Modelli mentali: come ragioniamo davvero
Pensare è simulare. Un ragazzo di Cambridge lo scrive in un libro nel 1943, muore due anni dopo a 31 anni, e quella frase — i pensieri come small-scale models del mondo — diventa il filo che attraversa cognitive science, design, system dynamics e infine, ottant’anni dopo, l’architettura di un agente RL che si addestra dentro un mondo immaginato.
Apertura
Sezione intitolata “Apertura”Cambridge, primavera 1943. Kenneth Craik, ventinove anni, fellow del St John’s College, dà alle stampe un libretto smilzo intitolato The Nature of Explanation (Cambridge University Press). Centoventi pagine, scritte con la disinvoltura di chi lavora in un laboratorio di psicologia sperimentale (lo Psychological Laboratory di Cambridge) ma legge fisiologia, fisica, filosofia. Nel capitolo quinto, “Hypothesis on the Nature of Thought”, Craik propone una tesi che il suo tempo non sa ancora come trattare:
Se l’organismo porta dentro la testa un small-scale model della realtà esterna e delle proprie azioni possibili, è in grado di provare le varie alternative, concludere quale sia la migliore, reagire a situazioni future prima che si presentino, utilizzare la conoscenza di eventi passati per affrontare il presente e il futuro, e in ogni modo reagire in modo molto più pieno, sicuro e competente alle emergenze che lo affrontano.
Pensare è simulare. Non è applicare regole simboliche su proposizioni; è far girare in testa un analogo strutturato del mondo, e leggere il risultato. Craik non vivrà per vedere la sorte della sua frase. Il 7 maggio 1945, il giorno della resa tedesca, viene investito da un’auto a Cambridge mentre torna in bicicletta. Muore a 31 anni. Il libro resta come testamento.
Decenni dopo, lo riprende un’intera scuola. Nel 1948 Edward Chace Tolman pubblica “Cognitive maps in rats and men” e mostra che i ratti scelgono short-cut spazialmente coerenti in labirinti dove non hanno mai percorso quel cammino. Nel 1983 Philip Johnson-Laird pubblica Mental Models e fonda una teoria della deduzione basata su token-models invece che su regole logiche. Nello stesso anno Donald Norman pubblica un saggio breve sui mental models in HCI che diventerà la base del Design of Everyday Things. Nel 1989 John Sterman pubblica i risultati del beer game al MIT Sloan e quantifica per la prima volta quanto i mental models umani siano miopi rispetto a feedback loops e ritardi. Nel 1990 Richard Sutton introduce Dyna: un agente RL che si addestra alternando esperienza reale con rollout dentro un model interno appreso. Nel 2018 David Ha e Jürgen Schmidhuber pubblicano “World Models”, citano esplicitamente Craik, e mostrano un agente che gioca a un videogioco quasi interamente dentro la propria immaginazione. Nel 2022 Yann LeCun propone JEPA come architettura post-LLM esplicitamente fondata sull’idea di world model. È una catena di citazioni rara: dalla cognitive science del 1943 all’AI del 2022, una linea di filiazione documentata che attraversa tre discipline.
Questo capitolo ricostruisce quella catena, e — più importante — distingue con precisione quattro tradizioni diverse che convivono sotto lo stesso ombrello “mental model”: le cognitive maps di Tolman, la model theory of reasoning di Johnson-Laird, i three models di Norman, le mental simulations di Forrester-Sterman-Battaglia. Sono cose distinte. Trattarle come sinonimi è la fonte principale di confusione divulgativa sul tema.
Perché questo capitolo
Sezione intitolata “Perché questo capitolo”Tre ragioni: una concettuale, una clinica-empirica, una di igiene per chi lavora con sistemi AI.
La concettuale. Modelli mentali non è una tassonomia di stati interni. È una scelta di livello sulla natura del pensiero: non manipolazione di simboli secondo regole formali (la posizione classica di logica e AI simbolica anni Cinquanta-Settanta), ma costruzione e manipolazione di analoghi strutturati del mondo. La scelta ha conseguenze. Cambia cosa conta come “ragionare bene”: non più validità sintattica, ma adeguatezza del modello al problema. Cambia cosa conta come errore: non più passo logico mancante, ma modello incompleto o male calibrato. Cambia il rapporto fra cognizione e mondo: il modello porta dentro la testa la struttura del mondo, e quella struttura — non un sistema di regole astratte — è ciò che fa il lavoro.
