Sequence to Sequence 2014: una sequenza dentro, una sequenza fuori
BLEU 34.81 contro 33.30 della migliore SMT del 2014. Un punto e mezzo di BLEU che, su un benchmark dove di solito si conquistano frazioni di punto, sposta il paradigma della traduzione automatica per un decennio. Due LSTM impilate, una grande quantità di dati paralleli, nessuna conoscenza linguistica programmata: la pipeline classica della traduzione statistica perde il primato in un singolo paper di nove pagine.
Perché questo capitolo
Sezione intitolata “Perché questo capitolo”C’è una scena ricorrente nei talk di Ilya Sutskever quando racconta il lavoro su seq2seq: il momento in cui il team prova a invertire l’ordine delle parole nella frase sorgente, “expecting nothing”, e si trova in mano cinque punti di BLEU in più. Nessuno aveva previsto l’effetto, nessuno aveva una teoria pulita per spiegarlo a priori. Era un esperimento empirico fatto quasi per esclusione, e quel guadagno fu sufficiente a cambiare l’esito del confronto con il sistema statistico che fino a poche settimane prima sembrava intoccabile. Il dettaglio aneddotico dice già molto sul carattere del paper di Sutskever, Vinyals e Le del 2014: una combinazione di intuizione architetturale audace e di trick ingegneristici scoperti facendo girare gli esperimenti, non derivati da una teoria.
Il secondo motivo per cui il capitolo conta è di lunga gittata. Prima del 2014, il paradigma dominante per la traduzione automatica era la Statistical Machine Translation (SMT, traduzione automatica statistica): pipeline a più stadi, allineamenti probabilistici di parole e frasi, modelli di linguaggio n-gram, decoder a feature lineari combinate con pesi appresi su validation set. Il toolkit Moses, rilasciato nel 2007, era lo standard accademico e industriale. Vent’anni di lavoro accumulato. Seq2seq non aggiunge un pezzo alla pipeline: ne propone una sostituzione completa con una sola architettura end-to-end, due reti ricorrenti che leggono e scrivono token. La filiazione che parte da qui — passando per attention, GNMT, transformer, BERT, GPT — è una linea quasi continua di evoluzioni che usano e ridiscutono la stessa intuizione di base: si può imparare una mappatura tra sequenze di lunghezza qualunque addestrando reti grandi su tante coppie input-output, senza programmare a mano la struttura del problema.
C’è un terzo motivo, lessicale. Dopo seq2seq il termine “sequence to sequence” entra nel vocabolario operativo di chi fa NLP, parlato come se fosse stato sempre li’. Si parla di seq2seq per traduzione, per summarization, per generazione di codice, per question answering, per speech recognition, per image captioning. Il pattern encoder-decoder — comprimi l’input in una rappresentazione, espandi la rappresentazione in un output — diventa una forma a-disposizione che si applica ben oltre il task di traduzione che l’ha originato. Persino i modelli decoder-only contemporanei ereditano il vocabolario della distinzione: si parla ancora di “encoder-only”, “decoder-only”, “encoder-decoder” come tre famiglie architetturali, e la coppia di termini nasce qui.
Contesto
Sezione intitolata “Contesto”Il filo arriva da due capitoli paralleli. Da reti-neurali-80-90 ricordiamo le LSTM (Long Short-Term Memory, una variante di rete neurale ricorrente con gating interno), introdotte nel 1997 da Sepp Hochreiter (informatico austriaco, 1967-) e Jurgen Schmidhuber (informatico tedesco, 1963-, direttore del laboratorio IDSIA di Lugano) sul Neural Computation con il paper omonimo “Long Short-Term Memory”. L’LSTM risolve il problema del vanishing gradient che affliggeva le RNN classiche: in una rete ricorrente normale, addestrata via backpropagation through time, il gradiente che si propaga indietro lungo molti passi temporali tende a svanire (o esplodere), rendendo impossibile apprendere dipendenze lunghe. Le LSTM aggiungono una cell state che scorre quasi linearmente nel tempo, modulata da gate moltiplicativi (input gate, forget gate, output gate) che decidono cosa scrivere, cosa cancellare, cosa leggere. Tra il 1997 e il 2013 le LSTM restano una nicchia, usate principalmente da Schmidhuber e collaboratori per riconoscimento di handwriting e speech. Solo dopo il 2012-2013, con l’esplosione del deep learning post-AlexNet, vengono adottate massivamente come componente di linguaggio.
Da word2vec-2013 ricordiamo invece l’idea che le parole si possano rappresentare come vettori densi in uno spazio continuo, e che quei vettori catturino regolarita semantiche utili per task downstream. Word2vec produce embedding statici: ogni parola ha un vettore fissato dopo l’addestramento. Seq2seq usera embedding di parola simili come livello di input, ma sopra ci impila reti ricorrenti che producono rappresentazioni contestuali: lo stato nascosto dell’LSTM dipende non solo dalla parola corrente ma da tutta la storia di parole vista fino a quel punto.
Il paradigma con cui seq2seq si confronta nel 2014 è la Statistical Machine Translation. Le sue radici tecniche risalgono ai cinque “IBM models” pubblicati tra il 1988 e il 1993 da Peter Brown, Stephen Della Pietra, Vincent Della Pietra, Robert Mercer e collaboratori a IBM Research, in particolare nel paper “The Mathematics of Statistical Machine Translation” sul Computational Linguistics nel 1993. L’idea: trattare la traduzione come un problema di decoding bayesiano. Data una frase sorgente, scegli la frase target che massimizza la probabilità posteriore, fattorizzata in un translation model (probabilità’ della sorgente data la target, appresa da corpora paralleli) e un language model (probabilità della target nella lingua target). Negli anni 2000 il paradigma dominante diventa il phrase-based MT di Philipp Koehn, Franz Josef Och e altri (paper di riferimento “Statistical Phrase-Based Translation”, NAACL 2003): invece di allineare parole singole, si allineano sequenze contigue di parole (frasi non sintattiche). Il toolkit Moses (Koehn et al. 2007) è lo strumento di riferimento: training pipeline, decoder beam-search, supporto a feature multiple combinate con un modello log-lineare. Per anni i miglioramenti incrementali erano frazioni di punto BLEU sui benchmark WMT.
Il primo paper che propone componenti neurali dentro questa pipeline esce nel giugno 2014, qualche mese prima di seq2seq. Kyunghyun Cho (informatico sudcoreano, allora postdoc a Montreal sotto Bengio), Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau (informatico bielorusso), Fethi Bougares, Holger Schwenk e Yoshua Bengio pubblicano “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation” su arXiv (poi a EMNLP 2014, arXiv:1406.1078). Il paper introduce la Gated Recurrent Unit (GRU), una variante semplificata dell’LSTM con due gate invece di tre, e propone un’architettura encoder-decoder ricorrente per produrre score di traduzione di phrase pair, integrati come feature aggiuntiva dentro la pipeline Moses. Non sostituisce SMT: la affianca. Il modello neurale produce un segnale, il decoder log-lineare lo combina con feature classiche.
Tre mesi dopo, a settembre 2014, Ilya Sutskever (informatico russo-canadese-israeliano, 1986-, allora a Google Brain dopo il PhD a Toronto sotto Hinton, già co-autore di AlexNet 2012, futuro co-fondatore di OpenAI nel 2015), Oriol Vinyals (informatico catalano, 1983-, PhD a Berkeley, a Google Brain dal 2013, futuro researcher a DeepMind con lavori come Show and Tell, Pointer Networks, AlphaStar) e Quoc V. Le (informatico vietnamita-americano, PhD a Stanford con Andrew Ng, a Google Brain dal 2011) pubblicano “Sequence to Sequence Learning with Neural Networks” (NIPS 2014, arXiv:1409.3215). La differenza rispetto a Cho et al. è chirurgica: il paper afferma e dimostra che si può fare traduzione end-to-end con sole reti neurali, senza nessuna pipeline classica accanto. La traduzione esce direttamente dal decoder LSTM, parola per parola, addestrato a massimizzare la probabilità’ della frase target dato l’intera frase sorgente.

Praticamente in contemporanea con seq2seq, nello stesso settembre 2014, esce su arXiv il paper di Dzmitry Bahdanau, Kyunghyun Cho e Yoshua Bengio intitolato “Neural Machine Translation by Jointly Learning to Align and Translate” (poi pubblicato a ICLR 2015, arXiv:1409.0473), che introduce il meccanismo di attention in NMT. Il paper di Bahdanau risolve il problema strutturale che il paper di Sutskever lascia aperto: il bottleneck del vettore di stato fisso. Il dettaglio dell’attention sarà argomento del capitolo successivo, attention-bahdanau-2014 (in preparazione). Qui basta sapere che le due idee — encoder-decoder e attention — nascono nello stesso autunno, in due gruppi diversi (Google Brain e Montreal-Jacobs), e si combineranno presto in una sintesi che reggerà la traduzione neurale fino all’arrivo del transformer nel 2017.
