Spazi di embedding e direzioni semantiche
Un embedding è una mappa da oggetti discreti a vettori in R^d, addestrata perché la geometria racconti qualcosa di utile. Tutto ciò che un modello neurale “capisce” passa di qui.

Perché questo capitolo
Sezione intitolata “Perché questo capitolo”Un transformer non vede parole. Non vede pixel. Vede vettori. La traduzione fra il mondo discreto delle cose con un nome (token, parole, immagini, utenti, prodotti, nodi di un grafo) e il mondo continuo dell’algebra lineare si chiama embedding, ed è il primo strato di ogni LLM, di ogni motore di retrieval, di ogni sistema di raccomandazione moderno. Capire bene questo passaggio non è una formalità: è il punto in cui si decide cosa il modello potrà mai distinguere e cosa rimarrà confuso.
C’è anche una ragione operativa più immediata. Una pipeline RAG (Retrieval Augmented Generation) si rompe quasi sempre per ragioni geometriche: chunking sbagliato, dimensione inadeguata, mismatch fra encoder usato in indicizzazione e in query, anisotropia che gonfia il cosine, bias del modello scelto. Nessuna di queste rotture è risolvibile guardando i log dell’LLM: vivono nello spazio di embedding, e si vedono solo se si sa cosa cercare.
L’embedding è anche il punto in cui idee provenienti da campi diversi convergono in un oggetto unico. Il linguista distribuzionale degli anni cinquanta, lo statistico bayesiano, l’informatico che disegna sistemi di raccomandazione e l’ingegnere ML che addestra un transformer si trovano davanti alla stessa matrice E, anche se la chiamano in modi diversi e la giustificano con ragioni diverse. Capire cosa significhino le sue righe è capire una buona parte di cosa fa, e di cosa non fa, un sistema neurale moderno.
Il capitolo ha tre scopi, in ordine. Costruire un’intuizione robusta di cosa è (e cosa non è) un embedding. Mostrare la meccanica minima — lookup, gradiente, dimensione, contextual vs static, pooling per frasi — senza ricorrere ad algebra lineare avanzata. E dare un atlante operativo di dove si rompe, perché il novanta per cento del lavoro pratico con embedding è negoziare con i loro fallimenti silenziosi.
Contesto
Sezione intitolata “Contesto”Il termine embedding in questa accezione è di Bengio, Ducharme, Vincent, Jauvin (Yoshua Bengio, professore canadese di deep learning) nel paper A Neural Probabilistic Language Model (JMLR 2003), che propone di addestrare insieme un language model e una matrice C ∈ R^{V×m} che assegna a ogni parola del vocabolario un vettore m-dimensionale. L’idea è ripresa e popolarizzata da Tomáš Mikolov, allora a Google, con Efficient Estimation of Word Representations in Vector Space (workshop ICLR 2013) — il paper che chiameremo word2vec — che mostra le famose analogie vettoriali (king − man + woman ≈ queen). Nello stesso anno escono GloVe di Jeffrey Pennington, Richard Socher e Christopher Manning a Stanford (EMNLP 2014), basato su fattorizzazione della matrice di co-occorrenza, e fastText di Piotr Bojanowski (Facebook AI, 2017) che aggiunge sub-word units.
La svolta successiva è il passaggio da static a contextual: ELMo di Matthew Peters (AI2, NAACL 2018) usa un biLSTM per produrre embedding che dipendono dalla frase intorno, e BERT di Jacob Devlin et al. (Google AI Language, NAACL 2019), il paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, lo standardizza dentro l’architettura transformer. Da qui la trasformazione di BERT in encoder di frasi tramite training siamese, opera di Nils Reimers e Iryna Gurevych (TU Darmstadt) nel paper Sentence-BERT (EMNLP 2019), apre la strada all’uso degli embedding come retrieval primitive su scala industriale.
Storia minima in dieci righe
Sezione intitolata “Storia minima in dieci righe”- 2003: Bengio et al., A Neural Probabilistic Language Model. Primi word embedding appresi end-to-end come parte di un language model neurale.
- 2008: Ronan Collobert e Jason Weston (NEC Labs), A Unified Architecture for Natural Language Processing. Embedding come feature riutilizzabile su più task (multitask learning).
- 2013: Mikolov et al., word2vec. Skip-gram, CBOW, negative sampling. Embedding diventano commodity.
- 2014: Pennington, Socher, Manning, GloVe. Alternativa basata su fattorizzazione di matrice di co-occorrenza.
- 2017: Bojanowski et al., fastText. Sub-word units per gestire parole out-of-vocabulary e morfologia ricca.
- 2018: Peters et al., ELMo. Primo embedding contextual via biLSTM bidirezionale.
- 2019: Devlin et al., BERT. Contextual via masked language modeling su transformer; CLS token come riassunto frase.
- 2019: Reimers, Gurevych, Sentence-BERT. Encoder di frase via training siamese.
- 2021: Radford et al., CLIP. Embedding multimodale text-image via contrastive learning su 400M coppie.
- 2022-2026: E5, BGE, GTE, text-embedding-3, Cohere v3, Voyage. Encoder universali instruction-tuned, training contrastivo a tre stadi.
Questo capitolo presuppone che il lettore abbia attraversato vettori e spazi vettoriali, norme e distanze, prodotto scalare e abbia letto il ponte distribuzionale-embeddings, che costruisce il legame storico fra l’ipotesi distribuzionale di John Firth (“you shall know a word by the company it keeps”, 1957) e gli embedding word2vec. Quel capitolo è il ponte concettuale: da dove viene l’idea che il significato si possa imparare dalle co-occorrenze. Questo capitolo è il concetto operativo: cos’è un embedding come oggetto, come si maneggia, dove si rompe oggi. Niente sovrapposizione: il ponte risponde a “perché funziona in linea di principio”, il concetto operativo risponde a “cosa devo sapere per usarlo bene”.
L’intuizione
Sezione intitolata “L’intuizione”Primo angolo: coordinate per oggetti discreti
Sezione intitolata “Primo angolo: coordinate per oggetti discreti”Immaginiamo di avere mille libri in casa e di voler dire, per ogni coppia, “quanto si somigliano”. Possiamo procedere in due modi. Il modo simbolico: schedare ogni libro con una lista di tag (genere, autore, secolo, lingua) e definire la somiglianza come numero di tag in comune. Funziona, ma i tag sono nostri, fissi, e ogni nuovo aspetto richiede una nuova colonna. Il modo geometrico: dare a ogni libro un punto in uno spazio R^d e chiamare somiglianza la vicinanza fra punti. Ora la somiglianza è un’unica regola — distanza — e il modello può imparare le coordinate da solo se gli mostriamo abbastanza esempi di “questi due libri sono simili” / “questi due no”.
