Semantica distribuzionale: "you shall know a word by the company it keeps"
Nel 1957, in un volume miscellaneo della Philological Society inglese, un linguista di Londra di sessantasette anni infila una frase che diventerà una delle massime più citate della linguistica del Novecento. Cinquantasei anni dopo, in un edificio di Mountain View, un ricercatore ceco scopre che sottraendo il vettore di “man” a quello di “king” e sommandoci il vettore di “woman” si ottiene, con buona approssimazione, il vettore di “queen”. Le due osservazioni, distanti per generazione, disciplina e supporto materiale, sono lo stesso fatto visto da due angoli.
Apertura
Sezione intitolata “Apertura”John Rupert Firth nasce a Keighley, nel West Yorkshire, nel 1890. Lavora come ufficiale dell’Indian Educational Service negli anni Venti e impara dall’antropologo polacco Bronisław Malinowski, che a Londra insegnava alla London School of Economics, l’idea che il significato di un’espressione si comprende solo dentro al suo context of situation. Quando nel 1944 viene nominato primo titolare di cattedra in linguistica generale alla School of Oriental and African Studies di Londra, Firth porta con sé quella sensibilità antropologica e la trasforma in metodo. La frase che gli sopravvive — “You shall know a word by the company it keeps” — appare a pagina 11 di un saggio del 1957, “A synopsis of linguistic theory, 1930-1955”, in un volume edito da Blackwell. La formula non era pensata come slogan: era una direttiva metodologica per linguisti pratici. Per studiare il significato di una parola di una lingua poco descritta, dovevi guardare le parole con cui ricorre, non chiedere al parlante di introspettare.
Tre anni prima Firth, su Word, una rivista americana di linguistica fondata da Roman Jakobson e André Martinet, era apparso un articolo di un altro linguista. Zellig Harris, nato nel 1909 a Balta in Ucraina, emigrato bambino negli Stati Uniti, professore alla University of Pennsylvania, intitola il pezzo “Distributional structure”. La tesi: la struttura linguistica si scopre analizzando la distribuzione degli elementi nei contesti. Harris non cita Firth e Firth non cita Harris. La convergenza è indipendente, e parla del clima intellettuale di una linguistica strutturale che cercava di stare ai dati senza appoggiarsi a entità mentali.
Trentaquattro anni dopo — è il 1990 — al Bell Communications Research di Morristown, New Jersey, un gruppo di cinque ricercatori pubblica sul Journal of the American Society for Information Science un articolo intitolato “Indexing by Latent Semantic Analysis”. Scott Deerwester, Susan Dumais, George Furnas, Thomas Landauer e Richard Harshman propongono di prendere una matrice di parole per documenti e ridurla, via Singular Value Decomposition — una fattorizzazione algebrica standard, in italiano “decomposizione ai valori singolari” — a poche centinaia di dimensioni. Il risultato cattura associazioni latenti: parole mai apparse insieme, ma apparse in documenti dal contesto simile, vengono riconosciute come affini. Il programma di Firth e Harris ha trovato la sua prima implementazione computazionale matura.
Ventitré anni dopo — è il 2013 — Tomáš Mikolov, ricercatore ceco al gruppo Google Brain di Mountain View, pubblica con tre colleghi l’arXiv 1301.3781, “Efficient estimation of word representations in vector space”. Il modello, soprannominato word2vec, addestra un piccolo classificatore neurale a predire parole vicine. I vettori che cadono fuori dall’addestramento hanno una proprietà sconcertante: l’aritmetica vettoriale codifica analogie. Vec(“king”) - vec(“man”) + vec(“woman”) ha, fra i suoi vicini più prossimi, vec(“queen”). Nei mesi successivi Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado e Jeffrey Dean estendono il modello e lo presentano a NeurIPS 2013. La community NLP cambia stack tecnico in due anni.
Cinque anni dopo, il 2018 vede arrivare due paper che sostituiscono i vettori statici di word2vec con rappresentazioni contestuali — la stessa parola riceve vettori diversi a seconda della frase. ELMo, di Matthew Peters e colleghi all’Allen Institute for AI di Seattle, e BERT, di Jacob Devlin e colleghi a Google, aprono la strada al pre-training in stile foundation model. Da lì in avanti, GPT-2 (2019), GPT-3 (2020), Claude, Gemini, Llama: ogni grande modello linguistico moderno è, alla base, una macchina che sfrutta l’ipotesi distribuzionale. Quando si dice che un foundation model “capisce il linguaggio leggendo testo”, si sta dicendo, tradotto, che la distributional hypothesis di Harris e Firth funziona meglio del previsto se la si scala con cento miliardi di parametri e qualche trilione di token.
Questo capitolo ricostruisce la semantica distribuzionale come idea, come matematica, come tecnologia, e come problema filosofico. La filiazione che lega Firth 1957 a GPT 2020 è uno dei pochi casi nettamente documentati di discendenza diretta da una tradizione cognitive science a una tecnologia AI moderna — Mikolov e Bengio citano Harris esplicitamente, Manning ne fa il primo capitolo del manuale Stanford NLP. Per questo, il presentismo qui è legittimo nel corpo del capitolo: il bridge al presente non è analogia opportunistica, è continuità tecnica.
Perché questo capitolo
Sezione intitolata “Perché questo capitolo”Tre ragioni: una scientifica, una tecnica, una di igiene concettuale.
La ragione scientifica è che la distributional hypothesis è, allo stato del 2026, la teoria del significato lessicale più produttiva mai formulata. Non perché abbia risposto al problema del significato — non l’ha fatto, e Bender-Koller 2020 mostrano dove si rompe — ma perché ha fornito una cornice operativa che ha generato decenni di ricerca in linguistica computazionale, scienze cognitive, recupero dell’informazione, traduzione automatica, e infine deep learning per linguaggio. Una teoria si misura su quanti fenomeni mette in moto e quanti esperimenti rende possibili. Questa, su quella scala, è prima della classe.
La ragione tecnica è che ogni sviluppatore che oggi tocca embedding, RAG, ricerca semantica, knowledge graph, classificatori di intent, sistemi di raccomandazione testuale, sta lavorando dentro la cornice distribuzionale, sapendolo o no. Capire da dove viene quella cornice — quali ipotesi fa, dove ha ragione di funzionare e dove no — è prerequisito per ingegnerizzarla bene. Se non si sa che cosine_similarity(query_vec, doc_vec) è una stima di quanto query e documento sono vicini in uno spazio costruito su co-occorrenze, si finisce per usare quel numero come oracolo invece che come strumento.
La ragione di igiene concettuale è che la disputa Chomsky-vs-LLM del 2023-2024 — The False Promise of ChatGPT contro Piantadosi Modern language models refute Chomsky’s approach to language — si gioca esattamente sul terreno della semantica distribuzionale. Capire cosa è la distributional hypothesis aiuta a non collassare quattro affermazioni distinte: (i) la distribuzione cattura significato lessicale, (ii) la distribuzione cattura significato pieno, (iii) i bambini imparano per distribuzione, (iv) i foundation model imparano come i bambini. Si possono accettare alcune e rifiutare altre. La sezione “Dove si rompe” elenca le equivalenze pericolose da bloccare.
Quattro principi che il capitolo fissa:
- La distributional hypothesis è una tesi sul significato lessicale, supportata empiricamente in forma forte. Compiti di sinonimia, priming, completamento, recupero documentale rispondono bene al modello distribuzionale.
- La distributional hypothesis non equivale all’identificazione tra forma e significato. Il significato pieno richiede grounding nel mondo, come argomenta Harnad 1990 e, in chiave moderna, Bender-Koller 2020 con l’esperimento mentale del polipo.
- La filiazione tecnica Firth-Harris -> word embeddings -> foundation model è documentata, non analogica. Mikolov, Bengio, Manning citano la tradizione esplicitamente. Levy-Goldberg 2014 mostrano che word2vec è, formalmente, fattorizzazione di una matrice PMI.
- Le rappresentazioni contestuali risolvono parzialmente la polysemy, non l’ancoraggio. BERT distingue bank-banca da bank-riva dentro al testo; non sa cosa sia una banca o un fiume oltre il testo.