L’intuizione
Sezione intitolata “L’intuizione”Angolo architetturale: due reti che si parlano attraverso un vettore
Sezione intitolata “Angolo architetturale: due reti che si parlano attraverso un vettore”Pensa a seq2seq come a due persone in due stanze separate, collegate da un tubo stretto. La prima persona ha davanti la frase sorgente, la legge una parola alla volta, e ha un block-notes su cui aggiorna il riassunto della frase mano a mano che la legge. Quando arriva alla fine, prende il foglio del block-notes — un vettore di numeri reali, qualche migliaio — e lo passa attraverso il tubo. La seconda persona riceve il foglio e non vede mai la frase originale. Da quel solo foglio deve produrre la frase target, una parola alla volta, in un’altra lingua. Ogni parola che scrive viene rifilata anche nel suo block-notes interno, così la parola successiva la decide tenendo conto sia del riassunto iniziale sia di quanto ha già scritto.
La prima persona è l’encoder LSTM, la seconda è il decoder LSTM, il foglio è il vettore di stato finale dell’encoder, il tubo stretto è il bottleneck informativo che separa lettura e scrittura. Questa metafora coglie il cuore architetturale di seq2seq: due funzioni distinte (comprimere, espandere) realizzate da reti ricorrenti distinte, con un’interfaccia minima tra le due.
L’eleganza dell’idea sta nella sua generalità. Il “tubo” non assume niente sulla struttura linguistica della sorgente o della target. Non assume neanche che le due lingue siano simili. Non assume che le sequenze abbiano la stessa lunghezza. L’encoder può leggere quattordici parole in inglese, il decoder può produrre venti parole in francese, e il vettore in mezzo non ha bisogno di sapere che si trattasse di parole, di lingue, o di traduzione. La stessa architettura funzionera per generare descrizioni di immagini partendo da feature di una CNN, per trascrivere audio in caratteri, per riassumere documenti, per generare codice da specifiche.
Angolo end-to-end: nessuna pipeline, niente conoscenza linguistica programmata
Sezione intitolata “Angolo end-to-end: nessuna pipeline, niente conoscenza linguistica programmata”Il secondo angolo è di filosofia metodologica. Per quasi vent’anni, la traduzione automatica è stata un esercizio di engineering linguistico: si combinavano allineatori statistici, modelli n-gram, regole sintattiche, reordering models, lessici bilingui. Ogni componente aveva il suo paper, il suo training, i suoi iperparametri. Il decoder Moses aveva una decina di feature lineari pesate. Ogni miglioramento richiedeva di toccare il punto giusto nella catena. La conoscenza linguistica era distribuita nelle assunzioni di ogni stadio.
Seq2seq propone un opposto radicale: una sola funzione , parametrizzata da (i pesi delle due LSTM e degli embedding), addestrata direttamente a massimizzare la probabilità’ della frase target data la frase sorgente. Tutto ciò che il modello sa lo deve imparare dai dati. Nessun allineamento esplicito di parole, nessun lessico, nessun reordering model, nessuna morfologia. Le rappresentazioni intermedie sono un effetto collaterale dell’addestramento, non una scelta di progettazione.
Questa scelta non è nuova in spirito — l’idea era già in Bengio 2003 e in Collobert-Weston 2008 — ma è la prima volta che viene applicata a un task complesso come la traduzione e che produce risultati competitivi con il paradigma dominante. La filiazione tra “predire la parola successiva con una rete neurale” (Bengio 2003) e “predire una sequenza con due reti neurali” (Sutskever 2014) è diretta: stesso principio, stessa funzione di loss (cross-entropy sulla parola successiva), scala diversa. Il salto è dimostrare che la stessa idea regge a un task con output strutturato, sequenziale e di lunghezza variabile.
C’è una conseguenza filosofica che vale la pena nominare. Se l’end-to-end batte la pipeline su un task storicamente dominato dall’engineering, allora l’engineering linguistico era fondamentalmente sostituibile da scala e dati. Per molta parte della comunità di linguistica computazionale, il messaggio era difficile da accettare. Per la generazione successiva di ricercatori, divento’ la lente con cui leggere ogni problema NLP: prima prova a fare end-to-end con abbastanza dati, poi ragiona su cosa manca.
Conviene segnare anche cosa il paper non elimina. Seq2seq elimina la pipeline esplicita di SMT, ma mantiene scelte di engineering importanti: il vocabolario chiuso, il preprocessing del testo (tokenizzazione, lowercasing, gestione della punteggiatura), la scelta di iperparametri come la dimensione degli embedding, la scelta del beam size, l’inversione della sorgente. End-to-end è un termine relativo: si abbatte l’engineering linguistico esplicito, ma si introduce un nuovo strato di engineering ML (architettura, ottimizzatore, regolarizzazione). Il punto è dove sta il dominio di conoscenza richiesta: prima era nelle teste dei linguisti computazionali, dopo sta nelle teste degli ingegneri ML. Cambia il profilo di chi può costruire un sistema di traduzione, non scompare la complessità tecnica.
La meccanica
Sezione intitolata “La meccanica”Promemoria sulla LSTM come componente
Sezione intitolata “Promemoria sulla LSTM come componente”Prima di entrare nell’architettura completa, vale la pena ricordare brevemente come funziona la singola cella LSTM, perché i nomi dei suoi gate ricorrono in tutto il discorso. Una cella LSTM prende in input al passo il vettore corrente (qui l’embedding della parola), lo stato nascosto precedente e la cell state precedente , e produce nuovi e . Internamente calcola tre gate (vettori di valori in ) e un valore candidato:
- Forget gate : decide quanta parte di tenere.
- Input gate : decide quanta nuova informazione scrivere.
- Candidate : la nuova informazione potenziale.
- Output gate : decide quanta parte della cella esporre come stato nascosto.
L’aggiornamento finale della cella è (somma elemento-per-elemento con prodotti gating), e lo stato nascosto è . In parole povere, la cell state è una memoria lineare che il forget gate può azzerare e l’input gate può scrivere; il gradiente, propagandosi indietro lungo , non passa per non-linearita’ moltiplicative ripetute, ed evita di svanire. È questa la ragione per cui le LSTM possono apprendere dipendenze lunghe dove le RNN classiche falliscono.
In una LSTM stacked, l’output del layer 1 diventa l’input del layer 2 al medesimo passo temporale, quello del layer 2 diventa l’input del layer 3, e così via. Ogni layer ha i propri pesi e i propri stati. La profondita’ permette di apprendere rappresentazioni di astrazione crescente: layer bassi catturano regolarita’ lessicali e morfologiche, layer alti catturano struttura sintattica e semantica.
Encoder-decoder con LSTM
Sezione intitolata “Encoder-decoder con LSTM”L’architettura concreta del paper Sutskever-Vinyals-Le è sorprendentemente semplice da descrivere. Due reti LSTM stacked, profonde quattro layer, con 1000 unità per layer. Embedding di parole input e output di dimensione 1000. Vocabolari di circa 160000 parole sull’inglese e 80000 sul francese, con un token speciale UNK per le parole fuori vocabolario. Totale parametri: circa 384 milioni — una rete grande per l’epoca, addestrabile solo grazie a un’infrastruttura GPU multi-card.
L’encoder processa la frase sorgente token per token. Sia la sequenza di parole sorgenti. Al passo , l’LSTM encoder riceve l’embedding della parola corrente e il proprio stato precedente , e produce il nuovo stato :
Dove è lo hidden state (lo stato visibile, usato sia internamente che come output) e è la cell state (la memoria interna che scorre quasi linearmente, mediata dai gate). In parole povere, l’LSTM aggiorna a ogni passo due vettori: uno che rappresenta cosa “vede” adesso, uno che rappresenta cosa “ricorda” dal passato.