Un embedding è precisamente questo: assegnare coordinate in R^d a oggetti discreti, in modo che “vicino” significhi “simile per qualche scopo”. È un’analogia utile, non un’equivalenza: non c’è uno spazio fisico in cui i libri vivono. Lo spazio R^d è una costruzione matematica e le coordinate sono parametri appresi. Ma è un’analogia che porta lontano, perché tutta l’algebra lineare diventa disponibile: distanze, proiezioni, direzioni, medie, differenze.

Secondo angolo: una rappresentazione comprimibile e differenziabile
Sezione intitolata “Secondo angolo: una rappresentazione comprimibile e differenziabile”C’è un altro modo di vedere la stessa cosa. Una rete neurale opera su numeri reali; vuole derivate. Un token id (42) non ha derivata: cambiare 42 in 43 non è un’operazione continua, è un salto a un altro oggetto. Per fare entrare la cosa-discreta in un sistema differenziabile, la rappresentiamo come vettore one-hot (zero ovunque, uno in posizione 42) e poi la moltiplichiamo per una matrice di pesi E ∈ R^{V×d}. Il risultato è la riga 42 di E. Questi pesi sono parametri come tutti gli altri, e il gradiente della loss rispetto a essi dice: “muovi un poco la riga 42 in questa direzione”.
In questa lettura l’embedding è semplicemente il primo strato lineare di una rete che opera su input categorici, scritto nella forma efficiente che evita di moltiplicare V−1 zeri. Non c’è magia: c’è una matrice di pesi e un’indicizzazione. La magia è cosa quei pesi finiscono per contenere quando vengono addestrati su miliardi di parole. Ed è una magia osservabile: la geometria post-addestramento mostra cluster, direzioni, regolarità — non per imposizione ma come effetto collaterale del compito di language modeling.
Tenere insieme i due angoli è importante. Il primo dice cosa l’embedding rappresenta (significato come geometria). Il secondo dice cosa l’embedding è (un layer lineare con input one-hot). Confondere il primo per il secondo porta a sopravvalutare lo spazio; confondere il secondo per il primo porta a sottovalutare cosa sia successo durante il training.
La meccanica
Sezione intitolata “La meccanica”Lookup table ed equivalenza con one-hot
Sezione intitolata “Lookup table ed equivalenza con one-hot”Sia V la cardinalità del vocabolario e d la dimensione di embedding. La matrice di embedding è E ∈ R^{V×d}: V righe, ognuna un vettore di R^d. Per il token con id i, l’embedding è la riga i-esima:
Equivalentemente, se rappresentiamo il token come vettore one-hot (zero ovunque tranne posizione i), allora:
Le due forme producono lo stesso vettore — è un’equivalenza, argomentabile direttamente: il prodotto matrice-vettore con un one-hot seleziona una riga. La lookup è solo l’implementazione efficiente: invece di moltiplicare per V−1 zeri inutili, si fa accesso diretto in O(d). L’equivalenza è didatticamente importante perché chiarisce due cose. Primo: l’embedding è un layer lineare degenere, non un oggetto algebricamente esotico. Secondo: il gradiente della loss rispetto a E[i] è non-nullo solo per i token effettivamente presenti nel batch — backward sparso, motivo per cui PyTorch espone nn.Embedding con sparse=True opzionale.
Gradient flow
Sezione intitolata “Gradient flow”Durante il forward, il batch passa per nn.Embedding(V, d) con id selezionati. Durante il backward, il gradiente che torna dal layer successivo è un tensore di forma (batch, d), e viene “scatterato” sulle righe corrispondenti di E. Solo quelle righe ricevono aggiornamento. Conseguenza: parole rare ricevono pochi update, e il loro embedding può restare vicino all’inizializzazione casuale per un lungo tratto del training. È una delle ragioni per cui i vocabolari si tagliano (V tipico 30k-100k per LLM, con tokenizer sub-word).
Un altro effetto della sparsità del backward: ottimizzatori come Adam mantengono statistiche per parametro (media e varianza dei gradienti). Per la matrice di embedding queste statistiche sono per riga, e righe quasi mai toccate accumulano statistiche obsolete che possono produrre passi storti quando finalmente la riga riceve un gradiente. Per questo esistono varianti come SparseAdam in PyTorch e schedulazioni dedicate per parametri sparsi. Dettaglio operativo, non centrale per la teoria, ma è il tipo di cosa che spiega perché un training di language model “esplode” sui token rari dopo molti step apparentemente quieti.
Dimensione d
Sezione intitolata “Dimensione d”La scelta di d è un trade-off espressività vs costo. Word2vec originali usavano 100-300 dim. Sentence-BERT e BGE-base 768. Llama-2-70B ha hidden size 8192, quindi i suoi embedding di input sono in R^8192. La qualità sale tipicamente come logaritmo di d con plateau: raddoppiare d non raddoppia la qualità. OpenAI text-embedding-3-large esce a 3072 dim ma supporta troncamento a 256/512/1024 grazie a Matryoshka representation learning (Kusupati et al., NeurIPS 2022): le dimensioni sono ordinate per importanza e tagliarne una parte degrada gracefully invece di rompere tutto.
Una regola empirica: per retrieval su corpora di milioni di documenti, 384-1024 è il range moderno. Sotto 256 si perde discriminazione; sopra 2048 i costi di storage e di ANN crescono senza guadagno netto.
Inizializzazione, varianza, scaling
Sezione intitolata “Inizializzazione, varianza, scaling”Una sottigliezza facile da perdere. La matrice di embedding entra come somma nel residual stream insieme al positional encoding. Se l’inizializzazione produce vettori con norma molto diversa da quella attesa nei layer successivi, il training parte male. Convenzione frequente: inizializzare E con varianza 1/d, in modo che la norma attesa di ogni riga sia O(1). Alcuni modelli scalano l’embedding per √d in input (Vaswani 2017 lo fa esplicitamente nel paper original) per bilanciare con la dinamica delle attenzioni. Sono dettagli architetturali ma fanno la differenza fra training stabile e training che diverge.