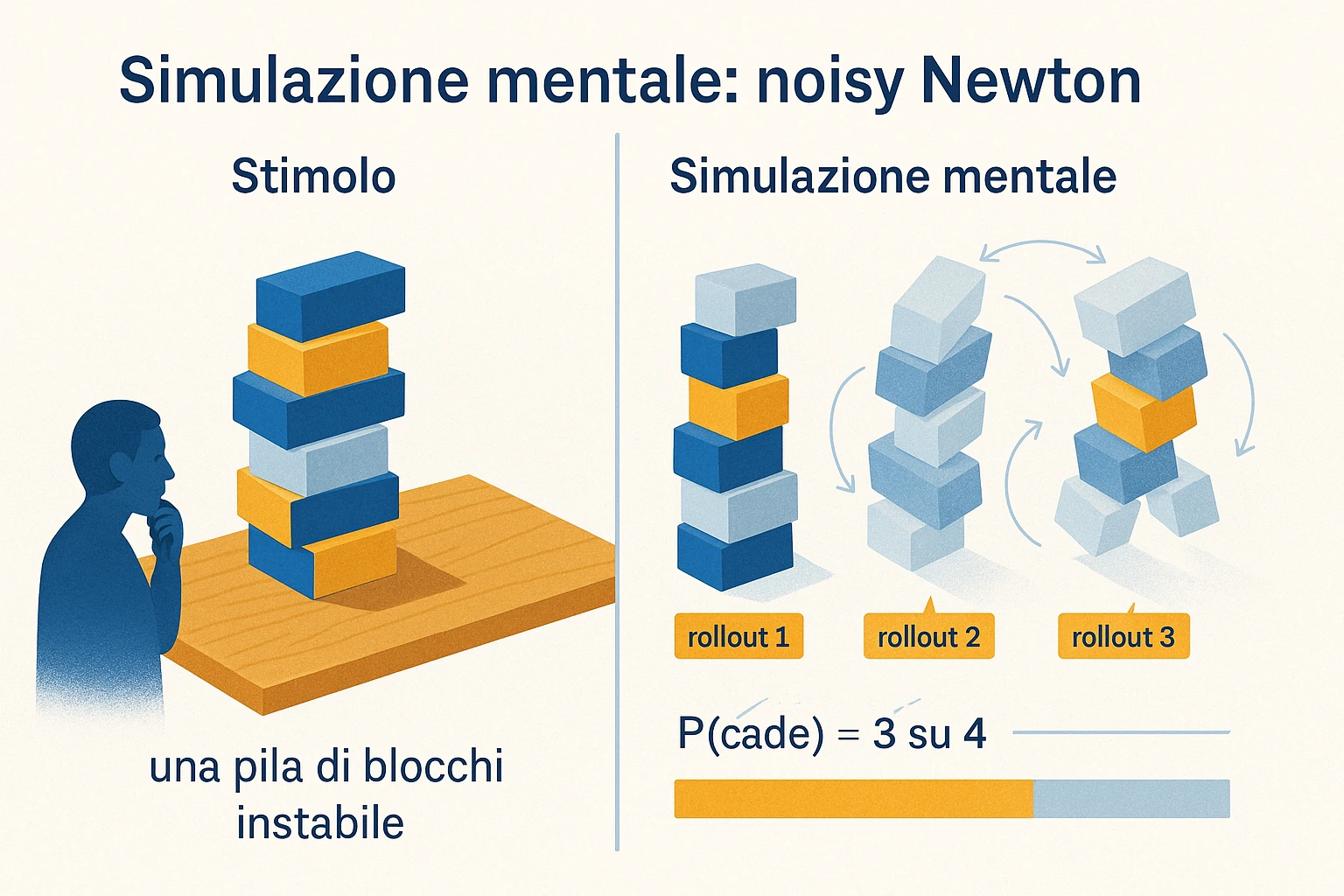
La clinica-empirica. Le evidenze convergono da angolazioni indipendenti. I sillogismi che la model theory predice come “a tre modelli” sono empiricamente quelli su cui la gente sbaglia. La fisica intuitiva di Battaglia-Hamrick-Tenenbaum 2013 mostra che le predizioni umane sulla stabilità di pile di blocchi corrispondono in modo fine a una “noisy Newton” simulation. Le predizioni manageriali nel beer game di Sterman 1989 falliscono in modo sistematico e quantificabile sui feedback loops. Il pattern è lo stesso: un sistema di simulazione interna, potente in alcuni domini, sistematicamente miope in altri, cattura i fenomeni meglio di un sistema di regole.
La terza riguarda chi lavora con agenti AI. La parola world model circola dal 2018 in poi nei paper di RL, e dal 2024 è entrata nel vocabolario di marketing dei video generative models. Senza un’idea precisa di cosa Craik chiamava small-scale model, e di cosa Sterman misura come bounded fidelity, è facile scivolare da analogia a filiazione a equivalenza nello stesso paragrafo. La sezione “Eredità oggi” tratta esplicitamente la distinzione fra world model esplicito (Dreamer, JEPA), world model implicito (Othello-GPT, Gurnee-Tegmark), e video generative model pitchato come simulator (Sora). La distinzione è critica perché le tre cose hanno proprietà funzionali diverse e generano aspettative diverse.
Quattro principi che il capitolo fissa e che torneranno nelle parti successive del libro. Primo: i mental models sono strutture, non immagini. Preservano relazioni rilevanti, non superficie sensoriale. Questo distacca i mental models tanto dall’imagery debate (Kosslyn vs Pylyshyn anni Settanta-Ottanta sulla natura quasi-pittorica delle rappresentazioni mentali) quanto dalla distinzione pixel-vs-latente nei world models AI. Secondo: la simulation è il loro modo d’uso primario; sono fatti per essere “fatti girare” in avanti, all’indietro, controfattualmente. Terzo: sono bounded in modi caratterizzabili — feedback loops, esponenziali, alta dimensionalità causale, composizioni profonde. Le rotture non sono casuali, sono predicibili. Quarto: la mappatura con world models AI è mista — alcuni anelli sono filiazione documentata (Craik → Ha-Schmidhuber → JEPA), altri sono analogia funzionale, altri ancora sono equivalenza marketing pericolosa. Tenerle separate è un servizio al lettore tecnico.
Contesto: la traiettoria 1943-2024
Sezione intitolata “Contesto: la traiettoria 1943-2024”1943 — Craik, The Nature of Explanation. Kenneth Craik (1914-1945, psicologo sperimentale al Psychological Laboratory di Cambridge), Cambridge University Press. Il capitolo quinto formula la tesi: il pensiero opera su small-scale models del mondo. Craik è già noto per lavoro applicato sull’addestramento di piloti durante la guerra; il libro generalizza l’osservazione che gli operatori umani si comportano come servosistemi — predicono lo stato futuro del proprio sistema e correggono in anticipo. Muore nel 1945 in incidente in bicicletta a 31 anni. Il testo verrà ristampato più volte (1952, 1967) e diventerà riferimento per i lavori successivi.
1947 — Wiener, Cybernetics. Norbert Wiener (1894-1964, matematico al MIT), Cybernetics: or Control and Communication in the Animal and the Machine (Wiley/Hermann, 1948 — prima edizione 1947 in francese parziale). Wiener formula la cibernetica come scienza del controllo via feedback, applicabile a macchine e organismi. La connessione con Craik 1943 è di convergenza (Wiener cita Craik nelle riedizioni successive ma non nel testo originale): entrambi propongono che il sistema nervoso operi come un servosistema con modelli interni. La cibernetica diventerà uno dei terreni su cui crescono cognitivismo e AI.