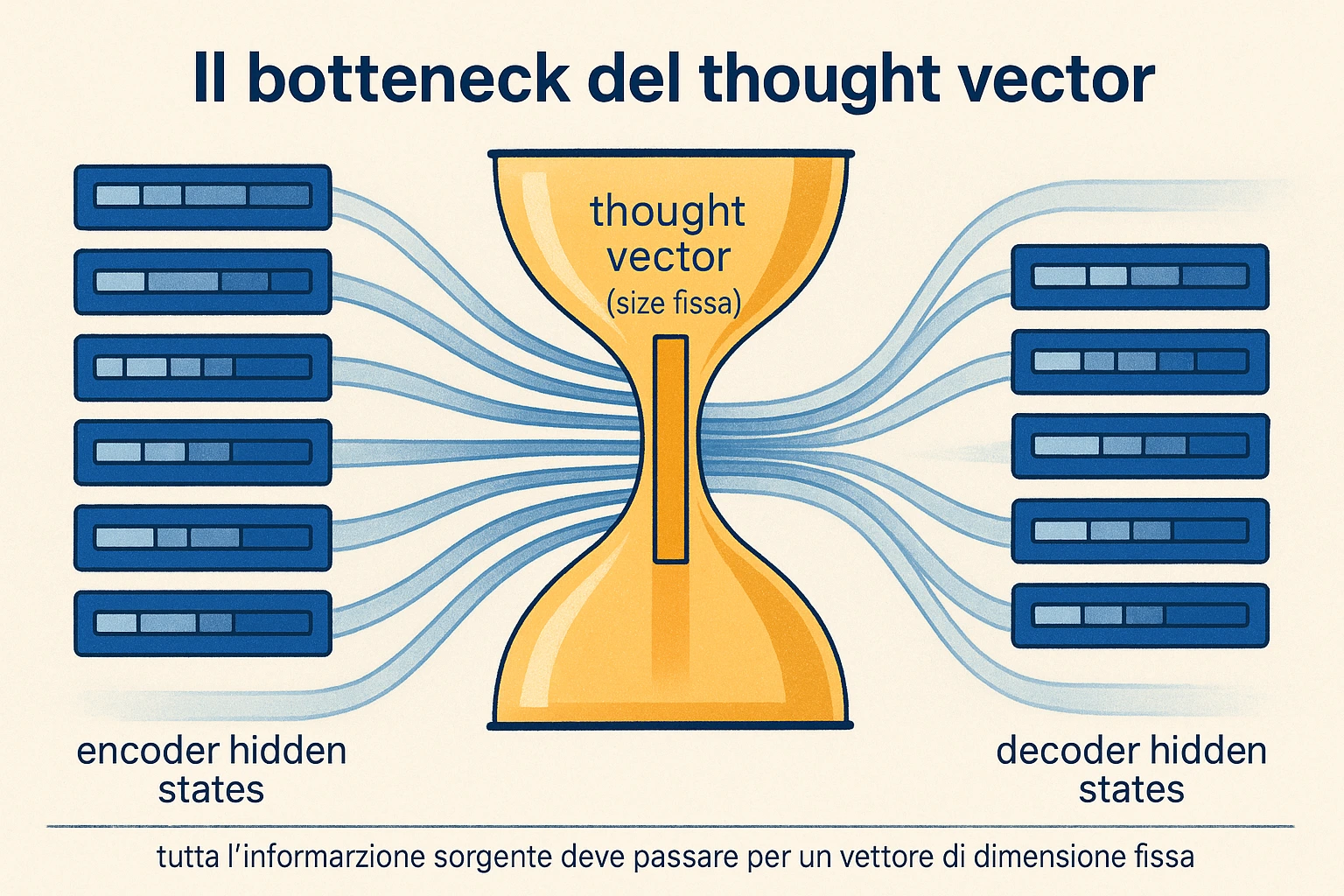
Dopo aver processato l’ultimo token (in pratica, dopo aver letto un token speciale di end-of-sequence), l’encoder restituisce lo stato finale . Questo stato — un vettore di dimensione numeri reali, perché ci sono quattro layer e due vettori per layer (hidden + cell) — è tutto ciò che il decoder ricevera. È il “thought vector” del paper, il riassunto compresso della sorgente.
Stato finale come “thought vector”
Sezione intitolata “Stato finale come “thought vector””Sutskever in interviste successive parla di questo vettore come di un “thought”: una rappresentazione neutrale rispetto alla lingua, in cui il significato della frase sorgente vivrebbe distillato. La metafora è suggestiva ma va presa con cautela. Marcatura di classe: si tratta di analogia, non di equivalenza tra il vettore di stato e ciò che cognitivamente chiamiamo “pensiero”. Il vettore è una rappresentazione apprese per minimizzare la loss di predizione del decoder; non c’è alcuna garanzia che codifichi qualcosa di simile a un concetto disincarnato. Esperimenti successivi sui rappresentazione mostrano che il vettore cattura informazioni diverse a seconda di come è stato addestrato e di che task subordinato si voglia sondare.
In ogni caso, il punto operativo regge. Il decoder riceve un vettore di alcune migliaia di dimensioni e da quello solo deve generare l’intera traduzione. Il bottleneck — quel vettore unico — è la scommessa centrale dell’architettura. Funziona finché la sorgente è abbastanza corta da starci dentro, smette di funzionare quando la sorgente diventa lunga e l’informazione necessaria non si comprime più senza perdita rilevante.
Decoder generativo, greedy e beam search
Sezione intitolata “Decoder generativo, greedy e beam search”Il decoder LSTM viene inizializzato con dell’encoder. Al primo passo riceve in input un token speciale di start-of-sequence, e produce in output una distribuzione di probabilità’ sulla prossima parola della target. Sia la sequenza target. L’LSTM decoder processa:
Dove e sono hidden e cell del decoder, è l’embedding lookup della lingua target, e sono i pesi della proiezione finale sul vocabolario target, e softmax produce la distribuzione di probabilità’ su tutte le parole. In parole povere, a ogni passo il decoder guarda l’ultima parola che ha già generato, aggiorna il suo stato interno, e calcola un punteggio per ogni parola del vocabolario target; la softmax trasforma quei punteggi in probabilità’.
Per generare la traduzione, il modello deve scegliere parole concrete. Due strategie:
- Greedy decoding: a ogni passo, scegli la parola con probabilità massima. Veloce, ma sub-ottimale: una scelta locale può precludere completamenti globali migliori.
- Beam search: mantieni in vita le ipotesi parziali più probabili (con chiamato beam size), espandile tutte a ogni passo, e tieni le migliori delle nuove ipotesi. A fine generazione restituisci l’ipotesi con probabilità totale più alta.
Il paper di Sutskever et al. usa beam search con . Riportano che (cioe’ greedy) già produce risultati ragionevoli, ma che migliora di circa due punti BLEU. Aumentare oltre da rendimenti decrescenti. Beam search è costosa: il decoder fa volte il lavoro per token. La scelta di riflette un compromesso tra qualità e tempo di inferenza.

Input reversal: il trick che valeva 5 BLEU
Sezione intitolata “Input reversal: il trick che valeva 5 BLEU”Prima di scoprire l’effetto, gli autori provarono varianti standard. L’esperimento di base addestrava encoder e decoder su coppie nell’ordine naturale, sia per la sorgente che per la target. Il modello raggiungeva BLEU intorno a 30, già rispettabile ma non sufficiente a battere SMT. Poi qualcuno propose di alimentare l’encoder con la frase sorgente invertita: invece di leggere “the cat sat on the mat”, l’encoder vedeva “mat the on sat cat the”. La target restava nell’ordine normale.
Il guadagno fu di circa 5 BLEU. Inatteso, non spiegato da una teoria pulita, riproducibile. Il paper offre un’argomentazione ex post: invertire la sorgente avvicina temporalmente le prime parole della sorgente alle prime parole della target. In una rete ricorrente, il gradiente di una loss calcolata su deve propagarsi indietro fino agli stati che hanno processato la prima parola della sorgente. Senza inversione, quegli stati distano passi (dove è la lunghezza della sorgente). Con inversione, originale finisce in fondo all’encoder, ma le prime parole della target trovano la loro corrispondenza spaziale più vicina nel vettore di stato finale. La distanza minima tra “primo input pieno di informazione utile per il primo output” si riduce, il segnale di gradiente arriva più fresco, l’addestramento converge meglio.

L’argomento è plausibile ma non costituisce una dimostrazione formale. Il fatto che il trick funzioni bene per coppie inglese-francese (lingue con ordine SVO simile) e meno chiaramente per coppie con ordine molto diverso (giapponese-inglese, ad esempio) suggerisce che il beneficio dipende anche dalla struttura sintattica delle lingue coinvolte. È un caso istruttivo di scoperta empirica: il trick funzionava molto prima di essere capito, e attestare dignita’ alle scoperte empiriche pure (anche senza una buona spiegazione teorica) è parte del mestiere della ricerca applicata in deep learning.