Static vs contextual
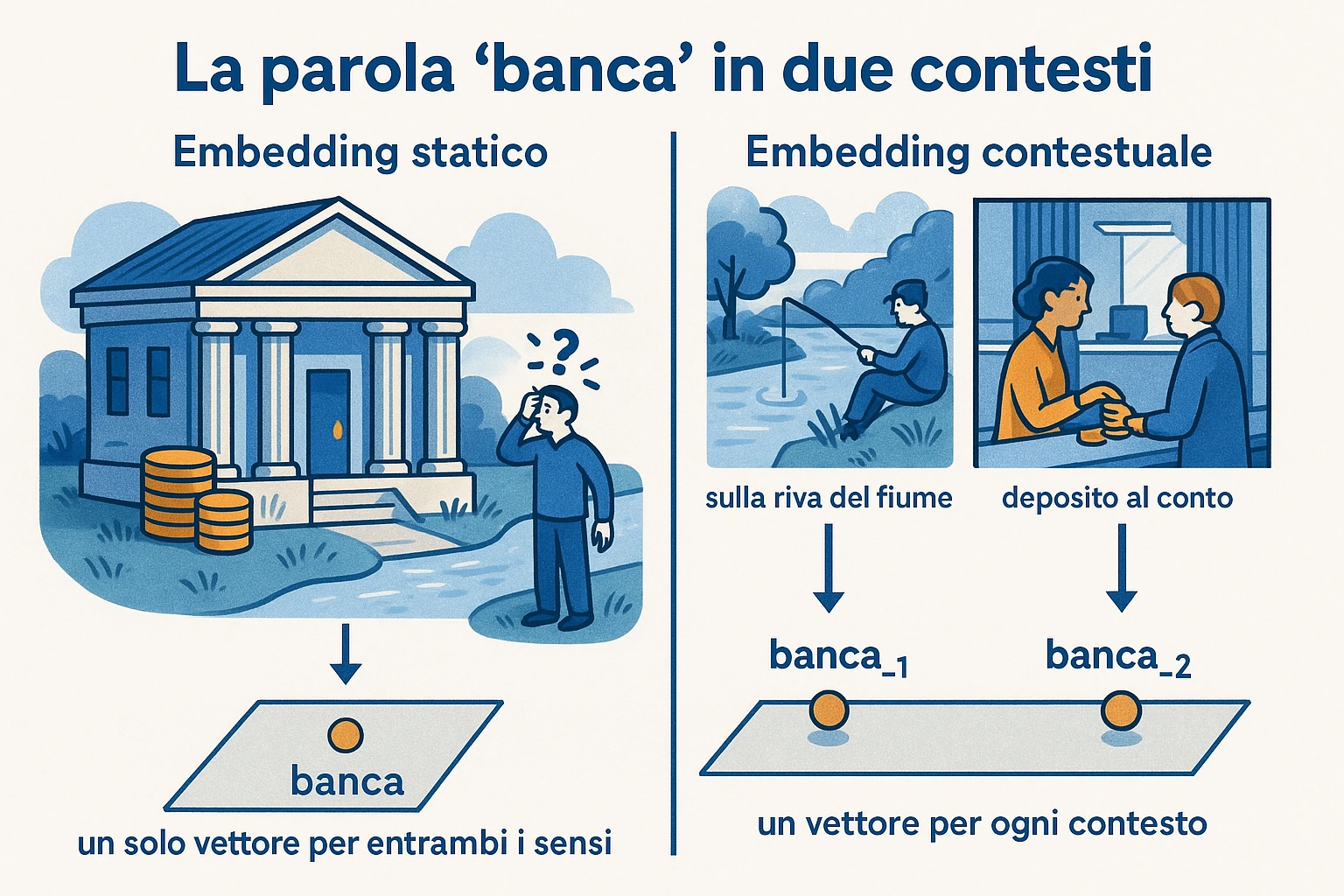
Sezione intitolata “Static vs contextual”Static: E è fissa dopo il training. Stesso token → sempre stesso vettore. Word2vec, GloVe, fastText. Limite intrinseco: polisemia. Il token “bank” in “bank of the river” e in “Swiss bank” condivide un solo vettore, costretto a essere una media compromessa.
Contextual: l’embedding è una funzione (token, contesto) → vettore. Stesso token in frasi diverse dà vettori diversi. ELMo (Peters 2018) lo introduce con biLSTM, BERT lo ridefinisce dentro il transformer. Tecnicamente non esiste una “matrice di embedding contextual”: ogni layer del transformer trasforma il vettore corrente, e l‘“embedding contestuale del token i alla layer L” è il valore del residual stream in posizione i a quel layer. Il layer 0 è static (la matrice di embedding di input); l’informazione semantica si concentra ai layer intermedi (Tenney et al. 2019 mostrano una “rediscovery della pipeline NLP classica” attraverso i layer di BERT).
La differenza non è cosmetica. Un sistema che usa static embedding per disambiguare “bank” è strutturalmente incapace di farlo. Un sistema che usa contextual paga il costo di un transformer forward per ogni frase, ma può.
Embedding di input e di output
Sezione intitolata “Embedding di input e di output”In un LLM decoder-only ci sono due matrici di embedding:
- Input E_in ∈ R^{V×d}: token id → vettore (residual stream layer 0).
- Output / unembedding E_out ∈ R^{d×V}: dal vettore finale del residual stream produce logits su V token, da cui softmax per la distribuzione sul prossimo token.
Press e Wolf (Tel Aviv University, EACL 2017) mostrano che weight tying, cioè E_in = E_out^T (una sola matrice condivisa con la seconda usata in trasposta), migliora i language model e dimezza i parametri di embedding. Llama-1, Mistral lo usano. GPT-3 e modelli più grandi spesso non lo legano (untied) perché la matrice di embedding è una frazione minore del totale parametri e l’untying dà flessibilità in più.
Positional encoding (overview)
Sezione intitolata “Positional encoding (overview)”Il transformer (Vaswani et al., NeurIPS 2017, Attention is All You Need) è invariante alla permutazione delle posizioni dei token: occorre iniettare l’informazione di posizione. Tre famiglie principali:
- Sinusoidale (Vaswani 2017):
PE(p, 2i) = sin(p / 10000^{2i/d}), e cos per dimensioni dispari. Sommata all’embedding di token. Generalizza a posizioni mai viste. - Learned absolute: una matrice PE ∈ R^{L_max × d} indicizzata per posizione, addestrata. BERT, GPT-2.