1948 — Tolman, “Cognitive maps in rats and men”. Edward Chace Tolman (1886-1959, psicologo americano a UC Berkeley), in Psychological Review 55:189-208. Tolman è l’eretico del behaviorismo: lavora dentro la tradizione comportamentista ma sostiene che i ratti, per spiegare i loro pattern di scelta, devono avere rappresentazioni interne — cognitive maps — dell’ambiente. Esperimento canonico: ratti che hanno percorso un labirinto in modo X scelgono un short-cut spazialmente coerente quando il path X è bloccato, anche se non hanno mai percorso quel short-cut prima. Una catena S-R pura non lo predice. La filiazione con Craik è di convergenza (Tolman non cita Craik, era post-1945 e Craik non era ancora canonizzato), non di citazione diretta.
1957 — Newell, Shaw, Simon: GPS. General Problem Solver, descritto in dettaglio in bounded-rationality-simon. Means-ends analysis: a ogni passo il programma identifica una differenza fra stato corrente e stato obiettivo e applica un operatore che la riduce. È il primo esempio computazionale di un sistema che opera su un modello interno della struttura del problema. La connessione con Craik è retrospettiva — Newell-Simon non citano The Nature of Explanation — ma la struttura “stato corrente / operatore / stato successivo simulato” rispetta esattamente lo schema small-scale model di Craik 1943.
1960 — Miller, Galanter, Pribram, Plans and the Structure of Behavior. George Miller (1920-2012, psicologo a Harvard, autore del 1956 sul “magical number seven”), Eugene Galanter (1924-2016, psicologo a Penn) e Karl Pribram (1919-2015, neuroscienziato a Stanford), Holt, Rinehart and Winston. Introducono il TOTE unit (Test-Operate-Test-Exit): la struttura di base del comportamento goal-directed è un loop che testa lo stato corrente contro il goal, opera per ridurre la differenza, ritesta. Il libro è uno dei testi fondativi del cognitivismo americano e generalizza la struttura del feedback control engineering ai mental models di goal-pursuit. Ha radici dirette in Wiener cybernetics 1948 e indirette in Craik 1943.
1961/1968 — Forrester e la system dynamics. Jay Wright Forrester (1918-2016, ingegnere elettrico al MIT, fondatore della system dynamics), Industrial Dynamics (MIT Press 1961) e Principles of Systems (Wright-Allen 1968). Forrester veniva da Project Whirlwind, uno dei primi computer real-time, e da SAGE, il sistema di difesa aerea. Trasferisce l’esperienza dei sistemi di controllo all’analisi delle imprese: stocks, flows, feedback loops, delays. Tesi forte di Forrester: i mental models umani che governano le decisioni manageriali sono sistematicamente sbagliati sui sistemi con feedback loops — producono il “counterintuitive behavior of social systems” (titolo del suo articolo del 1971 su Technology Review).
1972 — Tulving, episodica/semantica. Vedi memoria-episodica-semantica. Pertinenza qui: la memoria semantica fornisce il knowledge base su cui si costruiscono i mental models specifici di dominio. Sapere “cosa è una mucca” è precondizione per simulare cosa farà la mucca.
1978 — O’Keefe e Nadel, The Hippocampus as a Cognitive Map. John O’Keefe (1939-, neuroscienziato a UCL, Premio Nobel 2014 con i Moser) e Lynn Nadel (1942-, psicologo a Arizona), Oxford University Press. Identificazione delle place cells — neuroni dell’ippocampo che si attivano in posizioni specifiche dell’ambiente. Il volume formula la tesi che l’ippocampo dei mammiferi implementa la cognitive map di Tolman a livello neurale. Verrà esteso da grid cells (Moser-Moser 2005), boundary cells, head-direction cells, e poi astratto a relazioni non spaziali.
1983 — Johnson-Laird, Mental Models. Philip Nicholas Johnson-Laird (1936-, psicologo cognitivo, allora a Sussex poi a Princeton), Harvard University Press. Il libro fonda la mental model theory of reasoning: per valutare un’inferenza la gente non applica regole logiche formali, costruisce un modello iniziale dei premessi, deriva una conclusione candidata, e cerca un contromodello — una situazione che soddisfi i premessi ma neghi la conclusione. Se non trova contromodelli, accetta. La predizione empirica forte: la difficoltà di un sillogismo è proporzionale al numero di modelli alternativi che bisogna costruire. Sillogismi a un modello sono facili, sillogismi a tre modelli sono dove la maggioranza fallisce. Verifica sperimentale dettagliata negli anni successivi, da Johnson-Laird stesso e da collaboratori (Bara, Bucciarelli).
1983 — Norman, “Some Observations on Mental Models”. Donald Arthur Norman (1935-, scienziato cognitivo a UC San Diego, poi co-fondatore della Nielsen Norman Group), in Dedre Gentner e Albert Stevens (eds.), Mental Models, Lawrence Erlbaum Associates, pp. 7-14. Il volume curato da Gentner-Stevens raccoglie il primo workshop sistematico sul tema; contiene saggi di Johnson-Laird, deKleer-Brown, Larkin, Riley. Il saggio di Norman articola la distinzione poi canonica fra target system (il sistema reale), conceptual model (la sua descrizione formale), mental model (la rappresentazione che l’utente costruisce attraverso l’interazione), scientist’s conceptualization of the user’s mental model (il modello che il ricercatore costruisce per studiare l’utente). Il framework verrà semplificato a tre modelli — designer’s, system image, user’s — in The Design of Everyday Things del 1988.
1989 — Sterman, beer distribution game. John Doerr Sterman (1957-, professore alla MIT Sloan School of Management, allievo di Forrester), “Modeling Managerial Behavior: Misperceptions of Feedback in a Dynamic Decision Making Experiment”, Management Science 35:321-339. Quantificazione sperimentale del bullwhip effect e del costo dei mental models miopi. Setup: una supply chain a quattro stadi (retailer, wholesaler, distributor, factory), 192 soggetti in 48 squadre, 36 settimane simulate. La domanda esogena cambia una volta sola. Il costo medio osservato è dieci volte il costo ottimale ricostruibile per simulazione. Pattern dominante: oscillazioni amplificate, picchi di inventory di 35-40 unità contro il livello stazionario richiesto di circa 16. Il paper resta uno degli esperimenti behavioral più replicati del management science.