Contesto: la traiettoria 1933-2024
Sezione intitolata “Contesto: la traiettoria 1933-2024”1933 — Wittgenstein, Blue and Brown Books (lezioni). Ludwig Wittgenstein (1889-1951, filosofo austriaco-britannico, secondo periodo a Cambridge) detta agli studenti l’idea che il significato di una parola è il suo uso nel gioco linguistico in cui è inserita. Bedeutung als Gebrauch. Le Philosophical Investigations compaiono postume nel 1953 a cura di G. E. M. Anscombe, Blackwell. Posizione filosofica, non operativa: Wittgenstein non propone un metodo di analisi linguistica. Influenza atmosferica sulla scuola di Oxford ordinary language philosophy e, indirettamente, sul clima in cui Firth lavora. Da non sovra-interpretare come filiazione tecnica.
1944-1957 — Firth a SOAS. John Rupert Firth (1890-1960) tiene la prima cattedra di linguistica generale britannica alla School of Oriental and African Studies di Londra. Sviluppa il contextualism: il significato si analizza per livelli, dal fonetico al lessicale al context of situation. La frase “you shall know a word by the company it keeps” appare nel 1957 in Studies in Linguistic Analysis, Special Volume of the Philological Society, Blackwell. Sopravvive come slogan; il programma firthiano sopravvive in forma più ridotta come London School di linguistica.
1954 — Harris, “Distributional structure”. Zellig Harris (1909-1992, linguista alla University of Pennsylvania, allievo di Edward Sapir) pubblica su Word 10(2-3): 146-162. La tesi è metodologica: per scoprire la struttura di una lingua, si analizza la distribuzione degli elementi (fonemi, morfemi, parole) nei contesti. Due elementi che hanno distribuzione identica sono, per l’analisi, lo stesso elemento. Due elementi con distribuzioni simili hanno significato simile. È la formulazione tecnica di quello che Firth dirà tre anni dopo come slogan. Harris è empirista esplicito: l’analisi distribuzionale rifiuta entità mentali non osservabili.
Il dettaglio biografico che pesa: Harris è il maestro di Noam Chomsky alla Penn negli anni Quaranta-Cinquanta. Chomsky parte da metodi distribuzionali harrisiani in fonologia e morfologia, ma rompe con l’empirismo nel passaggio alla sintassi e propone la grammatica universale (vedi grammatica universale). La distributional semantics è la linea che continua il programma di Harris dopo la rottura.
1957 — Firth, formula celebre. “You shall know a word by the company it keeps” appare a p. 11 del saggio “A synopsis of linguistic theory, 1930-1955”. Letta come complemento di Harris 1954: la distribuzione è la chiave per il significato lessicale.
1965-1980 — l’eclissi. La rivoluzione chomskyana (vedi grammatica universale) sposta il baricentro della linguistica teorica verso la sintassi formale e l’innatismo. La distributional semantics, empirista, distribuita, povera di struttura, sembra un programma desueto. Sopravvive in linguistica computazionale, in information retrieval (Salton’s vector space model, 1975), in psicolinguistica (semantic priming, McNamara), ma fuori dal mainstream teorico.
1975 — Salton, vector space model. Gerard Salton (1927-1995, computer scientist a Cornell) propone in A Vector Space Model for Automatic Indexing (CACM 1975) che documenti e query siano rappresentati come vettori sparsi su un vocabolario, e la rilevanza misurata via cosine similarity. Implementazione operativa della distributional hypothesis in un dominio applicato — l’antenato diretto di motori di ricerca e RAG.
1990 — Deerwester et al., LSA. Scott Deerwester, Susan Dumais, George Furnas, Thomas Landauer, Richard Harshman, gruppo Bellcore, JASIS 41(6): 391-407. Latent Semantic Analysis: matrice term-document, Singular Value Decomposition, troncamento ai primi k valori singolari. Il troncamento ha l’effetto di “denoising”: i pattern sistematici di co-occorrenza sopravvivono, il rumore viene buttato. L’output è uno spazio a poche centinaia di dimensioni in cui parole simili per uso sono vicine.
1990 — Church-Hanks, PMI in NLP. Kenneth Church (Bell Labs poi Microsoft) e Patrick Hanks (lessicografo, Oxford) pubblicano “Word association norms, mutual information, and lexicography” su Computational Linguistics 16(1): 22-29. Introducono la pointwise mutual information — PMI — come misura della forza di associazione fra due parole, normalizzando per le frequenze marginali. PMI diventerà la moneta corrente delle matrici di co-occorrenza.
1996 — Lund-Burgess, HAL. Curt Burgess (UC Riverside) e Kevin Lund propongono Hyperspace Analogue to Language. Variante sliding-window: per ogni parola, conta le co-occorrenze con altre parole entro una finestra di 10 parole, pesa per distanza. Vettori usati per modellare semantic priming psicolinguistico.
1997 — Landauer-Dumais, Plato’s problem. Thomas Landauer e Susan Dumais, Psychological Review 104(2): 211-240, “A solution to Plato’s problem”. Argomento: LSA, addestrato su quantità di testo paragonabili a quelle che un bambino legge prima dei vent’anni, raggiunge punteggi su sinonimia simili a un test TOEFL. Conclusione: l’apprendimento del lessico potrebbe non richiedere altro che esposizione distributionale. Argomento empirista forte contro l’innatismo, anche se LSA non era pensato come modello cognitivo realistico.
2003 — Bengio et al., neural language model. Yoshua Bengio (Université de Montréal), Réjean Ducharme, Pascal Vincent, Christian Jauvin, JMLR 3: 1137-1155, “A neural probabilistic language model”. Primo modello di linguaggio neurale moderno: ogni parola riceve un embedding — un vettore denso a poche centinaia di dimensioni — appreso end-to-end con la rete che predice la parola successiva. La proposta è poco usata per dieci anni perché computazionalmente proibitiva al tempo, ma getta le fondamenta concettuali di tutto ciò che arriva dopo.
2003 — Blei-Ng-Jordan, LDA. David Blei (allora Berkeley, oggi Columbia), Andrew Ng (Stanford), Michael Jordan (Berkeley), JMLR 3: 993-1022, “Latent Dirichlet Allocation”. Topic model bayesiano generativo: ogni documento è una miscela di topic, ogni topic una distribuzione su parole. Variante probabilistica della distributional hypothesis su scala documento.
2013 — Mikolov et al., word2vec. Tomáš Mikolov (allora Google Brain, ceco), Kai Chen, Greg Corrado, Jeffrey Dean. Due paper: Efficient estimation of word representations in vector space (arXiv 1301.3781, gennaio) introduce le architetture skip-gram e CBOW; Distributed representations of words and phrases and their compositionality (NeurIPS, ottobre, con Ilya Sutskever) aggiunge negative sampling e subsampling. Mikolov-Yih-Zweig, NAACL 2013, Linguistic regularities in continuous space word representations, mostra il famoso parallelogramma king-queen. Il pacchetto word2vec — codice C, dataset di addestramento, vettori pre-addestrati — viene rilasciato a marzo 2013 e cambia la pratica NLP in mesi.
2014 — Pennington-Socher-Manning, GloVe. Jeffrey Pennington, Richard Socher, Christopher Manning, gruppo Stanford NLP, EMNLP 2014, “GloVe: Global Vectors for Word Representation”. Combina i due approcci: invece di campionare contesti locali (word2vec) o fattorizzare la matrice intera (LSA), GloVe fattorizza la matrice di log-co-occorrenza globale con un obiettivo ai minimi quadrati pesato. Risultati comparabili a word2vec, codice e vettori pre-addestrati molto usati.
2014 — Levy-Goldberg, demistificazione. Omer Levy e Yoav Goldberg (Bar-Ilan University, Israele), NeurIPS 2014, “Neural word embedding as implicit matrix factorization”. Risultato tecnico: skip-gram con negative sampling è equivalente, nel limite, alla fattorizzazione di una matrice di shifted PMI. Conseguenza: word2vec non è “magia neurale”, è una nuova interfaccia su una vecchia idea. Levy-Goldberg-Dagan 2015, TACL 3: 211-225, mostrano che molte differenze fra word2vec, GloVe e PPMI tradizionale spariscono se si controllano gli hyperparametri.