- Rotary (RoPE): Jianlin Su et al. (2021) ruotano Q e K nello spazio complesso 2D in funzione della posizione; il prodotto Q·K dipende solo dalla differenza di posizione, dando un encoding effettivamente relativo. Llama, Mistral, Qwen, DeepSeek lo usano. È il default del 2023-2026.
L’intuizione di RoPE in due frasi: ogni vettore Q (e K) si vede come sequenza di coppie di numeri, ciascuna un punto nel piano. La posizione p ruota ogni coppia di un angolo proporzionale a p, con frequenze diverse per coppie diverse. Quando si calcola Q·K il prodotto scalare diventa funzione della differenza di posizione, non delle posizioni assolute, e da qui derivano le proprietà di generalizzazione di RoPE e l’estensione di contesto via interpolazione di frequenze (NTK-aware, YaRN) senza riaddestrare da zero.
Punto di registro: il positional encoding è geometria pura, non semantica. Confonderlo con un “embedding di posizione” alla pari di un embedding di token è scivoloso: il primo dice dove, il secondo dice cosa. Sommarli funziona perché la rete impara a usarli separatamente nei layer successivi, non perché siano lo stesso oggetto.
Il positional encoding non è “un altro embedding di parola”: è una struttura geometrica che dice al modello dove sta, non cosa è.
Inizializzazione e training
Sezione intitolata “Inizializzazione e training”La matrice E parte tipicamente da inizializzazione gaussiana a media zero e varianza piccola (per esempio σ = 1/√d, oppure scelte tipo Xavier/Glorot). Token frequenti ricevono molti aggiornamenti e si stabilizzano in fretta; token rari restano vicini all’inizializzazione e producono embedding rumorosi. Per questo i tokenizer sub-word (Byte-Pair Encoding, SentencePiece, Unigram) cercano un compromesso fra granularità lessicale e frequenza media: spezzare “transformerizzare” in transform + er + izz + are rende ogni pezzo abbastanza frequente da essere addestrato bene, e ricomporre il significato è compito dei layer successivi del transformer.
Una conseguenza concreta: per embedding di concetti molto rari (nomi propri di nicchia, codici di protocollo specifici), nessun encoder generale farà bene out-of-the-box. La strada è fine-tuning su dati di dominio o fallback a retrieval lessicale.
Pooling per frasi
Sezione intitolata “Pooling per frasi”Un transformer produce un vettore per token. Per ottenere un vettore per frase servono strategie di pooling:
- Mean pooling: media dei vettori di token, eventualmente pesata per attention mask.
- CLS token: in BERT, il primo token speciale
[CLS]è addestrato per riassumere la frase nelle classification head. - Last-token pooling: nei decoder-only, l’ultimo token vede tutto il contesto a sinistra ed è una scelta naturale (E5-Mistral, GTE-Qwen).
Reimers e Gurevych (Sentence-BERT, 2019) mostrano che mean pooling sul BERT vanilla è scadente per similarità di frasi e propongono un fine-tuning siamese su NLI/STS che produce encoder finalmente confrontabili via cosine. Senza quel passaggio la geometria è troppo dominata dal compito di masked language modeling.
Contrastive training (in due righe)
Sezione intitolata “Contrastive training (in due righe)”Gli encoder moderni (E5 di Microsoft, BGE di BAAI, GTE di Alibaba, text-embedding-3 di OpenAI, embed-v3 di Cohere) sono addestrati con contrastive learning e loss InfoNCE (van den Oord, 2018):
dove q è la query, p+ è il documento rilevante (positive), p scorre su un insieme di candidati (positive + negativi in-batch o hard-mined), è una temperatura. La loss tira q e p+ vicino e separa q dai negativi. Iterato su miliardi di coppie, modella uno spazio in cui la cosine similarity coincide con la rilevanza per retrieval.
Tre dettagli che fanno la differenza, e che si imparano leggendo le model card degli encoder moderni. Primo: batch size grande (8.000-32.000) è cruciale, perché in-batch negatives forniscono il segnale principale e con batch piccoli il problema è troppo facile. Secondo: hard negatives mining — passaggi che assomigliano superficialmente al positive ma non sono rilevanti — accelera il training e riduce gli errori sistematici. Terzo: la temperatura τ controlla quanto la loss è “sharp”: τ piccola spinge a separazioni nette ma rende il training instabile, τ grande è morbida ma può lasciare cluster sovrapposti. Valori tipici 0.01-0.05.
Asymmetric vs symmetric encoding
Sezione intitolata “Asymmetric vs symmetric encoding”Un dettaglio che divide gli encoder moderni: alcuni trattano query e documento simmetricamente (stessa funzione applicata a entrambi); altri usano prefissi distinti (“query: …” e “passage: …”) che condizionano il modello a produrre rappresentazioni diverse per i due ruoli. La motivazione è empirica: query reali sono brevi e formulate in modo telegrafico, documenti sono lunghi e prosaici, e mappare entrambi nello stesso modo distorce lo spazio. Encoder come E5 e BGE adottano la versione asymmetric. Conseguenza per chi li usa: leggere la documentazione e applicare i prefissi nel modo prescritto, sennò si perdono punti percentuali di Recall@k senza accorgersene.
Embedding di oggetti non-testuali
Sezione intitolata “Embedding di oggetti non-testuali”Tutto il discorso fatto per i token vale, mutatis mutandis, per qualunque insieme discreto di oggetti. In un sistema di raccomandazione si addestra una matrice di item embedding (un vettore per ogni prodotto del catalogo) e una matrice di user embedding (un vettore per ogni utente). La rilevanza prodotto-utente diventa un dot product. Il training avviene su segnali impliciti (click, acquisti, watch time) o espliciti (rating). Lo schema “due torri” — una per query/utente, una per documento/item — è la generalizzazione architetturale di Sentence-BERT al di fuori del testo. Si trova identico nei sistemi di retrieval di YouTube (Covington et al. 2016), TikTok, Netflix, e nei recommender e-commerce.
Lo stesso pattern si applica ai grafi (node embedding via DeepWalk, node2vec, GraphSAGE), alle molecole (chemical embedding), alle sequenze biologiche (ESM-2 per proteine). L’embedding non è un’idea NLP-centrica: è la modalità default con cui le reti neurali “vedono” oggetti discreti.