Numeri concreti e training
Sezione intitolata “Numeri concreti e training”Il paper descrive un addestramento su un sottoinsieme del corpus parallelo WMT’14 English-French, circa 12 milioni di coppie di frasi, 348 milioni di parole francesi e 304 milioni di parole inglesi. Vocabolario sorgente di 160000 parole (le più frequenti), vocabolario target di 80000 parole. Ogni parola fuori vocabolario diventa un token UNK speciale.
Iperparametri: 4 layer di LSTM, 1000 unità per layer, embedding di dimensione 1000, batch size di 128 sequenze, gradient clipping per evitare gradient esplosivi, stochastic gradient descent con learning rate 0.7 decrementato a meta’ addestramento. Inizializzazione uniforme tra -0.08 e 0.08 per tutti i parametri. Niente regolarizzazione L2, niente dropout (sarà introdotto in versioni successive di seq2seq).
L’addestramento dura circa 10 giorni su 8 GPU (presumibilmente Tesla K20 o simili dell’epoca, presso l’infrastruttura di Google), parallelizzando layer diversi su GPU diverse: una GPU per ogni layer LSTM, più una per il softmax. Il modello viene addestrato a minimizzare la log-likelihood negativa delle frasi target dato le frasi sorgenti, ovvero la cross-entropy parola per parola sommata sulla frase. La loss è:
Dove è il dataset di coppie, sono i parametri della rete, e la fattorizzazione interna riflette la natura autoregressiva del decoder. In parole povere, il modello viene punito proporzionalmente alla sorpresa che ha sulla parola corretta, sommata su tutti i token di tutte le frasi.
Risultati BLEU su WMT’14 English-French
Sezione intitolata “Risultati BLEU su WMT’14 English-French”I numeri pubblicati nel paper, su test set newstest2014:
- Baseline SMT (sistema di Edinburgh, vincitore WMT’14): BLEU 33.30.
- Single LSTM seq2seq con input reversal: BLEU 30.59.
- Single LSTM seq2seq con input reversal + rescoring delle 1000 ipotesi del decoder SMT (uso ibrido): BLEU 36.50.
- Ensemble di 5 LSTM seq2seq con input reversal e diversi seed di inizializzazione: BLEU 34.81.
- Ensemble di 5 LSTM con rescoring SMT: BLEU 37.0.

Il numero che fa storia è 34.81: la prima volta che un sistema neurale puro, senza componenti di SMT, batte una baseline statistica forte su un benchmark grande. Il rescoring (36.50, 37.0) mostra che combinare neurale e simbolico produce numeri ancora migliori, ma il messaggio politicamente importante è un altro: il sistema neurale puro funziona da solo, e da solo è competitivo.
Una nota sulla metrica BLEU, perché regge tutto il discorso. BLEU (Bilingual Evaluation Understudy, Papineni et al. 2002) misura la sovrapposizione di n-gram tra la traduzione candidata e una o più traduzioni di riferimento prodotte da umani. Si calcola come la media geometrica delle precisioni di n-gram (n da 1 a 4 tipicamente), corretta da una brevity penalty che scoraggia traduzioni troppo corte. Una BLEU di 30 è considerata una traduzione utile ma con errori visibili; sopra 40 si entra in territorio di qualità alta; sopra 50 si discute di qualità vicino-umana per molte coppie. La metrica ha limiti noti (premia parafrasi superficiali, ignora la sinonimia, non sempre correla con il giudizio umano), ed è stata affiancata negli anni successivi da metriche come METEOR, chrF, BLEURT, COMET. Ma nel 2014 era lo standard universale, e la differenza tra 33.30 e 34.81 era — nel contesto di una decade di miglioramenti incrementali da 0.5 punti — un salto vistoso.
Vale la pena notare un dettaglio sui modelli lunghi. Nel paper, gli autori riportano che il modello traduce frasi di tutte le lunghezze, ma che la qualità degrada visibilmente per sorgenti oltre 30-35 parole. La tabella delle performance per lunghezza (figura 3 del paper) mostra il BLEU che cala monotonicamente quando la frase sorgente diventa più lunga, mentre i sistemi SMT degradano molto meno. È il primo segnale chiaro del bottleneck del vettore di stato fisso, e diventerà la motivazione esplicita del paper di Bahdanau et al. di poche settimane successivo.
Esempio operativo: tradurre passo per passo
Sezione intitolata “Esempio operativo: tradurre passo per passo”Per fissare la meccanica, immaginiamo di voler tradurre “the cat sat on the mat” in francese, parola per parola.
-
Tokenizzazione e inversione della sorgente:
- Frase:
the cat sat on the mat <EOS> - Invertita:
<EOS> mat the on sat cat the
- Frase:
-
Encoder forward: l’encoder LSTM legge
<EOS>,mat,the,on,sat,cat,thein sequenza. Dopo l’ultimo token, ottiene uno stato finale di dimensione 8000 numeri reali. -
Decoder init: diventa lo stato iniziale del decoder. Il primo input al decoder è un token speciale
<START>. -
Decoder step 1: il decoder produce una distribuzione su tutto il vocabolario francese. Beam search seleziona le 12 parole più probabili. Probabilmente
le,la,un,chatsaranno tra le più probabili. -
Decoder step 2: per ciascuna delle 12 ipotesi, il decoder estende. Se l’ipotesi corrente è “le”, si chiede: dato lo stato dopo aver generato “le”, che parola viene dopo? Probabilmente
chatcon probabilità’ alta. Per “la” probabilmentechatte. -
Continua finché una delle ipotesi raggiunge
<EOS>o supera una lunghezza massima. Le ipotesi vengono poi ordinate per log-probabilità totale (con eventuale length normalization). -
Output finale: l’ipotesi a maggior probabilità’ totale, ad esempio “le chat etait assis sur le tapis
”.
Tutto il processo non assume alcun lessico bilingue esplicito, alcun ordine sintattico programmato, alcuna regola morfologica. Le scelte (le vs la, chat vs chatte, accordo del participio assis) emergono dalla distribuzione appresa. Da notare: il modello non sa di star traducendo. Sa solo che a una sequenza di token “inglesi” associa una distribuzione di sequenze di token “francesi”, e quella distribuzione è stata calibrata su dodici milioni di esempi affinché la probabilità’ della corretta traduzione fosse alta. Tutto ciò che chiamiamo “comprensione” o “morfologia” è un epifenomeno della pressione di ottimizzazione su quei dati.
Pseudocodice del training step
Sezione intitolata “Pseudocodice del training step”Per chiarire come il modello viene addestrato, uno schizzo di pseudocodice di un singolo step di training:
# Input batch: lista di coppie (source, target)# source: lista di token id sorgenti, lunghezza T_i variabile# target: lista di token id target, lunghezza T'_i variabile
def train_step(batch, encoder, decoder, optimizer): total_loss = 0 for (source, target) in batch: # Inverti la sorgente source_rev = list(reversed(source))
# Forward encoder h, c = init_zero_states(num_layers=4, dim=1000) for token_id in source_rev: embed = encoder.embed_lookup(token_id) h, c = encoder.lstm(embed, h, c) # Stato finale: (h, c) di dimensione (4, 1000) ciascuno
# Forward decoder con teacher forcing s, k = h, c loss = 0 prev_token = START_TOKEN for true_token in target: embed = decoder.embed_lookup(prev_token) s, k = decoder.lstm(embed, s, k) logits = decoder.output_proj(s) probs = softmax(logits) loss = loss - log(probs[true_token]) prev_token = true_token # teacher forcing
total_loss = total_loss + loss
# Backward e update total_loss.backward() clip_gradients(encoder.parameters() + decoder.parameters(), max_norm=5.0) optimizer.step() optimizer.zero_grad()Nota due dettagli pratici. Primo, il teacher forcing: durante l’addestramento, il decoder riceve come input al passo la vera parola precedente , non quella che il modello avrebbe generato. Questo accelera l’addestramento e stabilizza i gradienti, ma crea un mismatch con l’inferenza, dove il decoder vede solo le proprie predizioni. Il fenomeno è noto come exposure bias, e tecniche per mitigarlo (scheduled sampling, sequence-level training) verranno proposte negli anni successivi. Secondo, il gradient clipping: i gradienti delle LSTM possono esplodere su sequenze lunghe; il paper applica un clipping con norma massima 5.0.