1990 — Sutton, Dyna. Richard Sutton (1957-, computer scientist, allora a UMass Amherst, poi a Alberta), “Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming”, in Proceedings of the 7th International Workshop on Machine Learning. Introduce Dyna: un’architettura RL che combina aggiornamenti da esperienza reale con aggiornamenti generati da un model interno del mondo, appreso dall’esperienza stessa. È il primo esempio nell’RL moderno di model-based learning che si avvicina concettualmente alla mental simulation di Craik. Sutton non cita Craik direttamente nel paper Dyna, ma l’architettura ne incarna la struttura.
1994 — Rips, The Psychology of Proof. Lance J. Rips (1944-, psicologo cognitivo a Northwestern University), MIT Press. Difesa esplicita dell’approccio rule-based contro Johnson-Laird: la gente ragiona applicando regole logiche mentali (mental logic), non costruendo modelli. La disputa rule-based vs model-based è uno dei dibattiti più articolati della cognitive science degli anni Novanta. Consenso post-2010: dual mechanism — entrambi i sistemi co-esistono e si attivano in funzione del compito.
1996 — Carey-Spelke, “Science and core knowledge”. Susan Carey (1942-, psicologa dello sviluppo a Harvard) e Elizabeth Spelke (1949-, psicologa dello sviluppo a Harvard), in Philosophy of Science 63:515-533. Tesi: i bambini hanno core knowledge systems — sistemi innati di rappresentazione per dominii base (oggetti fisici, agenti intenzionali, numero, spazio, sociale). Sono mental models impliciti del dominio, costituiti come precondizione dell’apprendimento successivo, non come suo prodotto.
2004 — Hegarty, “Mechanical reasoning by mental simulation”. Mary Hegarty (cognitive scientist a UC Santa Barbara), Trends in Cognitive Sciences 8:280-285. Review delle evidenze: ragionare su sistemi meccanici (pulegge, ingranaggi, leve) attiva regioni motorie e di immagine; i tempi di risposta scalano con la complessità della simulazione (più passi, più tempo); soggetti con migliore mental rotation ability fanno meglio nel mechanical reasoning. La simulazione mentale per la fisica meccanica è un fatto sperimentale.
2007 — Schacter-Addis, constructive episodic simulation. Vedi memoria-episodica-semantica. Pertinenza: l’episodica è un sistema di simulazione temporale; ricordare il passato e immaginare il futuro condividono substrato. È un caso speciale di mental simulation, applicato all’asse temporale.
2017 — Gerstenberg-Tenenbaum, counterfactual simulation. Tobias Gerstenberg (Stanford) e Joshua Tenenbaum, “Intuitive theories” in Oxford Handbook of Causal Reasoning e una serie di paper successivi. Tesi: i giudizi causali umani (“X ha causato Y”) corrispondono ai risultati di una counterfactual simulation — un mental rollout in cui X non accade, e si valuta se Y si sarebbe verificato comunque. Eye-tracking durante il giudizio causale mostra che i soggetti seguono con lo sguardo le traiettorie controfattuali, suggerendo che la simulazione è quasi-percettiva. Il programma estende mental simulation dal regime predittivo (cosa succederà) al regime causale-controfattuale (cosa sarebbe successo).
2010 — Lake, Tenenbaum, e collaboratori — Bayesian Program Learning. Brenden Lake (NYU), Joshua Tenenbaum, e altri, in una serie di paper che culminerà in Lake-Salakhutdinov-Tenenbaum 2015 (Science 350:1332-1338, “Human-level concept learning through probabilistic program induction”). I mental models per il riconoscimento di character handwritten sono modellati come probabilistic programs: programmi piccoli che generano i tratti del carattere. Un modello di questo tipo apprende a riconoscere nuovi caratteri con un singolo esempio, dove le reti neurali standard ne richiedono migliaia. È un’altra dimostrazione operativa del programma “mental models come strutture compositive”.
2011 — Tenenbaum, Kemp, Griffiths, Goodman, “How to grow a mind”. Joshua Tenenbaum (cognitive scientist al MIT), Charles Kemp (CMU), Tom Griffiths (allora Berkeley, poi Princeton), Noah Goodman (Stanford), Science 331:1279-1285. Framework bayesiano per knowledge structures: i mental models sono distribuzioni di probabilità su strutture causali (DAG, grammars, programs). Apprendere è inferenza bayesiana sulla struttura. Spiega la rapidità di generalizzazione dei bambini con pochi esempi.
2013 — Battaglia, Hamrick, Tenenbaum, “Simulation as an engine”. Peter Battaglia, Jessica Hamrick, Joshua Tenenbaum, PNAS 110:18327-18332. Quantificazione fine della fisica intuitiva: predizioni umane sulla stabilità di pile di blocchi match a un modello “noisy Newton” — un physics simulator deterministico con rumore gaussiano sui parametri. È la dimostrazione operativa che la fisica intuitiva è probabilistic mental simulation.
2014 — Moser-Moser e il Premio Nobel per medicina. May-Britt Moser e Edvard Moser (neuroscienziati a NTNU, Trondheim), insieme a John O’Keefe, ricevono il Nobel “per la scoperta delle cellule che costituiscono il sistema di posizionamento del cervello”. Il riconoscimento istituzionale del programma cognitive map come substrato neurale. La citazione del Nobel committee menziona esplicitamente il progresso teorico iniziato con O’Keefe-Nadel 1978 e l’estensione concettuale a cognitive maps astratti (allora già anticipata nei lavori del laboratorio Moser).