2017 — Bojanowski et al., fastText. Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomáš Mikolov (FAIR), TACL 5: 135-146, “Enriching word vectors with subword information”. Estende word2vec a character n-gram: una parola è la somma dei vettori dei suoi n-gram. Risolve OOV — out-of-vocabulary — e cattura morfologia. Per lingue agglutinanti come il finlandese o il turco, salto qualitativo.
2018 — Peters et al., ELMo. Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer, AI2 e University of Washington, NAACL 2018, “Deep contextualized word representations”. L’idea: invece di un vettore statico per parola, addestriamo una rete LSTM bidirezionale a predire parole, ed estraiamo gli stati nascosti come embedding contestuali. La stessa parola riceve vettori diversi in contesti diversi.
2018 — Devlin et al., BERT. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, Google, NAACL 2019 (preprint ottobre 2018), “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. Stesso principio di ELMo, ma su transformer-2017 e con un task di pre-training nuovo: masked language modeling — si nasconde casualmente il 15% dei token e si chiede al modello di indovinarli. BERT diventa lo standard de facto per task discriminativi NLP fino al 2020.
2018-2020 — Radford et al., GPT-1/2/3. Alec Radford e collaboratori a OpenAI propongono la versione decoder-only autoregressive: invece di mascherare token e predirli, si predice sempre il prossimo. GPT-1 (giugno 2018), GPT-2 (febbraio 2019), GPT-3 (maggio 2020). GPT-3 con 175 miliardi di parametri inaugura la scala foundation model. Vedi gpt3-2020.
2020 — Bender-Koller, octopus. Emily Bender (UW) e Alexander Koller (Saarland), ACL 2020, “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”. Esperimento mentale del polipo. Argomento contro l’identificazione tra distributional semantics e natural language understanding: la forma da sola, per quanto bene padroneggiata, non basta a costituire significato pieno.
2023 — il ritorno della disputa. Chomsky-Roberts-Watumull, NYT, 8 marzo 2023, The False Promise of ChatGPT. Piantadosi (UC Berkeley), preprint LingBuzz aprile 2023, Modern language models refute Chomsky’s approach to language. La disputa rinasce esattamente sul terreno distribuzionale: gli LLM mostrano che dal puro input distribuzionale emerge una competenza linguistica vasta, dunque la poverty of stimulus chomskyana è indebolita.
L’intuizione: due angoli prima della meccanica
Sezione intitolata “L’intuizione: due angoli prima della meccanica”Angolo linguistico: il significato come uso
Sezione intitolata “Angolo linguistico: il significato come uso”Immagina di dover insegnare a un alieno che non parla nessuna lingua umana cosa vuol dire “ostetrica”. Hai due opzioni. Prima opzione: dargli un dizionario. Lì leggerà “donna che assiste i parti”. Ma ora deve sapere cosa è una donna, cosa è un parto, cosa vuol dire assistere. Apre il dizionario su quelle parole e trova altre parole. Il dizionario è circolare: parole spiegate con parole.
Seconda opzione: dargli un milione di frasi reali in cui compare “ostetrica”. Frasi tipo “l’ostetrica le tenne la mano durante le contrazioni”, “ha studiato per diventare ostetrica all’Università di Bologna”, “la cooperativa di ostetriche organizza corsi pre-parto”. L’alieno noterà che “ostetrica” co-occorre con “parto”, “contrazioni”, “donne”, “ospedale”, “neonato”, “assistere”. Da queste co-occorrenze costruirà una rappresentazione interna di “ostetrica” come un nodo in una rete di concetti correlati. Non saprà ancora cosa sia un parto in senso pieno — non ne ha mai visto uno — ma saprà che “ostetrica” si distingue da “barista”, da “avvocato”, da “geologo”, per il fatto che vive in un quartiere di parole diverso.
Questa è la distributional hypothesis. Non è una teoria del significato pieno: è una teoria di una sua componente importante, quella che si manifesta nella distribuzione dei contesti linguistici. È la differenza fra un dizionario tradizionale, che ti dà definizioni, e un thesaurus o un Wikipedia attraversato per link interni: il significato emerge dal grafo delle relazioni.
Firth e Harris non avevano metafore tecnologiche per dirlo. Lo dicevano da linguisti pratici: per descrivere il vocabolario di una lingua poco documentata, raccogli corpora, conta cosa va con cosa, e troverai struttura semantica. Non avevano formalismo né compute. Avevano un’idea, e uno scetticismo verso l’idea opposta — quella che il significato risieda in qualche entità mentale interna, da introspettare.
Angolo geometrico: parole come punti in uno spazio
Sezione intitolata “Angolo geometrico: parole come punti in uno spazio”Adesso cambia angolo. Invece che pensare al significato come a una rete, pensa a uno spazio. Un piano, per visualizzare; o uno spazio a 300 dimensioni, per fare sul serio. Ogni parola è un punto in quello spazio. La distanza fra due punti misura quanto le due parole siano usate in modo simile.
In questo spazio, “cane” e “gatto” sono vicini. Anche “cane” e “guinzaglio”. “Cane” e “tavolino” sono lontani. Ma anche “cane” e “felino” sono vicini, anche se non co-occorrono mai direttamente: co-occorrono con le stesse altre parole — animale, domestico, pelo, zampe — quindi il loro vicinato è simile e finiscono a poca distanza.
L’altra cosa interessante di uno spazio geometrico è che ha direzioni, non solo distanze. Una direzione è una mossa: “come passo da X a Y”. Se la mossa “da uomo a re” è la stessa direzione di “da donna a regina”, allora quella direzione codifica qualcosa che si potrebbe chiamare royalty. Se la mossa “da gatto a felino” è la stessa di “da cane a canide”, quella direzione codifica ipernimia (la relazione fra una categoria specifica e quella più generale).
Word2vec rende esplicito questo: nella geometria dello spazio costruito da skip-gram, esistono direzioni interpretabili. La famosa equazione vec(“king”) - vec(“man”) + vec(“woman”) ≈ vec(“queen”) dice: parto da “king”, tolgo la componente “maschio” (la mossa da “uomo” a niente), aggiungo la componente “donna”, e atterro vicino a “queen”. È un parallelogramma in 300 dimensioni.
L’angolo geometrico è esistito in nuce in Salton 1975 e in LSA 1990, ma è esploso con word2vec 2013 perché il dato dell’analogia è stato il primo a essere visivamente convincente per chi non veniva da NLP. L’angolo linguistico è la motivazione, l’angolo geometrico è l’implementazione, e i due si parlano.
La meccanica
Sezione intitolata “La meccanica”Quattro modelli, in ordine cronologico, illustrano la traiettoria tecnica.
Latent Semantic Analysis (LSA, 1990)
Sezione intitolata “Latent Semantic Analysis (LSA, 1990)”Step 1. Raccogli un corpus di D documenti (per Deerwester 1990, qualche centinaio). Estrai un vocabolario di V parole (qualche migliaio).
Step 2. Costruisci la matrice term-document X di dimensione V × D. Cella X[i,j] = numero di volte che la parola i compare nel documento j. Tipicamente si pesa con TF-IDF: Term Frequency per la cella moltiplicata per Inverse Document Frequency, log(D / numero di documenti che contengono la parola). Effetto: parole molto comuni (il, di, è) ricevono peso basso, parole più informative ricevono peso alto.
Step 3. Calcola la Singular Value Decomposition: X = U Σ Vᵀ. U è V × V, Σ è diagonale con V valori singolari ordinati per grandezza, V è D × D.
Step 4. Tronca al rango k (tipicamente 100-300): tieni solo le prime k colonne di U, i primi k valori singolari, le prime k righe di Vᵀ. Ottieni X_k = U_k Σ_k V_kᵀ, l’approssimazione di rango k di X.
Step 5. Il vettore della parola i è la i-esima riga di U_k Σ_k — un vettore a k dimensioni. Il vettore del documento j è la j-esima colonna di Σ_k V_kᵀ. Misuri similarità con cosine similarity.
Cosa fa il troncamento. Le componenti corrispondenti ai valori singolari grandi catturano i pattern dominanti di co-occorrenza. Le componenti corrispondenti ai valori piccoli sono rumore. Buttare i valori piccoli è una compressione lossy che, sperabilmente, butta più rumore che segnale. È un atto di fede, ma empiricamente funziona.