Esempio di degradazione su frase lunga
Sezione intitolata “Esempio di degradazione su frase lunga”Considera una frase di sessanta parole, una di quelle frasi tecniche o legali con relative subordinate annidate. L’encoder LSTM la processa parola per parola, e dopo sessanta passi deve aver compresso tutto in 8000 numeri. Per molti dettagli — un nome proprio menzionato a meta’, un soggetto di una subordinata distante — quei 8000 numeri non bastano. La generazione del decoder, al passo in cui dovrebbe ricordare quel dettaglio, lo trova “annacquato” nello stato. Il risultato pratico: la traduzione perde fedeltà’ lessicale, omette pezzi, ripete cose, sbaglia accordi. La metrica BLEU cade.
Il paper di Sutskever lo riconosce esplicitamente. Il grafico delle performance per lunghezza nel paper mostra BLEU intorno a 36 per frasi sotto le 20 parole, intorno a 34 per frasi tra 20 e 30, intorno a 30 per frasi tra 30 e 40, e in calo ulteriore per frasi più lunghe. SMT degrada meno perché il phrase-based decoder ha accesso esplicito a tutta la sorgente in ogni momento, non a un riassunto compresso. È la stessa intuizione che guiderà attention: dare al decoder la possibilità di “guardare indietro” alla sorgente a ogni passo, invece di affidarsi solo al riassunto.
Costo computazionale e infrastruttura del 2014
Sezione intitolata “Costo computazionale e infrastruttura del 2014”Vale la pena un dettaglio sull’infrastruttura, perché rende concreta l’idea di “rete grande per l’epoca”. Il modello di Sutskever et al. ha 384 milioni di parametri. Un singolo step di forward+backward richiede di processare il batch attraverso quattro layer di LSTM nell’encoder e quattro nel decoder, più la softmax finale su 80000 parole. Sulle GPU del 2014 (Tesla K20 con 5 GB di memoria, circa 1 TFLOP in FP32), un solo modello non ci stava in una GPU singola: il paper descrive una parallelizzazione manuale per cui ogni layer LSTM stava su una GPU diversa. Otto GPU per modello, dieci giorni di training. Per un ensemble di cinque modelli: cinque volte tutto, anche se in parallelo. Il costo totale dell’esperimento è nell’ordine delle centinaia di GPU-day.
Per dare ordine di grandezza: è un costo piccolo nei termini odierni (un singolo training run di un modello frontier nel 2025 può impiegare decine di migliaia di GPU per mesi), ma nel 2014 era un costo non banale, accessibile praticamente solo a Google, Microsoft, Facebook e a pochi laboratori accademici con cluster dedicati. La barriera all’ingresso del neural MT non era solo intellettuale: era infrastrutturale. Nei tre anni successivi, la diffusione di TensorFlow (rilasciato da Google a fine 2015) e di hardware più capace (Tesla K40, K80, P100 nel 2016) avrebbe abbassato la barriera, e il neural MT sarebbe diventato accessibile a molti più gruppi.
Applicazioni pratiche
Sezione intitolata “Applicazioni pratiche”Traduzione come prodotto
Sezione intitolata “Traduzione come prodotto”Il caso d’uso più evidente di seq2seq nei due anni successivi è il deploy in produzione su Google Translate. Da settembre 2016, con il deploy di GNMT, le query di Google Translate per le coppie maggiori vengono servite da un modello neurale derivato da seq2seq. L’impatto sull’utente medio è immediato: la qualità soggettiva delle traduzioni cambia visibilmente, in particolare su frasi medio-lunghe, su domini idiomatici, su lingue con morfologia ricca. Il numero di errori sintattici grossolani cala. L’esperienza non è perfetta — la NMT del 2016 sbaglia ancora su nomi propri, acronimi, codice — ma è percepibilmente migliore.
Il caso è importante anche come studio di rollout: Google annuncia il deploy con un blog post tecnico il 27 settembre 2016, accompagnato dal paper GNMT su arXiv lo stesso giorno. La transizione è graduale, coppia di lingue per coppia di lingue, su scale di settimane. Non c’è un “switch” istantaneo: c’è una fase di shadow testing in cui il sistema neurale gira in parallelo a quello statistico, le metriche vengono confrontate, le coppie vengono migrate quando il neurale supera lo statistico in modo consistente.
Image captioning
Sezione intitolata “Image captioning”Pochi mesi dopo seq2seq, lo stesso schema viene applicato all’image captioning. L’encoder LSTM è sostituito da una CNN (tipicamente GoogLeNet o VGG) che produce un vettore di feature dell’immagine. Il decoder LSTM è identico a quello di seq2seq: prende il vettore di feature come stato iniziale e genera la didascalia parola per parola. Il paper “Show and Tell” di Vinyals et al. 2015 raggiunge BLEU competitivo sui benchmark di image captioning (Flickr8k, Flickr30k, MS COCO).
Il fatto che l’idea si trasferisca senza modifiche strutturali significative — sostituisci l’encoder, mantieni il decoder — è la dimostrazione operativa della generalità’ del pattern. Non importa cosa produca il vettore di “thought”: basta che sia un vettore di dimensione fissa, e il decoder sa cosa farci.
Speech recognition end-to-end
Sezione intitolata “Speech recognition end-to-end”Per decenni, l’Automatic Speech Recognition (ASR) era stata dominata da pipeline complesse: feature engineering acustico (MFCC, mel-spectrogram), modelli acustici a base di Hidden Markov Models (HMM) con Gaussian Mixture Models, modelli di linguaggio n-gram, decoder a fattori. Seq2seq apre la strada a sistemi end-to-end che mappano direttamente sequenze audio in sequenze di caratteri o phonemi. “Listen, Attend and Spell” (Chan et al. 2016) usa un encoder che processa frame audio (con downsampling per ridurre la lunghezza) e un decoder LSTM con attention che genera caratteri. Whisper di OpenAI (2022) eredita lo stesso pattern, sostituendo le LSTM con transformer.
Estensioni successive nel mondo della generazione strutturata
Sezione intitolata “Estensioni successive nel mondo della generazione strutturata”Il pattern encoder-decoder seq2seq, con le opportune modifiche, viene esteso a task più strutturati di traduzione testuale. Pointer Networks (Vinyals et al. 2015) modificano l’output del decoder per puntare a posizioni dell’input invece di generare token: utili per task come l’ordinamento di sequenze o la copia di tratti dall’input. CopyNet (Gu et al. 2016) combina generazione e copia per task di summarization. Nei modelli moderni di code generation, l’encoder-decoder è ancora un default per task come la traduzione di codice tra linguaggi (Java a C#, Python a JavaScript), mentre per la generazione “from scratch” da specifica in linguaggio naturale prevale il decoder-only.
Lezione operativa: pipeline contro end-to-end nel mestiere di costruire sistemi
Sezione intitolata “Lezione operativa: pipeline contro end-to-end nel mestiere di costruire sistemi”Per chi costruisce sistemi software con componenti AI nel 2026, seq2seq lascia una euristica concreta. Quando ti trovi davanti a un problema in cui mappare un input strutturato a un output strutturato, e quando hai (o puoi raccogliere) abbastanza esempi di coppie input-output, la prima cosa da provare è un singolo modello end-to-end. La pipeline esplicita — preprocessing manuale, classificatori per stadi intermedi, regole hard-coded — diventa la fallback, non il default. Questo non significa che la pipeline sia sempre sbagliata: per problemi a basso volume di dati, per problemi dove l’interpretabilità è un vincolo regolatorio, per problemi dove componenti riusabili sono essenziali, la pipeline ha vantaggi. Ma il default è invertito rispetto al pre-2014.
Eredità oggi
Sezione intitolata “Eredità oggi”[DATATO 2026-04]
Filiazione documentata: la linea che parte da seq2seq
Sezione intitolata “Filiazione documentata: la linea che parte da seq2seq”La linea che parte dal paper Sutskever-Vinyals-Le è una delle filiazioni più nette della storia recente del NLP. La prima evoluzione, cronologicamente sovrapposta, è il paper di Bahdanau-Cho-Bengio sull’attention (settembre 2014 su arXiv, ICLR 2015). Il paper risolve il bottleneck mostrando come il decoder possa, a ogni passo di generazione, calcolare pesi di attenzione su tutti gli stati nascosti dell’encoder e produrre una rappresentazione contestualizzata che dipende dal momento corrente di generazione. Il vettore di stato fisso scompare, sostituito da una distribuzione dinamica su tutti gli stati. Le frasi lunghe smettono di essere un problema. Questa sarà la sostanza del prossimo capitolo, attention-bahdanau-2014 (in preparazione).
