching. Analogia da maneggiare con cura ma utile.
- knowledge-graph (Parte XIV, futuro) — DBpedia, Wikidata, knowledge graph aziendali ereditano dalla tradizione dei semantic networks degli anni Settanta-Ottanta.
- mcp-introduzione (Parte XVI, futuro) — il Model Context Protocol modularizza tool e contesto in modo che richiama la separazione knowledge / control dei sistemi esperti, in scala diversa.
Per andare oltre
Sezione intitolata “Per andare oltre”- Buchanan, Bruce G. & Shortliffe, Edward H. (eds.). “Rule-Based Expert Systems: The MYCIN Experiments of the Stanford Heuristic Programming Project”. Addison-Wesley, 1984. Il libro definitivo sul progetto MYCIN, scritto dai protagonisti. Contiene architettura, esempi di regole, valutazioni, riflessioni sui limiti. Lettura obbligatoria per chi vuole capire il paradigma dall’interno.
- McDermott, John P. “R1: A Rule-Based Configurer of Computer Systems”. Artificial Intelligence, vol. 19, n. 1, 1982, pp. 39-88. Paper originale di XCON. Mostra come si scrive un sistema esperto industriale, con metriche e architettura.
- Hayes-Roth, Frederick; Waterman, Donald A.; Lenat, Douglas B. (eds.). “Building Expert Systems”. Addison-Wesley, 1983. Manuale collettivo dell’epoca, snapshot dello stato dell’arte prima del crollo. Capitoli su architettura, knowledge engineering, case study. La “bibbia” dell’era.
- Feigenbaum, Edward A. & Feldman, Julian (eds.). “Computers and Thought”. McGraw-Hill, 1963. Antologia che precede l’era dei sistemi esperti ma contiene il framing intellettuale che Feigenbaum svilupperà negli anni successivi. Ottimo per il contesto storico.
- Russell, Stuart & Norvig, Peter. “Artificial Intelligence: A Modern Approach”, 4a ed. Pearson, 2020. La sezione storica del capitolo 1 e i capitoli su knowledge representation coprono brevemente ma autorevolmente l’era. AIMA è il riferimento standard moderno.
- Crevier, Daniel. “AI: The Tumultuous History of the Search for Artificial Intelligence”. Basic Books, 1993. Storia dell’AI dal Dartmouth Workshop agli anni Novanta, con interviste dirette ai protagonisti. Capitoli 6-8 coprono l’era dei sistemi esperti in modo narrativo e accessibile.