PMI e PPMI
Sezione intitolata “PMI e PPMI”Più semplice di LSA, spesso più efficace per task di sinonimia. Per ogni coppia (parola w, contesto c), definisci:
dove P(w, c) è la probabilità che w e c co-occorrano (nella stessa frase, nella stessa finestra di k parole, eccetera), P(w) e P(c) le probabilità marginali. PMI è positivo se la coppia co-occorre più del previsto sotto indipendenza, negativo se meno. PPMI tronca a zero i negativi: PPMI(w, c) = max(PMI(w, c), 0). La motivazione del troncamento è che le stime di “co-occorrenza meno del previsto” sono rumorose e poco affidabili.
La matrice PPMI di parole per contesti, eventualmente fattorizzata via SVD per ridurla, dà rappresentazioni distribuzionali competitive con word2vec — come Levy-Goldberg-Dagan 2015 mostrano in modo sistematico.
Word2Vec (skip-gram con negative sampling)
Sezione intitolata “Word2Vec (skip-gram con negative sampling)”Lo schema concettuale di skip-gram è: data una parola centrale w, predici le sue parole di contesto (le parole entro una finestra di ±k parole nel testo). Il modello è una rete neurale a un solo strato lineare, senza attivazione. Due matrici di embedding: W per le parole come centro, C per le parole come contesto. Ogni parola ha due vettori (alla fine si tiene solo W).
Il problema computazionale: fare il softmax sull’intero vocabolario di milioni di parole, per ogni occorrenza in un corpus di miliardi di parole, è proibitivo. Soluzione di Mikolov 2013b: negative sampling. Al posto del softmax, addestri un classificatore binario logistico che distingue i veri contesti (positivi) da contesti casuali (negativi), tipicamente cinque negativi per ogni positivo. La perdita su un esempio (w, c_pos, c_neg1, …, c_negk) è:
dove σ è la sigmoide. Spinge il prodotto scalare fra W_w e C_{c_pos} in alto, lo abbassa per i negativi.
Levy-Goldberg 2014 dimostrano che, nel limite di abbastanza dati e con alcune assunzioni, l’ottimo di questa funzione obiettivo coincide con la fattorizzazione di una matrice di shifted PMI: W Cᵀ ≈ PMI - log(k). Word2vec, in altre parole, è LSA su PMI con un altro nome.
CBOW (Continuous Bag-Of-Words) è il duale di skip-gram: predice la parola centrale dalla media dei vettori di contesto. Più veloce, leggermente meno performante su parole rare.
Embedding contestuali (BERT)
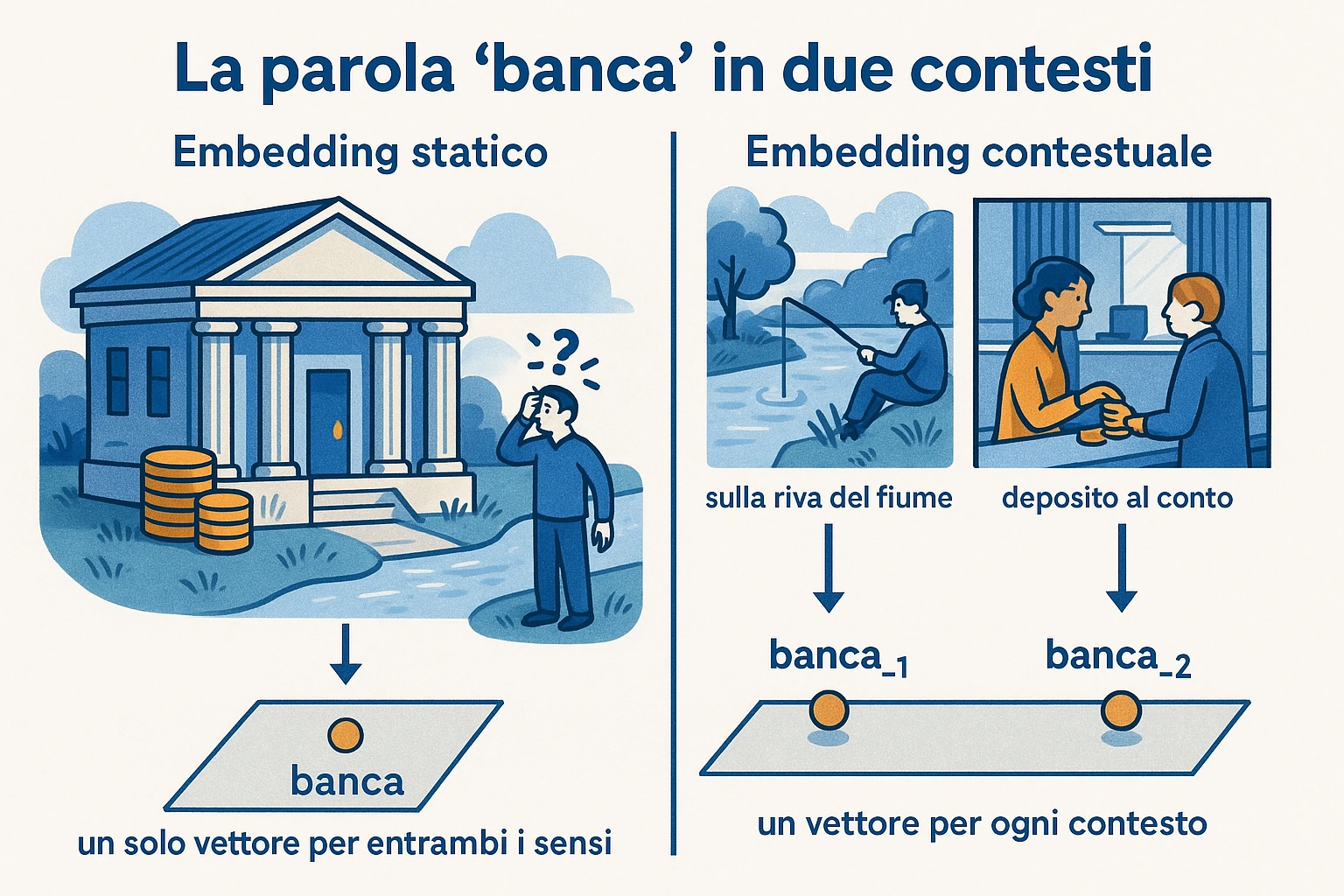
Sezione intitolata “Embedding contestuali (BERT)”In word2vec, ogni parola ha un vettore. Bank ha un solo vettore, qualunque cosa significhi nel contesto specifico. È il problema della polysemy: il vettore è la media dei sensi, e perdi disambiguazione.
ELMo e BERT cambiano regola. Invece di un vettore per parola, hai una funzione che, data una sequenza di parole, restituisce un vettore per ciascuna posizione. La stessa parola in due frasi diverse riceve due vettori diversi.
BERT è un transformer (vedi transformer-2017) bidirezionale a 12 o 24 layer. Pre-training: prendi una frase, sostituisci il 15% dei token con [MASK], chiedi al modello di indovinarli. Il modello vede entrambi i lati, sinistro e destro. La rappresentazione di un token al layer l è una funzione complicata di tutti i token in input, attraverso l applicazioni di multi-head attention (vedi transformer-2017, attention).
Gli embedding contestuali sono ancora distribuzionali nello spirito — il loro significato resta determinato dalla statistica del corpus di addestramento — ma sono più ricchi: catturano dipendenze sintattiche, ruoli tematici, riferimenti pronominali. La parola “lui” in “Mario ha detto a Luigi che lui era stanco” riceve un embedding che riflette l’ambiguità del riferimento; in un contesto disambiguante, l’embedding si sposta verso il referente corretto.

Esempio 1: bank in due contesti
Sezione intitolata “Esempio 1: bank in due contesti”Considera due frasi:
(A) He deposited money at the bank yesterday. (B) He sat by the bank fishing all afternoon.
Le parole vicine a bank in (A): deposited, money. Espandendo a frasi simili nel corpus: deposit, account, vault, ATM, loan, branch, manager, withdraw.