Cosa fa un encoder oltre la matrice
Sezione intitolata “Cosa fa un encoder oltre la matrice”Per gli encoder di frase moderni la “matrice E” è solo il primo strato. Ciò che distingue BGE da una semplice somma di word embedding è il transformer interposto fra input e output, e il regime di training contrastivo. Il vettore di frase prodotto è funzione non-lineare del testo intero, e non si può ottenere come media di vettori static. Quando si dice “embedding di una frase” in questo regime si intende: il vettore prodotto dall’encoder addestrato, non una composizione triviale di parti.
Pseudocodice minimo
Sezione intitolata “Pseudocodice minimo”import torchimport torch.nn as nn
V, d = 50000, 768emb = nn.Embedding(V, d) # crea E ∈ R^{V×d}ids = torch.tensor([42, 17, 9]) # batch di token idvecs = emb(ids) # (3, 768): righe E[42], E[17], E[9]
# equivalente concettuale via one-hot:onehot = torch.zeros(3, V)onehot[range(3), ids] = 1.0vecs2 = onehot @ emb.weight # stesso risultato, costo O(V·d)La prima forma è quella usata in produzione. La seconda è quella che si tiene in testa per capire cosa sta succedendo.
Esempio 1 — numerico, embedding 4×3 e cosine similarity
Sezione intitolata “Esempio 1 — numerico, embedding 4×3 e cosine similarity”Supponiamo un mini-vocabolario di 4 token (gatto, cane, auto, bici) e d=3. Dopo training fittizio, la matrice E è:
E = [ [ 0.9, 0.4, 0.1], # gatto [ 0.8, 0.5, 0.1], # cane [ 0.1, 0.0, 0.9], # auto [ 0.1, 0.1, 0.8], # bici]Calcoliamo la cosine similarity fra “gatto” e “cane” (norma di gatto ≈ 0.99, di cane ≈ 0.95):
Fra “gatto” e “auto”:
Fra “auto” e “bici”:
L’embedding ha imparato due cluster: animali (gatto, cane) e veicoli (auto, bici). Dentro un cluster cosine ≈ 1; fra cluster cosine ≈ 0.2. È esattamente il tipo di geometria che un encoder di frasi addestrato su retrieval produce, ma in 768 dimensioni invece di 3 e con sfumature molto più fini.
Vale la pena soffermarsi sul senso di queste tre dimensioni. Non sono “asse animalità”, “asse mobilità”, “asse colore”: sono direzioni emerse dal training, e nessuna di esse, presa singolarmente, è leggibile. Solo le distanze sono interpretabili. Questo è un cambio di mentalità rispetto al feature engineering classico, dove ogni colonna ha un nome. Negli embedding moderni il significato è spalmato su tutte le dimensioni; tagliarne alcune (Matryoshka) o ruotarle (whitening) produce uno spazio diverso ma equivalente per molte misure.
Esempio 2 — codice, ranking di frasi rispetto a una query
Sezione intitolata “Esempio 2 — codice, ranking di frasi rispetto a una query”Con sentence-transformers (libreria Python di Reimers, basata su PyTorch) e BGE-base:
from sentence_transformers import SentenceTransformerimport numpy as np
model = SentenceTransformer("BAAI/bge-base-en-v1.5")
corpus = [ "The cat sat on the mat.", "Rome is the capital of Italy.", "Felines often nap on rugs.", "Photosynthesis converts light into chemical energy.", "Bicycles are a sustainable transport option.",]query = "Where do cats like to rest?"
E_corpus = model.encode(corpus, normalize_embeddings=True) # (5, 768)e_q = model.encode(query, normalize_embeddings=True) # (768,)
scores = E_corpus @ e_q # cosine, perché normalizzatiranking = np.argsort(-scores)for idx in ranking: print(f"{scores[idx]:.3f} {corpus[idx]}")Output tipico (valori indicativi):
0.81 Felines often nap on rugs.0.78 The cat sat on the mat.0.40 Bicycles are a sustainable transport option.0.32 Rome is the capital of Italy.0.28 Photosynthesis converts light into chemical energy.Il modello recupera correttamente le frasi sui gatti che riposano, anche se “felines” e “nap” non sono in query. Questo è il valore aggiunto rispetto a un BM25 puro: somiglianza semantica, non lessicale. Notare anche due punti fragili. Primo: i punteggi assoluti dipendono dal modello — un altro encoder darebbe scale diverse, e confrontarli direttamente è errato. Secondo: se la query fosse stata in italiano e il modello fosse monolingual inglese, i punteggi sarebbero stati comprimibili in una banda stretta e difficile da interpretare.
Esempio 3 — scenario reale, pipeline RAG end-to-end
Sezione intitolata “Esempio 3 — scenario reale, pipeline RAG end-to-end”Una product knowledge base aziendale contiene 10.000 documenti tecnici. Vogliamo costruire un assistente che risponda a domande tecniche citando fonti interne. Pipeline:
- Ingestion: ogni documento viene parsato (PDF, HTML, Markdown), pulito, e diviso in chunk di 400 token con 50 token di overlap. Risultato: ~80.000 chunk.
- Embedding offline: ogni chunk passa per un encoder (es.
BAAI/bge-large-en-v1.5, d=1024). Output: matrice 80.000×1024. - Indicizzazione: la matrice viene caricata in un vector DB (FAISS, pgvector, Qdrant). L’indice ANN (HNSW) permette top-k in tempo logaritmico al posto di lineare.
- Query time: l’utente chiede “Come configuro l’autenticazione SSO con SAML?”. La query passa per lo stesso encoder (criticamente: lo stesso, altrimenti gli spazi non sono confrontabili) con il prefisso “query:” se il modello è asymmetric. Si recuperano top-k=5 chunk per cosine similarity.
- Prompt assembly: i 5 chunk vengono concatenati in un prompt strutturato:
Contesto:[chunk 1][chunk 2]...Domanda: Come configuro l'autenticazione SSO con SAML?Rispondi citando le fonti.
- Generation: l’LLM produce una risposta, idealmente citando i chunk recuperati.
Sei punti possono rompersi indipendentemente: parsing dei documenti, scelta del chunk size, scelta dell’encoder, mismatch encoder ingestion vs query, scelta di k, contesto saturo nell’LLM. Cinque dei sei vivono nello spazio di embedding o intorno. Per questo “fa RAG” non è un’attività triviale: è un esercizio di geometria applicata.