2018 — Behrens et al., cognitive maps astratti. Tim Behrens (Oxford) e collaboratori, “What Is a Cognitive Map? Organizing Knowledge for Flexible Behavior”, Neuron 100:490-509. Lo stesso substrato ippocampale-entorhinal codifica anche relazioni non spaziali — gerarchie sociali, alberi di parentela, spazi di task astratti. La cognitive map non è solo spaziale: è la struttura di base per organizzare conoscenza relazionale.
2016 — Constantinescu-O’Reilly-Behrens, “Organizing conceptual knowledge in humans with a gridlike code”. Science 352:1464-1468. fMRI in soggetti che navigano uno spazio concettuale 2D astratto (configurazioni di “uccelli” con collo e gambe variabili) mostrano segnale entorhinal con la simmetria esagonale tipica delle grid cells. Estensione empirica del programma cognitive maps a domini non spaziali. Antecedente diretto della review Behrens 2018.
2018 — Ha-Schmidhuber, “World Models”. David Ha (Google Brain) e Jürgen Schmidhuber (IDSIA), arXiv:1803.10122 (poi NeurIPS 2018). Architettura: un VAE che comprime osservazioni visive in vettori latenti, una RNN che predice il prossimo latente data l’azione, un controller compatto che decide l’azione. L’agente impara prima il world model dall’esperienza, poi addestra il controller quasi interamente “dentro” il world model — facendo rollout immaginari. Il paper apre con una sezione esplicita “Mental Models” che cita la frase di Craik 1943. È il punto in cui la filiazione cognitive science → AI diventa documentata.
2019 — Hafner, Dreamer. Danijar Hafner et al., “Dream to Control: Learning Behaviors by Latent Imagination”, arXiv:1912.01603, ICLR 2020. Successore tecnico di Ha-Schmidhuber 2018. Apprende un latent dynamics model e addestra un actor entirely da rollouts immaginari nel latente. Il termine “latent imagination” nel titolo è un richiamo cosciente al lessico cognitive science.
2020 — Schrittwieser et al., MuZero. Julian Schrittwieser, David Silver, e collaboratori a DeepMind, “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model”, Nature 588:604-609. MuZero apprende un model latente del gioco senza accesso alle regole reali, e fa MCTS dentro il model. Dimostra che model-based planning con un model appreso scala a domini complessi.
2021 — Whittington et al., Tolman-Eichenbaum Machine. James Whittington (Stanford/Oxford) e collaboratori, Cell 183:1249-1263. Modello unificato che spiega place cells, grid cells e cellule per relazioni non spaziali con un singolo meccanismo di learning relazionale. Il nome cita Tolman 1948 e Howard Eichenbaum (neuroscienziato a BU, 1947-2017, pioniere dell’estensione non-spaziale dell’ippocampo).
2022 — LeCun, “A Path Towards Autonomous Machine Intelligence”. Yann LeCun (NYU/Meta, Premio Turing 2018), manifesto OpenReview giugno 2022. Propone JEPA (Joint-Embedding Predictive Architecture): world models che predicono in spazio latente invece che in spazio pixel. Il manifesto è esplicito sulla derivazione da Craik attraverso la tradizione cognitive science: l’agente intelligente deve avere un world model interno, e quel world model è la chiave per l’intelligenza al di là dei pattern di linguaggio.
2023 — Hafner, DreamerV3. Danijar Hafner (DeepMind/Google), arXiv:2301.04104. Versione matura della famiglia Dreamer: stessa architettura encoder/dynamics/value/actor con tuning robusto che permette di battere baseline su 150+ ambienti diversi senza riadattamento dei iperparametri. Punto di stabilità del programma model-based RL.
2023 — Gurnee-Tegmark, “Language Models Represent Space and Time”. Wes Gurnee (MIT) e Max Tegmark (MIT), arXiv:2310.02207. Probing su Llama-2 mostra che le activations interne contengono coordinate geografiche (latitudine, longitudine di città) e datazioni di eventi storici, decodibili linearmente. Estende il pattern Othello-GPT a domini di conoscenza generale. Status: evidenza di rappresentazioni internalizzate, non implementazione di world model esplicito.
2022 — Li et al., Othello-GPT. Kenneth Li (Harvard), Aspen Hopkins (MIT), David Bau (Northeastern), Fernanda Viégas, Hanspeter Pfister, Martin Wattenberg (Harvard/Google), arXiv:2210.13382 poi ICLR 2023. Probing experiment: un GPT trained solo su sequenze di mosse di Othello (notazione PGN-like, nessuna regola esplicita) sviluppa una rappresentazione interna decodibile della board. Un classificatore non-lineare addestrato sulle activations recupera lo stato della scacchiera con accuracy ~99%. Intervento causale (modifica delle activations) cambia le predizioni in modo coerente con la modifica della board. È la prova empirica di un world model implicito — termine che il paper introduce esplicitamente.
2024 — Sora, Veo, Gen-3 come “world simulators”. OpenAI presenta Sora (febbraio 2024) descritto nel post di lancio come “world simulator”. Google segue con Veo, Runway con Gen-3. Sono diffusion-based video models capaci di produrre clip di 5-60 secondi a risoluzione moderata-alta. Lo status epistemico — sono world models in senso Craik/Dreamer, o sono “soltanto” modelli generativi di video — è controverso e discusso in dettaglio nella sezione “Dove si rompe”.
flowchart LR
D["Modello del designer<br/>come l'ingegnere pensa<br/>che il sistema funzioni"]
S["Immagine del sistema<br/>quello che il prodotto<br/>comunica davvero"]
U["Modello dell'utente<br/>quello che l'utente<br/>costruisce dall'interazione"]
D -->|codifica via design| S
S -->|decodifica nell'uso| U
D -.->|allineamento ideale<br/>(raramente diretto)| U
Figura 1 — World model lineage 1943-2024 with documented filiation arrows (solid) and convergence arrows (dashed)
Un grafo che attraversa otto decenni e tre discipline. Vale la pena fermarsi su tre snodi della linea, che meritano un paio di righe in più di contestualizzazione.