Le parole vicine a bank in (B): sat, fishing. Espandendo: river, water, fish, shore, mud, boat, current, fishing rod.
Sotto la distributional hypothesis, le due banche hanno vicinati distribuzionali quasi disgiunti, dunque significati distinguibili. Word2vec statico ha un solo vettore per bank — fa una media pesata dei due sensi, perdendo l’informazione. BERT, su input (A), produce un vettore per bank vicino al cluster finanziario; su input (B), produce un vettore vicino al cluster fluviale. Stesso simbolo, due posizioni diverse nello spazio.
Il test pratico: se prendi un classificatore lineare addestrato a predire “senso finanziario vs senso fluviale” su embedding BERT della parola bank, l’accuratezza è oltre il 95%. Su embedding word2vec, è poco più del baseline della classe maggioritaria. La differenza è la contestualità.
Esempio 2: il parallelogramma king-queen
Sezione intitolata “Esempio 2: il parallelogramma king-queen”Mikolov 2013 introduce un benchmark di analogie: 19.500 quadruple (a, b, c, d) di forma “a sta a b come c sta a d”. Esempi:
- Athens : Greece :: Tokyo : Japan
- king : man :: queen : woman
- quick : quickly :: slow : slowly
- walking : walked :: swimming : swam
Il test: dato (a, b, c), trova d tale che vec(d) ≈ vec(b) - vec(a) + vec(c), con la restrizione che d sia diverso da a, b, c. Su Google News word2vec, l’accuratezza è sopra il 65% per analogie semantiche e il 70% per quelle morfologiche.
Levy-Goldberg-Dagan 2015 fanno un’osservazione critica. La formula vec(b) - vec(a) + vec(c) cercata fra i vicini di c coincide quasi sempre con la parola che massimizza una combinazione di tre cosine similarity:
con il vincolo d ≠ a, b, c. Il “miracolo dell’aritmetica” è in larga parte un riformulato di una semplice ricerca dei vicini. L’analogia funziona, ma per ragioni più mondane di quelle che il marketing del 2013 suggeriva.
Resta, comunque, un fatto empirico interessante: lo spazio degli embedding ha geometria quasi-lineare su molte categorie. Direzioni interpretabili esistono. Bolukbasi et al. NeurIPS 2016 hanno usato questa proprietà al contrario, identificando una “direzione di genere” e proiettando via i bias indesiderati.
Esempio 3: PMI numerico su un corpus realistico
Sezione intitolata “Esempio 3: PMI numerico su un corpus realistico”Corpus: la English Wikipedia 2015, circa 2 miliardi di parole. Vocabolario filtrato a 100.000 parole (frequenza ≥ 100). Finestra di co-occorrenza: ±5 parole.
Coppia (doctor, hospital). Conteggi:
- count(doctor) ≈ 280.000
- count(hospital) ≈ 180.000
- count(doctor, hospital) nella stessa finestra ≈ 8.500
- Probabilità totale di token N ≈ 2 × 10⁹
P(doctor) ≈ 1.4 × 10⁻⁴, P(hospital) ≈ 9 × 10⁻⁵, P(doctor, hospital) ≈ 4.25 × 10⁻⁶.
PMI = log₂(4.25 × 10⁻⁶ / (1.4 × 10⁻⁴ × 9 × 10⁻⁵)) = log₂(4.25 × 10⁻⁶ / 1.26 × 10⁻⁸) = log₂(337) ≈ 8.4.
Per confronto, la coppia (doctor, banana): count congiunto basso, magari 300, dà PMI vicino a zero o negativo. La coppia (the, doctor): count congiunto alto in valore assoluto, ma anche the ha probabilità marginale enorme, dunque PMI basso.
PPMI di (doctor, hospital) = 8.4. PPMI di (the, doctor) ≈ 0. Interpretazione: la PPMI cattura associazioni informativamente sorprendenti, non semplici co-occorrenze frequenti.
Esempio 3-bis: HAL e la sliding window di Lund-Burgess
Sezione intitolata “Esempio 3-bis: HAL e la sliding window di Lund-Burgess”Per illustrare una variante di costruzione di matrice di co-occorrenza, prendiamo HAL su un mini-corpus didattico:
Il gatto dorme sul divano. Il cane corre nel giardino. Il gatto graffia il divano.
Finestra di co-occorrenza: ±2 parole, peso inverso alla distanza (1 a distanza 1, 0.5 a distanza 2). Vocabolario: {gatto, cane, dorme, corre, divano, giardino, graffia}.
Per il termine gatto, le co-occorrenze sono:
- dorme: a distanza 1 nella prima frase (peso 1) = 1.0
- divano: a distanza 3 nella prima frase (fuori finestra) e a distanza 2 nella terza (peso 0.5) = 0.5
- graffia: a distanza 1 nella terza (peso 1) = 1.0
Per il termine cane:
- corre: a distanza 1 (peso 1) = 1.0
- giardino: a distanza 3 (fuori finestra) = 0
Il vettore di gatto è (0, 0, 1.0, 0, 0.5, 0, 1.0); quello di cane è (0, 0, 0, 1.0, 0, 0, 0). I due hanno cosine bassa, perché co-occorrono con verbi diversi. Questo riflette correttamente, sul mini-corpus, che gatto e cane fanno cose diverse — anche se semanticamente sono entrambi animali domestici. Su un corpus realistico, gatto e cane co-occorrono entrambi con animale, domestico, pet, padrone, veterinario, e la cosine cresce.
L’esempio illustra perché HAL, come tutti i metodi distribuzionali, richiede grandi corpora: la statistica di co-occorrenza diventa informativa solo con abbastanza esempi.
Esempio 4: similarità semantica via cosine
Sezione intitolata “Esempio 4: similarità semantica via cosine”Date due parole cat e dog con vettori word2vec a 300 dimensioni v_cat e v_dog, calcola:
Tipicamente, su Google News word2vec, cos(cat, dog) ≈ 0.76, cos(cat, kitten) ≈ 0.74, cos(cat, refrigerator) ≈ 0.10, cos(cat, tiger) ≈ 0.50. Il pattern: parole semanticamente simili (sinonimi, ipernimi-iponimi prossimi) hanno cosine alta; parole non correlate hanno cosine bassa.
Nota tecnica importante: la cosine non distingue fra similarity e relatedness. cos(doctor, nurse) ≈ 0.50 (relate, non sinonimi); cos(doctor, hospital) ≈ 0.45 (relate, non sinonimi); cos(doctor, physician) ≈ 0.65 (sinonimi). L’embedding distribuzionale mescola i due. Esistono varianti — count-based con SVD, modelli sintatticamente filtrati — che separano meglio i due assi.
Applicazioni pratiche
Sezione intitolata “Applicazioni pratiche”Information retrieval e RAG. Il retrieval augmented generation moderno applica direttamente la distributional hypothesis: per recuperare i documenti rilevanti a una query, calcoli embedding di query e documenti e prendi i top-k per cosine similarity. I modelli di embedding moderni (text-embedding-3 di OpenAI, Cohere embed v3, Voyage AI, Jina v3) sono transformer addestrati con contrastive learning, ma il principio operativo è quello: somiglianza nello spazio = somiglianza nei contesti = somiglianza nei contenuti. Vedi rag-base (in preparazione).
Ricerca semantica. Equivalente a IR ma su catalogo prodotti, FAQ, knowledge base. La distributional hypothesis è il motore: query e item finiscono in uno spazio condiviso, la rilevanza è geometrica.
Classificazione e sentiment analysis. Embedding pre-addestrati come features per classificatori downstream. Pipeline tipica: estrai vettore frase via mean pooling di word2vec, oppure [CLS] di BERT, oppure sentence-BERT, e addestri un classificatore lineare sopra.
Traduzione automatica. I sistemi statistical MT degli anni Duemila usavano allineamenti parola-parola. I sistemi neurali post-2014 (seq2seq, vedi seq2seq-2014) usano embedding di parola e di posizione. Multilingual embeddings — come multilingual BERT, LASER, multilingual sentence encoders — proiettano parole di lingue diverse nello stesso spazio: cat in inglese e gatto in italiano finiscono vicini, perché compaiono in contesti omologhi nei rispettivi corpora.