Numericamente un esempio realistico: 80.000 chunk × 1024 dim × 4 byte (float32) = 327 MB di indice prima di qualunque overhead di HNSW. Su corpora di milioni di chunk si sale a decine di GB e diventa rilevante anche la quantizzazione degli embedding: scalar quantization a int8 (un quarto della memoria, perdita di qualità sotto il punto percentuale per molti modelli), product quantization (Jégou et al., 2011) per compressioni più aggressive. La quantizzazione introduce un altro punto di rottura: se l’indice è quantizzato e la query no, i punteggi non sono direttamente confrontabili e i top-k possono essere subottimi.
Applicazioni pratiche
Sezione intitolata “Applicazioni pratiche”- Input layer di ogni LLM. Il primo passo di ogni transformer è una
nn.Embedding. Le distinzioni che il modello potrà mai fare partono da qui. - Output layer di ogni LLM. La unembedding matrix proietta il residual stream finale su logits. Il legame fra le due matrici (tied vs untied) è una scelta architetturale.
- Positional encoding. RoPE, ALiBi, sinusoidale: forme diverse di “embedding di posizione” che vivono nello stesso spazio degli embedding di token.
- Retrieval per RAG. Nucleo di ogni sistema di Q&A su corpora privati, motori di ricerca semantica, code search.
- Classificazione e clustering. Encoder come feature extractor: passare un testo nell’encoder, classificare con un linear head, clusterizzare con k-means. Permette training con poche label.
- Recommendation systems. Item embedding e user embedding addestrati su click/acquisti; raccomandazione = top-k nello spazio.
- Code embedding. Modelli come CodeBERT, StarCoder embeddings, jina-embeddings-v2-code: indicizzano codice per code search e per agenti che cercano funzioni rilevanti dentro un repo.
- Multimodale. CLIP (Alec Radford et al., OpenAI, ICML 2021) addestra due encoder (text, image) con loss contrastiva su 400 milioni di coppie immagine-didascalia, producendo uno spazio condiviso. Permette ricerca testo→immagine zero-shot e fa da text encoder per Stable Diffusion e DALL-E 2.
- Probing e interpretabilità. Probing classifiers (Tenney et al. 2019) e structural probes (Hewitt-Manning 2019) usano embedding contestuali per scoprire quali proprietà linguistiche un modello ha catturato.
Dove si rompe
Sezione intitolata “Dove si rompe”Si potrebbero raggruppare i fallimenti in tre famiglie. Geometriche: anisotropia, dimensione mal scelta, normalizzazione dimenticata. Semantiche: polisemia in static, OOD, multilingualità incompleta, identificatori. Operative: encoder mismatch, asymmetric retrieval gestito male, embedding stale. Le prime si vedono guardando la distribuzione dei punteggi; le seconde guardando query reali e i loro top-k; le terze guardando il codice che orchestra il sistema. Tre lenti diverse, tre tipi di evidenza.
Anisotropia e cosine inflazionata
Sezione intitolata “Anisotropia e cosine inflazionata”Kawin Ethayarajh (Stanford, EMNLP 2019) documenta che gli embedding contestuali di GPT-2, BERT e ELMo non sono distribuiti uniformemente sulla sfera unitaria: vivono in coni stretti. Conseguenza: il cosine medio fra due vettori “casuali” può essere superiore a 0.5 invece che vicino a zero. Se si valuta similarità prendendo per buono un cosine di 0.8, in un modello anisotropo quel valore può essere rumore. Mitigazioni: whitening (sottrarre la media e scalare per la radice della covarianza), BERT-flow (Li et al., EMNLP 2020), isotropy regularization durante training. Modelli sentence-encoder addestrati con contrastive learning sono molto meno anisotropi degli encoder vanilla.
Analogie king-queen come legge generale
Sezione intitolata “Analogie king-queen come legge generale”L’analogia di Mikolov 2013 ha avuto risonanza enorme. Tal Linzen (Johns Hopkins, 2016) e Malvina Nissim et al. (Groningen, 2020) mostrano che funziona in modo affidabile solo escludendo dalla ricerca i termini sorgente: senza esclusione, il top-1 nearest neighbor è spesso uno dei tre input. In più, le analogie morfologiche e fattuali falliscono sistematicamente. Marcatura corretta: ANALOGIA che funziona sotto ipotesi, non legge dello spazio. Costruirci sopra ragionamenti architetturali è errore di registro.
Bias di lunghezza e di stile
Sezione intitolata “Bias di lunghezza e di stile”Un effetto meno discusso ma frequente in produzione: gli encoder addestrati su passaggi prevalentemente di una certa lunghezza tendono a dare punteggi più alti a passaggi di lunghezza simile, indipendentemente dalla rilevanza. Allo stesso modo, lo stile (formale, conversazionale, codice, didascalia) influenza la geometria. Una query in stile telegrafico può recuperare male contro documenti in stile prosaico, anche se semanticamente identici. La mitigazione passa da training data più variegati e da rifrasare la query in più modi (query expansion, multi-query retrieval) per ridurre la dipendenza dallo stile della formulazione.
Bias come riflesso dei dati
Sezione intitolata “Bias come riflesso dei dati”Tolga Bolukbasi et al. (Boston University / Microsoft Research, NeurIPS 2016) nel paper Man is to Computer Programmer as Woman is to Homemaker? mostrano che gli embedding word2vec addestrati su Google News codificano bias di genere: la direzione v(he) − v(she) proietta su parole come “doctor”/“nurse”, “computer programmer”/“homemaker” in modo allineato al bias del corpus. È un caso di FILIAZIONE empirica: bias nei dati → bias nelle distanze, dimostrato statisticamente. Tentativi di “debias” via proiezione ortogonale alla direzione di bias funzionano in superficie, ma Hila Gonen e Yoav Goldberg (Bar-Ilan, NAACL 2019) mostrano che il bias persiste nei nearest neighbors locali anche dopo proiezione: spostato, non rimosso. Lezione operativa: scegliere encoder addestrati su corpora di cui si conosce composizione e licenza, e fare audit downstream.
Static embedding e polisemia
Sezione intitolata “Static embedding e polisemia”“bank” (istituto finanziario) e “bank” (riva del fiume) condividono un solo vettore in word2vec. Per task che dipendono dalla disambiguazione (NER, QA puntuale) gli static embedding sono strutturalmente insufficienti. Da qui il salto a contextual: il problema non si risolve, si sposta dentro il transformer.