Due anni dopo, nel 2016, Yonghui Wu e cinquanta-e-più co-autori a Google pubblicano “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation” (arXiv:1609.08144). È il paper di sistema che descrive GNMT, il sistema di neural machine translation che Google deploya in produzione su Translate per la maggior parte delle coppie di lingue principali. GNMT è tecnicamente un’estensione di seq2seq con attention: encoder e decoder LSTM profondi (8 layer ciascuno), residual connection per stabilizzare l’addestramento di reti così profonde, attention dot-product, training distribuito su decine di GPU per giorni. Il deploy in produzione è annunciato a settembre 2016: in un giorno, intere coppie di lingue su Google Translate passano da SMT a NMT, con miglioramenti soggettivi della qualità di traduzione vicini ai punteggi umani su molte coppie. È la prima volta che il neural MT diventa il default per centinaia di milioni di utenti.
Nel 2017 due paper proseguono la filiazione spostando il focus dall’LSTM a tipi di rete diversi. Jonas Gehring, Michael Auli, David Grangier, Denis Yarats e Yann Dauphin (Facebook AI Research) pubblicano a ICML 2017 “Convolutional Sequence to Sequence Learning” (arXiv:1705.03122), che sostituisce le LSTM con reti convoluzionali. Il vantaggio: parallelizzazione massiccia durante il training (le CNN non hanno la dipendenza temporale stretta delle RNN). Il modello raggiunge qualità simile a GNMT con tempi di training molto inferiori. Pochi mesi dopo, a NIPS 2017, Ashish Vaswani e sette co-autori a Google pubblicano “Attention Is All You Need” (arXiv:1706.03762), che introduce il transformer: niente più ricorrenza, niente più convoluzione, solo attention multi-head. Il transformer eredita esplicitamente la struttura encoder-decoder di seq2seq (e di GNMT) — i blocchi sono organizzati in encoder stack e decoder stack collegati da cross-attention — ma rimuove l’unico componente che restava da seq2seq vanilla, la rete ricorrente.
La linea di filiazione si può raccontare così:
- 2014 settembre: seq2seq vanilla (encoder-decoder LSTM, vettore di stato fisso).
- 2014 settembre: seq2seq + attention (Bahdanau et al., risolve il bottleneck).
- 2016 settembre: GNMT (deploy a scala produzione, encoder-decoder LSTM profonde con attention).
- 2017 maggio: ConvS2S (encoder-decoder convoluzionale, parallelizzazione di training).
- 2017 giugno: transformer (encoder-decoder solo-attention, eredita lo schema, butta via la ricorrenza).
Quattro paper, tre anni, una linea di evoluzione netta. Il transformer non è una rivoluzione orfana: è l’esito naturale di una serie di passi che parte dal paper di Sutskever.
Vale la pena soffermarsi sui ruoli individuali in questa filiazione, perché raccontano qualcosa sull’ecosistema. Sutskever passa da Google Brain a OpenAI nel 2015, dove diventa chief scientist e contribuisce direttamente alla nascita della famiglia GPT. Vinyals resta in orbita Google e si sposta verso DeepMind, dove lavorerà su Show and Tell, Pointer Networks, AlphaStar, e molti altri lavori che ereditano lo schema seq2seq con varianti. Le resta a Google Brain dove diventerà figura chiave per AutoML e neural architecture search. Cho si stabilisce a New York University come professore. Bahdanau prosegue su NMT e dialogo. Bengio, da Montreal, continua a guidare il MILA. La rete dei nomi del 2014 si dispiega nel decennio successivo come spina dorsale del campo, attraversando Google, OpenAI, DeepMind, Meta, accademia.
Applicazioni oltre la traduzione
Sezione intitolata “Applicazioni oltre la traduzione”Il pattern encoder-decoder si rivela immediatamente generale. Nei due-tre anni successivi a seq2seq escono paper che lo applicano a task molto diversi.
-
Image captioning: l’encoder è una CNN (tipicamente VGG o GoogLeNet) che produce feature dell’immagine, il decoder è un LSTM che genera la didascalia. Il paper di riferimento è “Show and Tell: A Neural Image Caption Generator” di Oriol Vinyals, Alexander Toshev, Samy Bengio e Dumitru Erhan (CVPR 2015, arXiv:1411.4555), uscito appena qualche mese dopo seq2seq. L’autore principale Vinyals è lo stesso del paper seq2seq: il riuso dell’idea è immediato.
-
Speech recognition: encoder che processa feature audio (mel-spectrogram), decoder che genera caratteri o phonemi. “Listen, Attend and Spell” di William Chan, Navdeep Jaitly, Quoc Le e Oriol Vinyals (2016, arXiv:1508.01211) è un esempio canonico. Anche qui i nomi si sovrappongono.
-
Summarization: encoder = documento sorgente, decoder = riassunto. Il paper “A Neural Attention Model for Abstractive Sentence Summarization” di Alexander Rush, Sumit Chopra e Jason Weston (2015, arXiv:1509.00685) applica seq2seq con attention al task di summarization a livello di frase. Le evoluzioni successive (Pointer Networks, See et al. 2017) portano summarization a livello di documento.
-
Question answering: encoder = domanda + contesto, decoder = risposta. Molti modelli di QA generativo (e poi BART, T5) usano la struttura encoder-decoder.
-
Code generation: encoder = specifica in linguaggio naturale o context di codice, decoder = codice. Il filone si sviluppa in modo significativo dal 2015 in poi e diventa centrale dopo i transformer.
Modelli moderni: l’eredità strutturale
Sezione intitolata “Modelli moderni: l’eredità strutturale”Nel 2026, gran parte dei modelli di linguaggio che si usano in produzione ereditano vocabolario e struttura da seq2seq. I modelli encoder-decoder classici come BART (Lewis et al. 2019), T5 (Raffel et al. 2020), Flan-T5 mantengono letteralmente lo schema encoder + decoder con cross-attention. I modelli decoder-only dominanti — GPT, Claude, Gemini, Llama — rinunciano all’encoder esplicito ma mantengono il pattern autoregressivo del decoder seq2seq: generare un token alla volta, condizionando sui token precedenti. La distinzione tra encoder-only (BERT-style), encoder-decoder (T5-style), decoder-only (GPT-style) come tre famiglie architetturali nasce dalla cornice fissata da seq2seq.
Un dettaglio che merita: la scelta tra encoder-decoder e decoder-only non è tecnicamente forzata, è empirica e culturale. In linea di principio, qualunque task seq2seq si può formulare come decoder-only concatenando sorgente e target in un’unica sequenza separata da token speciali; allo stesso modo, qualunque task generativo si può formulare con un encoder-decoder dedicando l’encoder al “prompt” e il decoder al “completion”. Le ragioni per cui il decoder-only ha vinto sui task di linguaggio generativo (semplicità di training, riuso del cache durante l’inferenza, scalabilità su grandi dataset misti) sono argomento di un’altra discussione, ma il vocabolario per discuterle nasce qui.
C’è anche una lezione metodologica che si è radicata nel mestiere. End-to-end batte la pipeline quando ci sono dati e compute sufficienti. Questa massima — implicita già in AlexNet 2012 sull’image classification e in word2vec 2013 sugli embedding — diventa esplicita con seq2seq sulla traduzione, e si conferma con ogni passo successivo (parsing neurale, speech end-to-end, multimodal end-to-end). Il corollario operativo: prima di costruire una pipeline complicata di stadi specializzati, prova a definire l’input, l’output e abbastanza dati di training, e lascia che una rete grande impari il resto. Vale ovviamente con caveat (alcuni domini non hanno dati sufficienti, alcuni vincoli di interpretabilità richiedono pipeline esplicite), ma il default è cambiato.
Dove si rompe
Sezione intitolata “Dove si rompe”Il bottleneck del vettore di stato fisso
Sezione intitolata “Il bottleneck del vettore di stato fisso”Il limite strutturale più visibile del seq2seq vanilla è il bottleneck. Tutta la sorgente deve passare attraverso un singolo vettore di poche migliaia di dimensioni. Per frasi corte (sotto le 20 parole) la compressione è sostenibile. Per frasi lunghe la perdita di informazione diventa critica: dettagli lessicali, riferimenti pronominali, costruzioni sintattiche annidate vengono “schiacciati” o persi. Il calo di BLEU oltre le 30 parole è documentato nel paper stesso.
Il problema è risolto dall’attention di Bahdanau et al. praticamente in contemporanea. Da quel momento, il “thought vector” come architettura primaria sparisce: tutti i sistemi NMT successivi includono attention. Vale la pena notare che il paper di Sutskever non aveva attention, e che il successo del paper deve molto al trick di input reversal — un workaround empirico al bottleneck, non una soluzione strutturale. Senza inversione, seq2seq vanilla non avrebbe battuto SMT.