Knowledge graph completion. Modelli come TransE (Bordes 2013) embedinguno entità e relazioni in modo che vec(head) + vec(relation) ≈ vec(tail) — letteralmente l’analogia king-queen estesa a triplette di knowledge graph.
Clustering di concetti, topic modeling, keyword extraction sono tutte istanze di analisi distribuzionale, eventualmente con apparato bayesiano (LDA) o con autoencoder (BERTopic).
Voice agents e cross-modal. Embedding di audio (wav2vec, Whisper) condividono spazi con embedding di testo. CLIP allinea immagini e testo nello stesso spazio. Stessa cornice distribuzionale, esteso oltre il testo.
Mechanistic interpretability. Probing classifiers (vedi probing (in preparazione)) addestrati sopra le rappresentazioni interne dei transformer recuperano struttura distribuzionale: parti del discorso, sintassi a costituenti, ruoli tematici, perfino tracce di mondi 3D in modelli addestrati su descrizioni di scacchi (Li-Hopkins-Bau 2023) o di geografia (Gurnee-Tegmark 2023). Il risultato di Gurnee-Tegmark 2023 — “Language models represent space and time” — mostra che le rappresentazioni interne di Llama-2 contengono un asse “longitudine” e un asse “latitudine” linearmente recuperabili dalle attivazioni, e che città vicine geograficamente sono vicine in attivazione. È distributional semantics che, scalata, recupera struttura del mondo attraverso il testo che lo descrive.
Dove si rompe
Sezione intitolata “Dove si rompe”Sezione lunga, perché le critiche sono parte integrante del programma.
Octopus e symbol grounding
Sezione intitolata “Octopus e symbol grounding”Bender-Koller 2020, Climbing towards NLU, propongono l’esperimento mentale del polipo. Due isolani, A e B, comunicano via cavo telegrafico. Un polipo molto intelligente intercetta i messaggi e impara, per pura analisi distribuzionale, a continuare le conversazioni in modo plausibile. A un certo punto A scrive “Sto per essere attaccato da un orso, dimmi come usare i bastoni che ho qui per difendermi”. B in quel momento è andato a pesca; il polipo, prendendo il suo posto, risponde con qualcosa che assomiglia statisticamente a una risposta plausibile, ma A muore perché la risposta è generica e non grounded nella scena reale.
L’argomento di Bender-Koller: la forma — la distribuzione — non basta a costituire significato pieno. Il significato richiede ancoraggio a referenti del mondo, intenzioni comunicative, comprensione delle situazioni. Un sistema puramente distribuzionale, per quanto bravo, manca di questo ancoraggio.
Lo stesso punto, in versione 1990, era stato fatto da Stevan Harnad in Physica D 42: 335-346, The Symbol Grounding Problem. Un sistema simbolico chiuso, in cui i simboli sono spiegati solo da altri simboli, è un dizionario-cinese-cinese: utile a un parlante che già conosce il cinese, inutile a chi parte da zero. Harnad chiede una connessione causale fra simboli e percezione — grounding sensori-motorio. Vedi symbol-grounding.
La risposta empirista contemporanea (Pavlick 2023, “Symbols and grounding in large language models”) è più morbida: gli LLM moderni non sono puramente disembodied — sono addestrati su testo che descrive il mondo prodotto da agenti embodied, dunque i loro embedding ereditano grounding indiretto. Inoltre, modelli multimodali (CLIP, GPT-4V) hanno grounding diretto su immagini. Il dibattito è aperto.
Distributional ≠ meaning
Sezione intitolata “Distributional ≠ meaning”Equivalenza pericolosa da bloccare: “distributional semantics = meaning”. È falso in senso forte. La distributional hypothesis copre una componente del significato — quella che si manifesta nelle relazioni linguistiche fra parole — ma non copre:
- Riferimento: Napoleone non è un cluster di co-occorrenze, è una persona realmente vissuta.
- Verità: che l’acqua bolle a 100 °C sia vero o falso non si decide distribuzionalmente.
- Intenzioni e atti linguistici (vedi atti-linguistici): “dichiaro chiusa la seduta” fa qualcosa al mondo che non è statistica di co-occorrenze.
- Esperienza fenomenica: il sapore del caffè non è recuperabile dalle parole con cui se ne parla.
Polysemy collassata negli embedding statici
Sezione intitolata “Polysemy collassata negli embedding statici”Word2vec e GloVe danno un solo vettore per parola. Bank finanziario e bank fluviale finiscono nello stesso punto, una media pesata dei sensi. Per task in cui la disambiguazione conta, gli embedding statici sono inadeguati. ELMo e BERT risolvono parzialmente, ma anche lì la separazione dei sensi è soft, non discreta: non ti danno un’enumerazione “senso 1, senso 2”, ti danno una posizione nello spazio che varia continuamente con il contesto.
Compositionality
Sezione intitolata “Compositionality”Il significato di una frase non è la media dei significati delle parole. Il cane morde l’uomo e l’uomo morde il cane hanno gli stessi vettori parola; in word2vec mediato, lo stesso vettore frase. Mitchell-Lapata, Cognitive Science 34(8): 1388-1429 (2010), studiano operazioni di composizione vettoriale (somma, prodotto, tensor product); risultato: somma e prodotto catturano something, ma non struttura argomentale. Sentence-BERT (Reimers-Gurevych 2019) addestra una rete sopra BERT con loss contrastiva su coppie di frasi annotate — risultato migliore per task di paraphrase, ma sempre con limiti compositionali.
Il problema, in linea generale, è che gli embedding sono bag of senses: il significato di “il cane morde l’uomo” è la somma di cane, morde, uomo in qualche peso, e perdere l’ordine perde la struttura. I transformer mitigano il problema con attention, ma non lo risolvono in linea di principio.
Bias e contaminazione sociale
Sezione intitolata “Bias e contaminazione sociale”Bolukbasi et al. NeurIPS 2016, Man is to computer programmer as woman is to homemaker?: il vettore word2vec di Google News, su analogie occupazionali, rispecchia stereotipi di genere. Caliskan-Bryson-Narayanan, Science 356(6334): 183-186 (2017), generalizzano: gli embedding catturano associazioni implicite in stile Implicit Association Test — European-American names sono associati a valenze positive più che African-American names, eccetera.
Il punto, dal lato distribuzionale, è coerente: se nei testi di addestramento programmer co-occorre più con pronomi maschili che femminili, l’embedding eredita la statistica. Il problema è che usare l’embedding per decisioni downstream (filtrare CV, suggerire prodotti) propaga il bias. Le tecniche di debiasing (Bolukbasi 2016) proiettano via la “direzione di genere”, con efficacia controversa (Gonen-Goldberg 2019, Lipstick on a Pig).
Data efficiency: il bambino vs il foundation model
Sezione intitolata “Data efficiency: il bambino vs il foundation model”Un bambino di sei anni padroneggia un vocabolario di 5.000-10.000 parole avendo udito dell’ordine di decine di milioni di parole, in interazione embodied multimodale. GPT-3 è addestrato su 300 miliardi di token, quattro o cinque ordini di grandezza in più. Se l’argomento di Landauer-Dumais 1997 (“LSA risolve Plato’s problem perché impara da quanto leggono i bambini”) era forte nel 1997, oggi è indebolito: i foundation model hanno bisogno di molte più parole, non meno, per arrivare a una competenza confrontabile, e neanche con quel volume catturano cose che il bambino padroneggia da subito (causalità, intenzioni altrui, manipolazione fisica). Vedi anche grammatica universale per la replica chomskyana sul poverty of stimulus.
Antonimi vicini, sinonimi lontani
Sezione intitolata “Antonimi vicini, sinonimi lontani”Un’anomalia che disturba chi pratica retrieval su embedding. Hot e cold hanno cosine alta, perché compaiono in contesti quasi identici (“the weather is ___”, “the soup is ___”, “the day was ___”). La distributional hypothesis non distingue antonimia da sinonimia: entrambe vivono in contesti omologhi. Per task di sentiment o di disambiguazione di valenza, questa è una fonte sistematica di errori. Tecniche di mitigazione esistono (addestramento contrastivo con coppie di antonimi, retrofitting su lessicali come WordNet), ma il problema strutturale resta.