Out-of-distribution drift
Sezione intitolata “Out-of-distribution drift”Un encoder addestrato su Wikipedia generale può comportarsi male su domini specialistici (medico, legale, codice scientifico). Vocabolario tecnico diventa “rumore”, cosine collassa a valori vicini. Soluzioni: encoder dominio-specifici (BioBERT, LegalBERT, CodeBERT), continual training, oppure adapter LoRA sull’encoder. Quando una pipeline RAG sembra “non recuperare niente di rilevante”, la prima ipotesi da scartare è OOD.
Chunk size sbagliato per RAG
Sezione intitolata “Chunk size sbagliato per RAG”Chunk troppo grandi (>1000 token) diluiscono il segnale: l’embedding è un riassunto pesato di troppe cose, e la cosine similarity con una query specifica si appiattisce. Chunk troppo piccoli (<100 token) perdono contesto: una frase isolata non basta a stabilire rilevanza. La scelta dipende dal corpus (tecnico, narrativo, codice) e va tarata empiricamente con un eval set di query reali. Non c’è valore universale.
Encoder mismatch
Sezione intitolata “Encoder mismatch”Indicizzare con un encoder e fare query con un altro produce spazi non confrontabili. Errore frequente in pipeline costruite a tappe da team diversi. Defensive engineering: registrare il fingerprint dell’encoder (nome, versione, hash dei pesi) accanto agli embedding indicizzati, e rifiutare query da encoder diversi.
Dimensione mal scelta
Sezione intitolata “Dimensione mal scelta”d troppo bassa: si perde discriminazione, cluster collassano. d troppo alta: rumore (curse of dimensionality, vedi curse-dimensionalita in preparazione), storage costoso, ANN più lento. Per retrieval generale 384-1024 è il range moderno; 256 è il limite inferiore per Matryoshka troncato; oltre 2048 si paga senza vedere.
Asymmetric retrieval
Sezione intitolata “Asymmetric retrieval”Encoder moderni distinguono “query embedding” da “passage embedding” tramite prefissi o due encoder diversi. Trattarli simmetricamente (stessa funzione applicata a query e doc) può degradare drasticamente i risultati. Leggere la model card di ogni encoder è un passaggio obbligato, non un dettaglio.
Normalizzazione
Sezione intitolata “Normalizzazione”Cosine similarity richiede vettori normalizzati per essere paragonabile a un dot product diretto. Dimenticare di normalizzare significa che la lunghezza del vettore (che può correlare con frequenza nel training set) inquina il ranking. Convenzione difensiva: normalizzare sempre output dell’encoder e usare dot product invece di cosine.
Embedding stale
Sezione intitolata “Embedding stale”Un encoder rilasciato nel 2022 non sa nulla di concetti emersi dopo. Per knowledge base che evolve, l’embedding model va aggiornato periodicamente, e questo significa re-indicizzare l’intero corpus: i vecchi embedding non sono compatibili con il nuovo modello. Costo non trascurabile per corpora grandi. Pattern difensivo: tenere il testo originale dei chunk in storage primario e l’indice vettoriale come materializzazione derivata, così che re-embeddare sia un job batch e non una migrazione manuale.
Multilingualità incompleta
Sezione intitolata “Multilingualità incompleta”Encoder etichettati come “multilingual” coprono spesso un sottoinsieme di lingue con qualità molto disuguale. Un modello addestrato prevalentemente su inglese e poche lingue romanze può degradare drasticamente su lingue a basso volume di training (swahili, basco, lingue indo-aria). Per applicazioni multilingue è obbligatorio testare su query reali in ogni lingua di interesse e, se serve, segmentare l’indice per lingua o usare encoder specializzati. Il cosine fra una query in inglese e un documento in italiano, in un encoder davvero multilingue, dovrebbe essere alto se le frasi sono traduzioni l’una dell’altra: è il primo test che si fa.
Numeri, codici, identificatori
Sezione intitolata “Numeri, codici, identificatori”Token che codificano numeri, codici prodotto, identificatori (SKU, DOI, IBAN) finiscono in posizioni dello spazio di embedding che riflettono il pattern lessicale, non il significato numerico o referenziale. Cercare “ordine 12345” in un corpus pieno di numeri d’ordine darà risultati basati su prossimità di token simili, non sull’identificatore esatto. Per questi casi il retrieval semantico va affiancato a indici lessicali o a campi strutturati: un sistema di retrieval che ignora questa distinzione fallisce silenziosamente sulla query “qual è lo stato dell’ordine 12345?”.
Falsa fiducia nei punteggi assoluti
Sezione intitolata “Falsa fiducia nei punteggi assoluti”Un cosine di 0.78 in un modello A e un cosine di 0.78 in un modello B non significano la stessa cosa: la distribuzione dei punteggi dipende dall’encoder. Threshold assoluti (“se cosine > 0.7 considera rilevante”) sono robusti solo per un singolo modello, e vanno ricalibrati a ogni cambio di encoder. Per soglie portabili è preferibile lavorare con percentili (top-k) o con score normalizzati rispetto a una baseline.
Valutare un encoder, non sceglierlo per fama
Sezione intitolata “Valutare un encoder, non sceglierlo per fama”Encoder diversi performano diversamente su domini diversi. Un modello primo nelle classifiche generali (MTEB di Hugging Face, Massive Text Embedding Benchmark, Muennighoff et al. 2022) può essere mediocre su un corpus di documentazione tecnica interna o su query molto corte. La scelta razionale richiede un eval set proprio: 50-200 query etichettate con i documenti rilevanti, e una metrica come Recall@k o nDCG@k calcolata su candidati estratti dal proprio indice. Senza questo passaggio si sceglie l’encoder più di moda, non il più adatto, e ci si accorge dell’errore solo quando gli utenti si lamentano.
Latenza di encoding
Sezione intitolata “Latenza di encoding”L’embedding di una query non è gratis. Con un encoder large e batch=1, il forward può richiedere decine di millisecondi su CPU e qualche millisecondo su GPU. Per applicazioni interattive (autocomplete semantico, search-as-you-type) la latenza dell’encoder somma alla latenza dell’ANN e a quella dell’eventuale LLM downstream. Encoder small (MiniLM, BGE-small) sono spesso un compromesso ragionevole: poca qualità persa, latenza dimezzata. Decidere per misura, non per intuito.
Privacy e leakage
Sezione intitolata “Privacy e leakage”Gli embedding non sono “anonimi”. Il paper Information Leakage in Embedding Models (Song & Raghunathan, CCS 2020) e successivi mostrano che da un embedding è possibile ricostruire informazioni significative sul testo originale, in alcuni casi fino al testo stesso (embedding inversion). In contesti regolati (sanitario, finanziario) trattare gli embedding come dato pubblico è errore: vanno protetti come il testo da cui derivano.