È una osservazione interessante di policy della ricerca: lo stesso problema strutturale viene risolto in due modi nello stesso anno, da due gruppi diversi. Sutskever et al. lo arginano con un trick (input reversal) che migliora la situazione senza cambiare l’architettura; Bahdanau et al. lo affrontano con una modifica architetturale (attention) che lo elimina. Il primo approccio paga in immediatezza (un’idea da implementare in un giorno), il secondo paga in profondita’ strutturale. Entrambi sono leciti e in storia della ricerca convivono. La filiazione lunga viene dal secondo, ma il primo è quello che permette al paper di Sutskever di vincere il confronto numerico nel 2014.
Sample inefficient: servono milioni di coppie
Sezione intitolata “Sample inefficient: servono milioni di coppie”Il modello di Sutskever et al. è addestrato su circa 12 milioni di coppie sorgente-target. Per coppie di lingue ad alta risorsa (inglese-francese, inglese-tedesco, inglese-cinese) i corpora paralleli sono disponibili a quella scala. Per coppie di lingue a bassa risorsa — la maggioranza delle 7000 lingue del mondo — i corpora paralleli sono di ordini di grandezza inferiori, e seq2seq vanilla non funziona. Il problema della low-resource translation diventerà un sotto-campo di ricerca con tecniche dedicate (back-translation, multilingual NMT, transfer learning). L’unsupervised NMT (Lample et al. 2017, Artetxe et al. 2017) cercherà di addestrare senza alcun corpus parallelo, con risultati inizialmente modesti.
Il contrasto con SMT su questo punto merita attenzione. SMT in regime low-resource degrada gracefulmente: con poche migliaia di coppie e una buona modellistica statistica, si ottiene un sistema rudimentale ma utilizzabile. Seq2seq vanilla con poche migliaia di coppie produce output incoerente o copia la sorgente. La curva di efficienza in funzione del corpus è molto diversa: NMT batte SMT a corpora grandi, perde a corpora piccoli. Il punto di pareggio dipende dalla coppia di lingue, ma nel 2014 era stimato intorno al milione di coppie. Sotto quella soglia, la pipeline statistica restava la scelta sensata.
Sequenza ricorrente: lenta, non parallelizzabile
Sezione intitolata “Sequenza ricorrente: lenta, non parallelizzabile”L’LSTM processa la sequenza un token alla volta. Lo stato al passo dipende dallo stato al passo , quindi il forward sull’encoder non si può parallelizzare temporalmente. Per sorgenti lunghe il training diventa lento. Lo stesso vale per il decoder. Su batch grandi e GPU moderne, l’LSTM è molto meno efficiente della convoluzione (parallelizzabile sulla dimensione temporale) e dell’attention (idem). Questo limite motivera ConvS2S nel 2017 e poi il transformer.
Conseguenza pratica: il transformer addestra modelli più grandi nello stesso tempo wall-clock di un LSTM di scala equivalente, semplicemente perché usa meglio le GPU. Quando la scala diventa il fattore dominante (post-2018, con GPT, BERT, GPT-3), l’LSTM diventa rapidamente non competitiva e sparisce dalla pratica produttiva di NMT.
In inferenza la storia è un po’ diversa. Anche il transformer decoder genera un token alla volta in modalita’ autoregressiva: ogni token nuovo richiede una passata attraverso tutti i layer. Il vantaggio rispetto a LSTM in inferenza è meno netto, ed è qui che entrano in gioco tecniche come KV cache, speculative decoding, paged attention: ottimizzazioni che rendono il decoder transformer pratico anche su context lunghi. Per LSTM molte di queste tecniche non si applicano allo stesso modo, perché lo stato è un vettore unico per layer invece che una matrice di attivazioni passate. Anche solo per questa ragione, l’inferenza moderna di NMT è transformer-only.
Mito: “seq2seq risolve la traduzione automatica”
Sezione intitolata “Mito: “seq2seq risolve la traduzione automatica””Il numero 34.81 vs 33.30 è suggestivo, ma è importante leggerlo nel contesto. Seq2seq batte SMT su WMT’14 English-French, una coppia di lingue grande, simili sintatticamente, con corpora paralleli enormi. Su coppie più difficili (giapponese-inglese, finlandese-inglese), su domini specializzati, su frasi lunghe, su low-resource, seq2seq vanilla nel 2014 non era ancora competitivo. La qualità “human parity” verrà rivendicata da Microsoft per cinese-inglese su domini specifici nel 2018, e anche allora con caveat metodologici.
Il messaggio storico corretto è più sfumato: seq2seq apre la porta al neural MT come paradigma, dimostra che è una direzione promettente, ma la qualità produttiva richiedera attention, deep stacks, training su corpora enormi, e infine il transformer. Il paper Sutskever-Vinyals-Le è il primo passo di una scala, non l’arrivo.
Mito: “input reversal è un fix universale”
Sezione intitolata “Mito: “input reversal è un fix universale””Il trick funziona bene per coppie di lingue con ordine sintattico simile (SVO-SVO, come inglese-francese o inglese-spagnolo). Per coppie con ordine molto diverso (giapponese SOV vs inglese SVO, ad esempio), l’effetto è meno chiaro o assente. Inoltre, dopo l’introduzione di attention, il trick smette di servire: l’attention da’ al decoder accesso diretto a tutti gli stati, indipendentemente dall’ordine. Come molte trovate empiriche del deep learning, input reversal è una soluzione contingente a un limite specifico (gradient flow attraverso un bottleneck), che diventa irrilevante quando il limite è rimosso strutturalmente.
Mito: “il thought vector codifica un significato disincarnato”
Sezione intitolata “Mito: “il thought vector codifica un significato disincarnato””L’idea che il vettore di stato finale dell’encoder sia un “thought” indipendente dalla lingua è suggestiva e ha generato fascinazione (e marketing) negli anni successivi. Ma le verifiche empiriche sono ambigue. Probing studies su embedding di seq2seq mostrano che il vettore codifica principalmente lessico e morfologia superficiale, in modo strettamente accoppiato alla coppia di lingue su cui è stato addestrato. Spostare il vettore appreso su una nuova coppia di lingue richiede ri-addestramento. Non è chiaro che ci sia in quel vettore qualcosa di simile a “significato puro”. È una rappresentazione utile per il task di traduzione, e basta.
La tentazione di antropomorfizzare le rappresentazioni neurali è ricorrente in ML e va trattata con disciplina. Il vettore è una rappresentazione apprese, non un pensiero.
Vocabolario chiuso e parole fuori vocabolario
Sezione intitolata “Vocabolario chiuso e parole fuori vocabolario”Il modello del paper opera su un vocabolario di parole “intere”: 160000 parole sorgente, 80000 parole target. Tutto ciò che non rientra nel vocabolario diventa un token speciale UNK durante l’addestramento e l’inferenza. Per testi di dominio specialistico (medico, legale, tecnico), per nomi propri rari, per neologismi, il modello “vede” UNK e produce UNK. Questo limite — gestione fragile delle parole fuori vocabolario — diventerà una motivazione forte per i sistemi di subword tokenization: BPE (Sennrich et al. 2016) e SentencePiece (Kudo-Richardson 2018). Spezzare una parola in unità’ subword permette di rappresentare qualunque stringa con un vocabolario fisso e modesto, eliminando il problema UNK strutturalmente.
La mossa verso subword non è solo una correzione tecnica: cambia la natura del modello. Un seq2seq subword non lavora più su “parole” ma su unità’ morfologiche apprese. Il pattern è tutt’oggi lo standard nei tokenizer di transformer.
Mancanza di coverage e ripetizioni
Sezione intitolata “Mancanza di coverage e ripetizioni”Un fallimento empirico tipico dei primi sistemi seq2seq è la ripetizione: il decoder genera la stessa frase due o tre volte di seguito, oppure dimentica di tradurre intere clausole della sorgente. Il problema deriva dalla mancanza di un meccanismo esplicito che tenga traccia di “quanto della sorgente è stato già coperto”. Anche dopo l’introduzione di attention, il fenomeno sopravvive ed è affrontato con tecniche come coverage penalty (Tu et al. 2016, Wu et al. 2016 dentro GNMT) che penalizzano l’attention che si concentra ripetutamente sugli stessi token sorgente. Il mito “una volta fatto seq2seq, la traduzione è risolta” si scontra subito con questi fallimenti molto concreti, e una buona parte dell’ingegneria di NMT post-2014 è precisamente nell’arginare modi di rottura specifici.