Il primo snodo è la coppia Craik 1943 / Tolman 1948. Craik scrive prima, ma muore nel 1945 e il suo libro è poco circolato fino agli anni Sessanta. Tolman scrive nel 1948 senza citare Craik. La somiglianza fra le due proposte — i ratti di Tolman costruiscono una rappresentazione interna spaziale, gli umani di Craik costruiscono small-scale models — è di convergenza, non di filiazione. Sono due autori indipendenti che, dentro il dibattito sul behaviorismo americano-britannico, arrivano a una conclusione affine: serve qualcosa di più della catena S-R per spiegare la flessibilità del comportamento. La storiografia successiva li raggrupperà come precursori del cognitivismo; è una ricostruzione retrospettiva legittima, non una documentazione di filiazione diretta.
Il secondo snodo è il passaggio Johnson-Laird 1983 / Norman 1983 nello stesso anno. Il volume curato da Dedre Gentner (cognitive scientist a Northwestern, allora illinois Institute) e Albert Stevens (BBN Technologies), Mental Models (Erlbaum 1983), è il primo workshop sistematico sul tema. Contiene contributi di Johnson-Laird, deKleer-Brown sul ragionamento qualitativo, Larkin-McDermott-Simon-Simon sulla differenza expert-novice in fisica, McCloskey sui mental models pre-newtoniani, Riley sui mental models di sistemi tecnici. È il momento in cui “mental models” diventa termine ombrello canonico in cognitive science. Da quel volume divergeranno le tradizioni che il capitolo distingue.
Il terzo snodo è la connessione Sutton 1990 / Ha-Schmidhuber 2018. Sutton introduce Dyna come architettura RL pratica; non cita Craik ma ne incarna lo schema. Ventotto anni dopo Ha e Schmidhuber, in “World Models”, aprono il paper con la frase di Craik 1943 e dichiarano la filiazione. L’anello fra Sutton e Ha-Schmidhuber è documentato nei paper RL della famiglia Dyna degli anni Novanta-Duemila (Moore-Atkeson 1993 prioritized sweeping, prioritized experience replay nelle versioni moderne); la filiazione cognitive science → AI passa attraverso questa catena tecnica.
L’intuizione: due angoli prima del formalismo
Sezione intitolata “L’intuizione: due angoli prima del formalismo”I mental models si lasciano introdurre da due angoli distinti. Il primo è cognitivo: il pensiero come simulazione interna. Il secondo è di design: tre modelli che si incontrano nell’interazione fra utente e prodotto. I due angoli convergono sullo stesso nucleo concettuale ma servono predizioni diverse, e vale la pena percorrerli separatamente.
Angolo 1 — cognitivo: pensare è simulare
Sezione intitolata “Angolo 1 — cognitivo: pensare è simulare”Il punto di Craik è radicale e semplice. Pensare non è applicare regole su simboli. È far girare in testa un analogo strutturato del mondo, e leggere il risultato. Non c’è bisogno di provare ogni alternativa nel mondo reale (costoso, rischioso, irreversibile): basta un modello interno fedele abbastanza alla struttura rilevante perché i risultati si possano leggere e usare per decidere.
Questo angolo dà tre osservazioni operative.
Token, non pixel. Il modello interno non è una copia fotografica del mondo. È una rappresentazione strutturata che preserva relazioni rilevanti per il problema. Johnson-Laird parla di token: oggetti astratti che stanno per individui, manipolati secondo le regole della situazione modellata. Per ragionare su “tutti i camerieri qui sono educati”, non serve immaginare un cameriere fotorealistico. Bastano tre token sul taccuino mentale, etichettati “cameriere”, con la proprietà “educato” attaccata. La struttura, non la veste sensoriale, fa il lavoro.
Run forward. Il modello viene “fatto girare” nel tempo. Cosa succederà se faccio X? Cosa sarebbe successo se avessi fatto Y? È la stessa operazione, in versioni diverse, del rollout in MCTS, della simulazione meccanica di Hegarty 2004, della prospezione episodica di Schacter-Addis 2007, del dreaming dentro Dreamer di Hafner 2019. Sono analogie funzionali (lo schema “stato corrente + azione → stato successivo + reward stimato” è lo stesso) che vivono su substrati diversi. Non sono equivalenze implementative.
Confronto con outcome. Quando il modello predice X e il mondo produce Y, il modello viene aggiornato. È lo stesso schema della percezione come inferenza bayesiana di percezione-priors: il sistema mantiene un modello, predice, riceve evidenza, aggiorna. La differenza è di livello e di autonomia: il predictive coding di Rao-Ballard 1999 è sub-personale, automatico, sotto la soglia; la mental simulation di un manager o di un fisico intuitivo è personale, deliberata, accessibile alla coscienza. Entrambi sono casi del pattern “modello interno, predizione, errore, aggiornamento”, ma i due livelli non sono lo stesso meccanismo.
Angolo 2 — design: tre modelli che si incontrano
Sezione intitolata “Angolo 2 — design: tre modelli che si incontrano”Norman 1988 prende il costrutto “mental model” e lo declina nel design dei prodotti. Quando un utente interagisce con un termostato, una porta, un’interfaccia software, ci sono tre modelli in gioco.
Il designer’s model è come il progettista pensa che il sistema funzioni. Riflette la struttura ingegneristica, le componenti interne, i flussi di causa-effetto fra i moduli. È il modello esplicito che vive nei documenti di progetto.
La system image è cosa il sistema effettivamente comunica all’utente attraverso forma, etichette, feedback, manuale, packaging. È l’unica cosa che l’utente percepisce direttamente; il designer’s model è invisibile salvo per come si lascia tradurre in system image.
Lo user’s model è cosa l’utente costruisce mentalmente come spiegazione del sistema, basandosi sulla system image e sull’interazione. Non corrisponde necessariamente al designer’s model: corrisponde all’interpretazione coerente che l’utente sa farsi di quel che vede.