Versionamento e riproducibilità
Sezione intitolata “Versionamento e riproducibilità”Un aggiornamento dell’encoder, anche minore, cambia le coordinate. Sistemi che persistono embedding senza memorizzare versione del modello, hash dei pesi e parametri di tokenization rischiano risultati irriproducibili dopo qualunque upgrade. Lo schema difensivo è semplice: ogni embedding salvato porta con sé un fingerprint dell’encoder che lo ha prodotto, e l’indice rifiuta query da fingerprint diversi. Costa qualche colonna in più nel database; risparmia ore di debugging quando i risultati cambiano senza spiegazione.
Quando un’embedding non basta
Sezione intitolata “Quando un’embedding non basta”C’è una classe di problemi per cui un singolo vettore per documento è insufficiente. Documenti lunghi e tematicamente eterogenei vengono compressi in un vettore “media” che non rappresenta nessuna delle loro parti. La risposta architetturale è la late interaction, di cui ColBERT (Khattab & Zaharia, SIGIR 2020) è l’esempio canonico: invece di un vettore per documento si tengono i vettori di tutti i token, e la similarità query-documento è una somma di max-similarità token-livello. Costo: storage moltiplicato per numero medio di token per documento. Beneficio: granularità che un singolo vettore non può raggiungere. La stessa famiglia di idee si ritrova nei reranker cross-encoder, che invece di confrontare due vettori passano la coppia (query, documento) in un transformer che attende su tutto e produce uno score; più costoso ma più accurato. Il pattern di produzione moderno è: bi-encoder per top-k, cross-encoder per ri-rankare i top-k, late interaction quando si può permettere lo storage.
Direzioni interpretabili e usi avanzati
Sezione intitolata “Direzioni interpretabili e usi avanzati”Una linea di ricerca recente, oltre il dove-si-rompe, riguarda l’interpretabilità degli embedding e il loro uso come leve di controllo sul modello. Non è ancora pratica consolidata, ma vale la pena conoscerla perché orienta il modo in cui si pensa allo spazio.
Linear representation hypothesis (Kiho Park, Yo Joong Choe, Victor Veitch, 2023): certe variabili semantiche binarie (vero/falso, presente/passato, soggetto/oggetto) sono codificate come direzioni lineari nello spazio degli embedding. Se è vero, basta una proiezione su una direzione per leggere o modificare quella proprietà.
Steering vectors: la tecnica ActAdd di Alex Turner et al. (2023) calcola la differenza media di attivazioni interne di un LLM fra prompt “happy” e prompt “sad”, ottiene un vettore, e lo somma al residual stream durante il forward. Il modello produce output più o meno “happy” senza cambiare prompt. Suggerisce che lo spazio nasconde direzioni interpretabili a posteriori, e apre la strada a un controllo di basso livello complementare al prompting.
Probing classifiers: addestrare un classificatore lineare su embedding congelati per predire una proprietà (parte del discorso, dipendenze sintattiche, sentiment, factuality). Se il classificatore funziona, l’informazione è codificata linearmente nel layer scelto. Tenney, Das, Pavlick (Google, 2019) e John Hewitt, Christopher Manning (Stanford, NAACL 2019, structural probe) ne sono pilastri metodologici. Da qui il sotto-campo della BERTology e, più recentemente, della mech interp (mechanistic interpretability) che ricostruisce i circuiti dei transformer.
L’utilità pratica per chi costruisce sistemi è ancora limitata, ma l’idea di base — lo spazio di embedding non è un blob, contiene direzioni leggibili — è già operativa nel debug: quando un retrieval funziona male, una visualizzazione PCA o UMAP dei chunk colorati per categoria può rivelare se il modello sta separando ciò che ci si aspetta che separi.
Una nota di metodo. Visualizzazioni 2D di spazi 768-dimensionali sono utili per ipotesi, non per conclusioni: PCA e UMAP introducono distorsioni non triviali, e cluster apparenti possono essere artefatti della proiezione. Per validare una geometria si torna sempre alle distanze nello spazio originale, magari con metriche tipo silhouette su cluster noti, intrinsic dimensionality, o nearest-neighbor accuracy su query etichettate. Lo spazio di embedding è un oggetto da misurare, non da disegnare.
Collegamenti
Sezione intitolata “Collegamenti”- ponte-distribuzionale-embeddings — il legame storico fra ipotesi distribuzionale di Firth e word2vec, prerequisito concettuale di questo capitolo.
- vettori-spazi — le coordinate, la somma, lo scalamento: lingua di base.
- norme-distanze — L1, L2, cosine: misure che danno significato alla “vicinanza”.
- prodotto-scalare — il prodotto scalare come proiezione e somiglianza, base di cosine.
- softmax-sigmoid — la unembedding produce logits che softmax trasforma in distribuzione su token.
- attention-intuizione (in preparazione) — l’attention opera su Q, K, V costruiti come trasformazioni lineari del residual stream, che parte da embedding.
- rope (in preparazione) — il positional encoding moderno applicato sopra gli embedding di token.
- rag-base (in preparazione) — la pipeline RAG di cui gli embedding sono il motore di retrieval.
- tokenizzazione-intro (in preparazione) — l’embedding presuppone un vocabolario, e la qualità del vocabolario condiziona la qualità della geometria.
- mech-interp-intro (in preparazione) — probing e steering vectors come usi diagnostici degli embedding.
Per andare oltre
Sezione intitolata “Per andare oltre”- Jurafsky, D., Martin, J. — Speech and Language Processing, 3rd ed. draft, capitolo 6 “Vector Semantics and Embeddings”. Trattazione didattica completa, da count-based a contextual. Riferimento standard per studenti.
- Mikolov, T. et al. (2013) — Efficient Estimation of Word Representations in Vector Space. arXiv:1301.3781. Il paper word2vec. Breve, leggibile, fondazionale.
- Devlin, J. et al. (2019) — BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019. La transizione static → contextual nel transformer.
- Reimers, N., Gurevych, I. (2019) — Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019. Come si trasforma un LM in encoder di frase.
- Ethayarajh, K. (2019) — How Contextual are Contextualized Word Representations?. EMNLP 2019. Lettura indispensabile per capire che la geometria osservata non è quella ingenuamente assunta.