Specularmente, physician e doctor sono sinonimi a tutti gli effetti, ma se i due termini compaiono in registri diversi (medicale-tecnico vs colloquiale) i loro vicinati distribuzionali divergono e la cosine può essere meno alta del previsto. Sinonimi lontani.
Negazione e quantificazione
Sezione intitolata “Negazione e quantificazione”La distributional hypothesis ha la nota cieca per la negazione. He is happy e he is not happy hanno overlap distribuzionale altissimo: tutte le parole sono uguali tranne not. Embedding statici mediati danno vettori frase quasi identici. Embedding contestuali fanno meglio, ma anche BERT fatica su negazioni complesse (Ettinger 2020, What BERT is not: i probing test mostrano che BERT su negazione perde sistematicamente). Per agenti che ragionano su istruzioni che includono “non fare X” o “X solo se Y”, la pipeline non può affidarsi solo a embedding similarity.
Stesso discorso per quantificatori (alcuni, tutti, nessuno) e modali (deve, può, dovrebbe). La distribuzione locale non li distingue bene; la pragmatica e la logica sì.
Equivalenze pericolose da bloccare
Sezione intitolata “Equivalenze pericolose da bloccare”Cinque, in ordine crescente di sottigliezza.
-
“LLM = LSA scaled up”. Falso come equivalenza tecnica. BERT non usa SVD, usa attention multi-layer. La differenza non è solo di scala: è architetturale. Filiazione concettuale sì, equivalenza no.
-
“Word2vec ha capito le analogie”. Sovra-interpretazione. Le analogie funzionano perché lo spazio degli embedding ha geometria quasi-lineare su molte categorie. La struttura non è capita dal modello, è proprietà emergente della statistica del corpus. Vedi Levy-Goldberg-Dagan 2015 per la riduzione a cosine search.
-
“Embedding similarity = synonymy”. Analogia operativa con caveat. Cosine alta indica vicinanza distribuzionale, che mescola sinonimia, ipernimia, antonimia (gli antonimi spesso co-occorrono!) e relatedness. Per applicazioni che richiedono distinzione fine, servono modelli specializzati o post-processing.
-
“Distributional semantics = meaning”. Confutato sopra. Cattura una componente, non il tutto. Bender-Koller octopus.
-
“Foundation models ci dicono che gli umani imparano per distribuzione”. Inferenza errata. Il fatto che un sistema artificiale risolva un problema con metodo X non implica che gli umani usino X per risolverlo. Aerei volano ma non agitano le ali. La distributional learning è una via possibile, non la via umana — anche se Landauer-Dumais 1997 e Piantadosi 2023 sostengono che il margine sia più piccolo di quanto Chomsky abbia creduto.
La disputa Chomsky-Piantadosi e la posta in gioco
Sezione intitolata “La disputa Chomsky-Piantadosi e la posta in gioco”Vale la pena soffermarsi sulla disputa che dal 2023 ha riacceso questioni che la disciplina sembrava avere archiviato, perché la posta in gioco è precisamente la portata della distributional hypothesis.
Da un lato, Chomsky-Roberts-Watumull, sul New York Times dell’8 marzo 2023, scrivono che gli LLM “ingurgitano enormi quantità di dati, ne cercano pattern e diventano sempre più competenti nel generare output statisticamente probabili — un linguaggio e pensiero apparentemente umani”. La critica è duplice. Primo, gli LLM sarebbero incapaci di distinguere il possibile dall’impossibile linguistico: addestrati su una “lingua marziana” che viola universali umani li imparerebbero altrettanto bene. Secondo, gli LLM produrrebbero “descrizione e predizione” ma non “spiegazione causale”. Pertanto, non sarebbero modelli del linguaggio umano.
Dall’altro lato, Steven Piantadosi, psicolinguista bayesiano a UC Berkeley, in un preprint LingBuzz dell’aprile 2023 intitolato Modern language models refute Chomsky’s approach to language, risponde punto per punto. Primo: l’esistenza di LLM che imparano dal puro input distributivo dimostra che il linguaggio è apprendibile da quell’input — il che indebolisce l’argomento centrale della poverty of stimulus, secondo cui l’input ricevuto dai bambini sarebbe troppo povero per supportare l’apprendimento senza un dispositivo innato dedicato. Secondo: gli LLM danno predizioni granulari su molti fenomeni linguistici (giudizi di accettabilità, gradiente di grammaticalità, effetti garden-path), che la grammatica chomskyana classica non dava. Terzo: l’argomento “non è scienza, è solo predizione” è incoerente con come funziona scienza moderna — la teoria della relatività generale “predice” senza una spiegazione causale ulteriore, e non per questo è non-scientifica.
Chi ha ragione? Per i fini di questo capitolo, il punto interessante è dove cade la linea. Piantadosi non sostiene che gli LLM siano modelli psicologici dei bambini umani: sostiene che la loro esistenza dimostra che la poverty of stimulus è meno potente di quanto creduto, e che pertanto la motivazione storica per postulare una grammatica universale specifica si indebolisce. Chomsky non sostiene che gli LLM non funzionino: sostiene che funzionino in un modo che non illumina la natura del linguaggio umano, perché un modello che imparerebbe anche linguaggi marziani impossibili non sta catturando i vincoli specifici della facoltà linguistica umana.
La distributional hypothesis è il terreno su cui la disputa si gioca. Se l’apprendimento puramente distribuzionale di un sistema artificiale produce competenza linguistica vasta, il margine di lavoro che resta a un dispositivo innato dedicato si restringe. Resta lo spazio degli universali — perché tutte le lingue umane abbiano certe proprietà — e quello dell’efficienza dei dati — perché un bambino impari con quattro o cinque ordini di grandezza meno parole di GPT-3. Sono spazi non vuoti, ma sono più stretti di prima del 2018.
Da un altro angolo, l’esperimento dei polipi di Bender-Koller mantiene la sua forza. Anche se gli LLM imparano benissimo a continuare conversazioni, restano sistemi disembodied. Il fatto che funzionino in molti task non implica che abbiano capito in senso pieno. La distributional semantics cattura una componente del significato — la grande, importante, utile componente — ma non l’intero. Questo è il consenso emergente fra chi ha digerito sia il successo degli LLM sia i limiti residui.
Cosa portare a casa per chi costruisce sistemi
Sezione intitolata “Cosa portare a casa per chi costruisce sistemi”Tre principi operativi per chi lavora su retrieval, embedding, RAG, agent coding.
Primo, la similarità di embedding è una stima, non un oracolo. Cosine alta indica vicinanza distribuzionale, che correla con vicinanza semantica ma non coincide con essa. Antonimi possono avere cosine alta. Parole correlate ma non sinonime hanno cosine media. Per applicazioni che richiedono distinzione fine — physician vs charlatan, healthy vs unhealthy — un retrieval basato su pure cosine può fallire in modi sorprendenti. Reranker a granularità maggiore (cross-encoder, modelli di ranking specializzati) sono spesso necessari nello stack RAG.
Secondo, l’embedding eredita il corpus. Se i tuoi documenti vivono in un dominio specifico (medico, legale, tecnico-aziendale), gli embedding pre-addestrati su web generico possono mancare di sensibilità ai termini chiave. Fine-tuning di embedding su corpus dominio-specifico, o uso di modelli specializzati (BioBERT, LegalBERT, fastText specializzati), sposta i vettori in modo più informativo. La distributional hypothesis è locale al dominio: due termini sono simili rispetto al corpus su cui hai addestrato.
Terzo, i bias del corpus diventano bias del sistema. Se il tuo embedding model è stato addestrato su web del 2020, eredita le associazioni di quell’anno. Aggiornamenti periodici e auditing dei bias sono parte di una pipeline di produzione matura. Vedi privacy-modelli (in preparazione) e i capitoli su sicurezza per dettagli.
Quarto, e meta-principio: la distributional hypothesis è uno strumento, e come ogni strumento ha campo di applicabilità. Funziona meravigliosamente per recuperare documenti rilevanti, classificare testo, identificare cluster tematici, allineare lingue. Non funziona, da sola, per ragionamento causale, comprensione di intenzioni, esecuzione di azioni nel mondo. Per quei compiti, gli LLM moderni combinano la base distribuzionale con altri meccanismi (test-time compute, tool use, planning), come si vedrà nelle Parti su reasoning, agenti e harness.