Il sistema funziona quando lo user’s model converge sufficientemente al designer’s model. Gli errori di usabilità non sono “stupidità dell’utente”: sono mismatch fra modelli. Esempio canonico: la “Norman door” — una porta con maniglia a barra orizzontale che invita a tirare ma che va spinta. Il fenomeno è così riconoscibile che il termine è entrato nel vocabolario del design.
L’angolo design dà tre osservazioni complementari a quello cognitivo.
Affordances, prese da James J. Gibson (1979, The Ecological Approach to Visual Perception) e riconcettualizzate da Norman come perceived affordances — quello che l’utente coglie come uso possibile, non quello che l’oggetto offre fisicamente. Una maniglia a barra ha l’affordance fisica del tirare e del spingere; la sua perceived affordance, per la maggior parte degli utenti, è solo il tirare. Il design buono allinea perceived affordance e azione effettiva.
Visibility. Un sistema con designer’s model complesso ma system image opaca produce errori sistematici. Le interfacce buone fanno emergere lo stato interno: indicatori di modo, breadcrumb di posizione, log di azioni recenti, undo visibile. Visibility non significa esposizione di tutto, significa esposizione del necessario per costruire un user’s model corretto.
Conceptual mapping. Lo user’s model non deve essere fisicamente preciso, deve essere predittivamente utile. Un termostato a manopola che “scalda di più se lo metti più alto” è un mental model imperfetto (la maggior parte dei termostati domestici sono on-off con isteresi, non variatori continui) ma sufficiente per l’uso quotidiano. Il problema nasce quando lo user’s model imperfetto produce predizioni sbagliate in un caso non standard — ad esempio “metto il termostato al massimo per scaldare più velocemente”, basato su un mental model “potenza scalabile” invece che on-off.
La meccanica
Sezione intitolata “La meccanica”Mental model theory of reasoning (Johnson-Laird)
Sezione intitolata “Mental model theory of reasoning (Johnson-Laird)”Per valutare un’inferenza, secondo la teoria, il ragionatore costruisce un modello iniziale dei premessi, deriva una conclusione candidata, e prova a costruire un contromodello — una situazione che soddisfi i premessi ma neghi la conclusione. Se non trova contromodelli, accetta la conclusione. La validità qui è limitata dalla ricerca: una conclusione accettata è valida nel limite dei modelli effettivamente esplorati, non in senso assoluto.
Esempio canonico. Premessi: “Tutti gli A sono B. Alcuni B sono C.” Conclusione candidata: “Alcuni A sono C.” Modello iniziale, in notazione di Johnson-Laird:
[a] = [b] = [c][a] = [b] = [c][a] = [b] [b] [b] = [c]Le righe sono individui; i token in colonna sono predicati assegnati a ciascun individuo; le parentesi quadre stanno per “esaustivamente rappresentato” (non possono esistere altri a, altri b, altri c oltre quelli mostrati senza notazione esplicita). In questo modello iniziale ci sono individui che sono A, B e C insieme, quindi “alcuni A sono C” sembra valida.
Ma esiste un contromodello:
[a] = [b][a] = [b] [b] = [c] [b] = [c]Qui tutti gli A sono B, alcuni B sono C, ma nessun A è C. Conclusione invalida. La gente che non costruisce questo contromodello sbaglia il sillogismo. La predizione empirica è: i sillogismi che richiedono di costruire più modelli (per testare la validità) sono sistematicamente più difficili. Verifica negli anni Ottanta-Novanta: errori e tempi di risposta scalano con il numero di modelli richiesti.
Notazione di Johnson-Laird in dettaglio. Le righe sono individui ipotetici. I token sono predicati assegnati a ciascun individuo. La parentesi quadra [a] significa “esaustivamente rappresentato”: tutti gli a esistenti sono in questa colonna; non si possono aggiungere a in un’eventuale estensione del modello senza notazione esplicita di “altri individui implicitamente”. Le righe nuove sono individui nuovi rispetto a quelli già listati. Una conclusione si dice valida rispetto a un modello se è vera nel modello; necessariamente valida se è vera in ogni modello dei premessi (il che, in pratica, vuol dire “non si trovano contromodelli durante la ricerca”). La predizione empirica si traduce così: i sillogismi che richiedono di costruire un solo modello iniziale per accettare la conclusione sono facili; quelli che richiedono di costruire due o tre modelli alternativi (perché il primo sembra confermare ma un secondo lo smentisce) sono progressivamente più difficili. Bara-Bucciarelli-Johnson-Laird (1995, Cognition 57:33-97) hanno fornito la verifica psicometrica fine: errori, tempi, e self-reported strategy correlano con la “model complexity” della teoria.
Cognitive maps (Tolman → O’Keefe-Nadel → Behrens)
Sezione intitolata “Cognitive maps (Tolman → O’Keefe-Nadel → Behrens)”Il programma cognitive map ha tre stadi. Tolman 1948: i ratti devono avere una rappresentazione interna dell’ambiente, perché scelgono short-cut spazialmente coerenti. O’Keefe-Nadel 1978: il substrato neurale è l’ippocampo; le place cells si attivano in posizioni specifiche dell’ambiente; la mappa è plurale (un’ambiente nuovo, una mappa nuova) e relazionale (codifica vicinanza, contenimento, direzioni). Behrens 2018: lo stesso meccanismo si applica a relazioni non spaziali — gerarchie sociali, alberi di parentela, spazi di task. La cognitive map è il framework di base con cui il cervello dei mammiferi organizza la conoscenza relazionale, spaziale o astratta che sia.
Pertinenza per i mental models: la cognitive map è la componente strutturale-relazionale di un mental model. Sapere “Roma a sud di Firenze, Firenze a sud di Bologna” è una cognitive map astratta dell’Italia centrale. Ragionare “se vado da Roma a Bologna passo da Firenze” è far girare un piccolo rollout dentro la mappa. La separazione mappa / rollout corrisponde, a livello concettuale, alla separazione world model / planner di Sutton 1990.