Greedy decoding rispetto a beam search
Sezione intitolata “Greedy decoding rispetto a beam search”Il paper riporta che beam search con migliora di circa due punti BLEU rispetto a greedy (). Non è un dettaglio innocuo: beam search è una euristica di ricerca, e l’output finale dipende dalla sua dinamica. Beam molto largo (es. ) può a volte peggiorare, perché favorisce ipotesi corte (la log-probabilità totale cala con la lunghezza). Tecniche di length normalization e di coverage penalty vengono introdotte in GNMT per mitigare questi effetti. Il decoding è un capitolo a parte della NMT che il paper Sutskever non discute in dettaglio.
Exposure bias e teacher forcing
Sezione intitolata “Exposure bias e teacher forcing”L’addestramento usa teacher forcing: a ogni passo il decoder vede la vera parola precedente, non quella generata. All’inferenza, vede invece le proprie predizioni. Se a un passo il modello sbaglia, le predizioni successive sono condizionate da quell’errore, e il modello non ha mai visto durante il training un input così fatto. Questo mismatch — exposure bias — può causare degradazione su frasi lunghe e su predizioni cumulative. Tecniche come scheduled sampling (Bengio et al. 2015) e training a livello sequenza (Ranzato et al. 2015) cercano di mitigarlo, con risultati modesti. Il problema resta strutturale dei modelli autoregressivi, presente anche oggi nei decoder-only LLM (anche se in pratica meno critico per ragioni che riguardano la scala).
Mancanza di interpretabilità
Sezione intitolata “Mancanza di interpretabilità”Una pipeline SMT è relativamente trasparente: si possono ispezionare le tabelle di traduzione di phrase pair, osservare gli allineamenti, capire perché il decoder ha scelto una particolare traduzione. In seq2seq, la scelta di una parola del decoder dipende dallo stato latente, che è un vettore di alcune migliaia di numeri reali senza significato individuale. Diagnosticare un errore — perché il modello ha tradotto X come Y? — diventa molto più difficile. L’interpretabilità delle reti neurali è un problema aperto, e seq2seq ne è un’istanza tipica. Negli anni successivi, la mechanistic interpretability affrontera questi problemi su modelli sempre più grandi, con strumenti come probing, attention visualization, sparse autoencoders. Ma il mestiere resta diverso da quello di leggere una pipeline dichiarativa.
Collegamenti
Sezione intitolata “Collegamenti”- reti-neurali-80-90 — l’LSTM di Hochreiter-Schmidhuber 1997 è il componente di base di seq2seq. Il capitolo racconta come l’LSTM sia rimasta in nicchia per quindici anni prima di esplodere in deploy massivo dal 2014.
- word2vec-2013 — gli embedding di parola usati come livello di input dell’encoder e di output del decoder discendono dalla famiglia di tecniche introdotte da Mikolov et al. Stesso anno, lavori paralleli sullo stesso tipo di rappresentazione.
- imagenet-alexnet-2012 — il momento parallelo per la computer vision. Stesso messaggio metodologico: end-to-end con grandi reti batte feature engineering tradizionale, su benchmark grande.
- rinascita-statistica-90 — la rinascita del paradigma statistico include la SMT come uno dei suoi successi più visibili. Seq2seq supera proprio quel paradigma nel suo benchmark di riferimento.
- dqn-atari-2013 — anno parallelo per il reinforcement learning end-to-end, stessa idea di sostituire feature ingegnerizzate con reti che imparano dai dati grezzi.
- attention-bahdanau-2014 (in preparazione) — il paper che risolve il bottleneck del vettore di stato fisso, uscito praticamente in contemporanea. Da li la NMT prendera la forma definitiva.
- transformer-2017 (in preparazione) — eredita la cornice encoder-decoder di seq2seq, abbandona la ricorrenza per attention pura. Il punto di arrivo della linea che parte qui.
- bert-gpt-2018-2019 (in preparazione) — la specializzazione dell’encoder-decoder in encoder-only (BERT) e decoder-only (GPT), entrambi continuazioni di seq2seq con scelte architetturali diverse.
- lstm-gru (in preparazione, Parte VIII) — la trattazione tecnica delle architetture LSTM e GRU, complementare alla narrazione storica di questo capitolo.
- seq2seq-ml (in preparazione, Parte VIII) — la trattazione “machine learning” del pattern encoder-decoder, con dettagli implementativi e formule.
- attention-ml (in preparazione, Parte VIII) — il meccanismo di attention come componente, separato dal contesto storico in cui è nato.
- attention-intuizione (in preparazione, Parte IX) — come funziona l’attention dal punto di vista dell’anatomia di un LLM moderno.
- decoder-only-vs-enc-dec (in preparazione, Parte IX) — il confronto tra le due famiglie architetturali che ereditano da seq2seq.
Vale anche un’ultima nota sulla biforcazione fra lavoro accademico e prodotto. Il paper di Sutskever et al. è un risultato di ricerca pubblicato a NIPS, breve e non ottimizzato per il deploy. La sua trasformazione in prodotto di massa avviene due anni dopo con GNMT, dove il sistema viene riprogettato per latenza, throughput, robustezza, gestione di nomi propri e numeri, fall-through su SMT in casi di fallimento. Tra ricerca e produzione passano due anni di ingegneria pesante. Per chi costruisce prodotti AI nel 2026, è un promemoria utile: un risultato research-grade su benchmark non è un prodotto. Il gap tra “batte la baseline” e “serve milioni di utenti senza errori catastrofici” può essere maggiore del gap tra l’idea originale e il primo paper.
Per andare oltre
Sezione intitolata “Per andare oltre”- Sutskever I., Vinyals O., Le Q.V., “Sequence to Sequence Learning with Neural Networks”, NIPS 2014, arXiv:1409.3215. Il paper originale, nove pagine essenziali, leggibile in un’ora. Conviene partire da qui.
- Cho K., van Merrienboer B., Gulcehre C., Bahdanau D., Bougares F., Schwenk H., Bengio Y., “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation”, EMNLP 2014, arXiv:1406.1078. Il paper precursore di tre mesi: introduce GRU e l’idea di RNN encoder-decoder dentro la pipeline SMT.
- Bahdanau D., Cho K., Bengio Y., “Neural Machine Translation by Jointly Learning to Align and Translate”, ICLR 2015, arXiv:1409.0473. Il paper che introduce attention in NMT, da leggere subito dopo seq2seq per capire come si chiude il bottleneck.
- Wu Y. et al., “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, arXiv:1609.08144, 2016. Il paper di sistema di GNMT, denso di ingegneria di produzione: residual, deep stack, parallelizzazione, decoding ottimizzato.
- Hochreiter S., Schmidhuber J., “Long Short-Term Memory”, Neural Computation 1997. Il paper fondante dell’LSTM. Tecnico, ma indispensabile per capire perché le reti ricorrenti del 2014 funzionavano e quelle degli anni 90 senza gating no.
- Vaswani A. et al., “Attention Is All You Need”, NIPS 2017, arXiv:1706.03762. Il paper del transformer, il punto di arrivo della linea che parte qui. Da leggere come continuazione naturale.
- Koehn P., “Statistical Machine Translation”, Cambridge University Press 2010. Il libro di riferimento sul paradigma SMT pre-neurale. Utile per capire cosa veniva sostituito e perché i sistemi NMT erano così dirompenti.
- Sutskever I., “An Observation on Generalization”, talk al Simons Institute, 2023. Sutskever ripercorre molti dei propri lavori, incluso seq2seq, dal punto di vista della propria traiettoria intellettuale. Utile per il colore aneddotico (incluso il famoso “expected nothing, got 5 BLEU points”).
- Papineni K., Roukos S., Ward T., Zhu W.J., “BLEU: a Method for Automatic Evaluation of Machine Translation”, ACL 2002. Il paper che introduce la metrica BLEU. Indispensabile per leggere correttamente i numeri del paper Sutskever et al.
- Vinyals O., Toshev A., Bengio S., Erhan D., “Show and Tell: A Neural Image Caption Generator”, CVPR 2015, arXiv:1411.4555. Il primo trasferimento del pattern seq2seq fuori dalla traduzione. Esempio paradigmatico della generalità’ dell’idea.
- Sennrich R., Haddow B., Birch A., “Neural Machine Translation of Rare Words with Subword Units”, ACL 2016, arXiv:1508.07909. Il paper che introduce BPE per NMT, risolvendo il problema del vocabolario chiuso che affliggeva seq2seq vanilla.