Collegamenti
Sezione intitolata “Collegamenti”- Linguaggio come strumento del pensiero: dove si tratta del rapporto fra linguaggio e cognizione, terreno su cui Whorf e LOT giocano una partita parallela a quella distribuzionale di Firth-Harris.
- Grammatica universale di Chomsky: l’antagonista naturale. Chomsky parte da Harris ma rompe; la distributional semantics continua il programma harrisiano dopo la rottura.
- Sapir-Whorf: un’altra famiglia di tesi sul rapporto lingua-cognizione, indipendente da quella distribuzionale.
- Atti linguistici di Austin e Searle: un livello del significato — fare cose con le parole — che la distributional hypothesis non cattura.
- Symbol grounding (Harnad): la critica filosofica più nitida ai modelli puramente simbolici-distribuzionali.
- Stanza cinese di Searle: variante filosofica anteriore della stessa critica.
- Word2vec 2013: il momento storico in cui la distributional semantics entra in produzione su larga scala.
- BERT e GPT 2018-2019: la transizione a embedding contestuali.
- ponte-distribuzionale-embeddings (in preparazione): il bridge dedicato all’eredità diretta verso embedding e foundation model.
- vettori-spazi (in preparazione): il fondamento matematico dello spazio in cui gli embedding vivono.
- norme-distanze (in preparazione): cosine, euclidean, dot product — quale usare e perché.
- embedding-concetto (in preparazione): trattazione generale dell’idea di spazio di embedding.
- mech-interp-intro (in preparazione): l’analisi delle rappresentazioni interne, che recupera struttura distribuzionale dentro i transformer.
- rag-base (in preparazione): il caso applicativo più diffuso della distributional hypothesis nella pratica agentica.
Eredità oggi
Sezione intitolata “Eredità oggi”I foundation model del 2026 sono distributional semantics scalata in tre direzioni ortogonali: da statico a contestuale, da co-occorrenza locale a multi-layer attention, da parola a tutto. Vale la pena svolgere ciascuna di queste direzioni, perché capirle aiuta a leggere correttamente cosa fanno e cosa non fanno i sistemi che usiamo ogni giorno.
Da statico a contestuale. Word2vec produce un vettore per parola, indipendente dal contesto. ELMo, BERT e GPT producono vettori che dipendono dalla frase intera, dalla finestra, dal documento. Tecnicamente, il modello è una funzione che prende una sequenza di token in input e produce, per ogni posizione, un vettore in uscita. La stessa stringa “bank” in due frasi diverse produce due vettori. Il vantaggio è la disambiguazione di polysemy; il prezzo è che non hai più un dizionario fisso di vettori, hai un modello da invocare per ogni nuovo testo. Per applicazioni di retrieval su corpora statici questo è un costo gestibile; per applicazioni real-time è un costo da budgetare.
Da co-occorrenza locale a multi-layer attention. Word2vec guarda finestre di 5 o 10 parole. BERT guarda fino a 512 token; modelli più recenti arrivano a 200.000 e oltre. Ma la differenza non è solo la finestra: è la composizione. In word2vec, il vettore finale è una somma di interazioni a uno strato. In BERT, ogni token al layer l è una somma pesata di tutti i token al layer l-1, dove i pesi sono calcolati da query-key dot product. Dopo dodici o ventiquattro layer, l’informazione si è ridistribuita in modo difficile da seguire analiticamente — è il regno della mechanistic interpretability. Quello che si sa è che le rappresentazioni intermedie codificano sintassi, ruoli tematici, riferimento, e perfino tracce semantiche del mondo descritto.
Da parola a tutto. La distributional hypothesis era pensata per parole. CLIP (Radford et al. 2021) la estende a coppie immagine-testo: due bracci della rete, uno per immagini e uno per testo, addestrati con loss contrastiva su 400 milioni di coppie scaricate dal web. Il risultato è uno spazio condiviso in cui un’immagine di un gatto è vicina alla stringa “a photo of a cat”. Wav2vec, HuBERT, Whisper fanno la stessa cosa per audio. Stable Diffusion, Imagen e i modelli di generazione testo-a-immagine sfruttano embedding text-image condivisi per condizionare la generazione. La cornice distribuzionale è la stessa: due cose sono vicine nello spazio se compaiono in contesti simili, dove “contesto” diventa più liberale che “parole vicine in un testo”.
Embedding API e RAG. Provider commerciali — OpenAI, Cohere, Voyage, Jina, Mistral — espongono modelli di embedding tramite API. Input: una stringa di testo. Output: un vettore a 1.024 o 1.536 o 3.072 dimensioni. Costo per token tre o quattro ordini di grandezza inferiore alla generazione. Uso tipico: indicizzi un corpus calcolando un embedding per ogni chunk, salvi i vettori in un database vettoriale (Pinecone, Weaviate, Qdrant, pgvector), e a query time recuperi i top-k per cosine similarity. Questa pipeline è la spina dorsale del retrieval augmented generation. È, letteralmente, distributional semantics applicata in produzione su scala industriale.
Mechanistic interpretability. La promessa di leggere un modello come un programma — vedi mech-interp-intro (in preparazione) — passa per la lettura delle rappresentazioni interne. Sparse autoencoders (Anthropic 2023, Bricken et al.; OpenAI 2024) decompongono le attivazioni in features monosemantiche: direzioni nello spazio che corrispondono a concetti interpretabili (la presenza di codice Python, di una città italiana, di un sentimento di rabbia). Le features sono identificabili perché si attivano sistematicamente in contesti distribuzionalmente coerenti. È la distributional hypothesis applicata non al corpus, ma alle attivazioni del modello.
Multilingualità. Modelli come multilingual BERT, XLM-R, LASER, e i sentence encoder Cohere multilingual e OpenAI text-embedding-3, addestrano un singolo modello su corpora di decine o centinaia di lingue. Il risultato sorprendente: parole semanticamente equivalenti in lingue diverse finiscono vicine nello spazio. cat (inglese) e gatto (italiano) e кошка (russo) hanno embedding cosine-simili, perché compaiono in contesti omologhi nei rispettivi corpora. Questo permette traduzione zero-shot, retrieval cross-lingua, e classificazione su lingue con poco labelled data. Tecnicamente è ancora distributional, ma su un corpus che attraversa le lingue.
Limiti dell’eredità. Nonostante la potenza, restano i limiti che la distributional hypothesis aveva fin dall’inizio. Bender-Koller octopus vale anche per GPT-4. I bias distribuzionali del corpus di addestramento si propagano. La compositionality strutturale (chi morde chi) non è perfetta. Il grounding sensori-motorio è indiretto, mediato dal testo. I sistemi multimodali ne risolvono parzialmente alcuni; restano altri. Conoscere i limiti dell’antenato aiuta a leggere quelli del discendente.
Per andare oltre
Sezione intitolata “Per andare oltre”- Harris, Z. (1954), “Distributional structure”, Word 10(2-3): 146-162. Il testo fondante. Breve, non tecnico, leggibile.
- Firth, J. R. (1957), “A synopsis of linguistic theory, 1930-1955”, in Studies in Linguistic Analysis, Blackwell. Per la frase celebre nel suo contesto originale.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G., Dean, J. (2013), “Distributed representations of words and phrases and their compositionality”, NeurIPS. Il paper word2vec di riferimento, con negative sampling e analogie.
- Levy, O., Goldberg, Y., Dagan, I. (2015), “Improving distributional similarity with lessons learned from word embeddings”, TACL 3: 211-225. La demistificazione tecnica: word2vec, GloVe, PPMI, stessa famiglia.
- Bender, E. M., Koller, A. (2020), “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”, ACL. La critica filosofica contemporanea più puntuale, con l’esperimento del polipo.
- Manning, C., Raghavan, P., Schütze, H. (2008), Introduction to Information Retrieval, Cambridge University Press. Capitoli 6 e 18 trattano vector space model e LSA con la chiarezza didattica del manuale Stanford.