Mental simulation per fisica intuitiva (Battaglia 2013)
Sezione intitolata “Mental simulation per fisica intuitiva (Battaglia 2013)”Il modello: il cervello mantiene un physics simulator approssimato — masse, posizioni, forze, attriti, dinamica di contatto. Quando deve predire l’esito di una situazione fisica, campiona N rollouts del simulatore, ognuno con rumore gaussiano sui parametri non osservabili (massa esatta, attrito, posizione precisa). Il risultato è una distribuzione di esiti; la predizione è una statistica della distribuzione (frazione che cadono, direzione media di caduta, eccetera).
Battaglia-Hamrick-Tenenbaum 2013 implementano l’idea con un physics engine off-the-shelf (Bullet) e parametri di noise calibrati. Su 60 configurazioni di pile di blocchi, i soggetti predicono “cadrà o resterà in piedi?”. Le frequenze di “cadrà” predette dal modello noisy-Newton e quelle prodotte dai soggetti correlano fortemente. Confronti: un modello geometrico statico (centro di massa sopra la base) correla molto meno; un modello di feature visuali correla quasi zero. Il pattern è coerente con la tesi: la fisica intuitiva è simulazione, non regola euristica statica.
Importante: il modello non assume che il cervello esegua un physics engine identico a Bullet. Assume che il cervello esegua qualche simulatore approssimato la cui statistica di output match quella di un physics engine con noise. È un’ipotesi computazionale-livello-Marr: descrive cosa il sistema calcola, non come. La domanda implementativa — quale circuito neurale fa la simulazione, con che precisione, con che frequenza temporale — è separata, e meno risolta. Studi successivi (Hamrick et al. 2016, Smith et al. 2018) hanno esteso il programma a scene più complesse (collisioni multi-oggetto, dinamica di liquidi semplici) confermando il pattern noisy-physics-engine.
Una conseguenza didattica utile. Il programma noisy-Newton predice che gli errori umani non sono uniformi: sono calibrati al rumore. Configurazioni chiaramente stabili o chiaramente instabili producono predizioni nette; configurazioni al limite producono predizioni intermedie e ad alta varianza. Le risposte umane mostrano esattamente questo pattern. Un modello di regole statiche non lo predice in modo altrettanto fine.
Cognitive maps astratti (Behrens 2018) — dettaglio
Sezione intitolata “Cognitive maps astratti (Behrens 2018) — dettaglio”L’estensione di Behrens et al. 2018 merita una passata in più. La review Neuron raccoglie evidenze da tre fonti distinte e le integra. Primo: studi fMRI in cui soggetti navigano “spazi” non spaziali — gerarchie sociali (chi ha competenza in che dominio), alberi di parentela, spazi di task in cui gli stati sono concetti astratti — mostrano attivazione in entorhinal cortex con pattern compatibili con la struttura dello “spazio” navigato. Secondo: registrazione single-unit in scimmie (Aronov-Nevers-Tank 2017, Constantinescu-O’Reilly-Behrens 2016) rivela cellule simili a place cells e grid cells per coordinate non spaziali. Terzo: modelli computazionali (Whittington et al. 2020 “Tolman-Eichenbaum Machine”) propongono un meccanismo unificato — un sistema relazionale generale di cui la mappa spaziale è un caso particolare.
Conseguenza: i mental models specifici-di-dominio non sono moduli separati. Condividono substrato e regole strutturali con la cognitive map spaziale. È una forma di parsimonia che il cervello sembra implementare e che, in retrospettiva, era già adombrata dal Hippocampus as a Cognitive Map del 1978. La cognitive map non è un’analogia con i mental models astratti — ne è la struttura comune.
System dynamics e bounded fidelity (Sterman 1989)
Sezione intitolata “System dynamics e bounded fidelity (Sterman 1989)”Quattro stadi di una supply chain: retailer (vende al cliente), wholesaler (rifornisce il retailer), distributor (rifornisce il wholesaler), factory (produce). Ogni stadio gestisce inventory e ordini al livello superiore. C’è un lead time di consegna fra stadi (tipicamente 4 settimane simulate) e un lead time di produzione alla factory.
La domanda esogena al retailer: 4 unità a settimana per le prime 4 settimane, poi 8 unità a settimana costante per le rimanenti. Step singolo, mai annunciato.
Risultato osservato in 48 squadre: oscillazioni amplificate. Il retailer alza gli ordini, il wholesaler sovrareagisce perché vede gli ordini del retailer salire, il distributor sovrareagisce ancora di più. La factory amplifica al massimo. I picchi di inventory upstream raggiungono 35-40 unità contro un livello stazionario richiesto di circa 16. Il costo medio per partecipante è circa dieci volte il costo ottimale ricostruibile per simulazione lineare-quadratica.
La causa, ricostruita da Sterman con regressione sui pattern di ordine individuali: i partecipanti sotto-pesano sistematicamente l’inventory in transito (gli ordini già piazzati ma non ancora arrivati) quando decidono i nuovi ordini. Trattano la situazione come se l’inventory in transito non esistesse. Il loro mental model non simula il delay. Risultato: ordinano troppo, poi vedono arrivare tutto insieme, sovrareagiscono nell’altro senso, e così via.
È bounded fidelity quantificata. Il mental model umano funziona per stocks senza delay; fallisce per stocks con delay nel feedback.
Intuitive theories e Bayesian framework (Tenenbaum 2011)
Sezione intitolata “Intuitive theories e Bayesian framework (Tenenbaum 2011)”Il programma Tenenbaum prende i mental models e li formalizza come distribuzioni di probabilità su strutture causali. Uno spazio di ipotesi H di possibili strutture causali (DAG, grammars, programs); un prior P(h); una likelihood P(d|h); il posterior P(h|d) ∝ P(d|h) × P(h) è il mental model corrente.
L’apprendimento è inferenza bayesiana sulla struttura. Spiega come bambini molto piccoli, con pochi esempi, generalizzano a strutture astratte: il prior comprende strutture preferite (gerarchie ad albero, relazioni causali sparse, principi di parsimonia), e l’inferenza bayesiana su quelle strutture amplifica le poche evidenze osservate. È la versione formale della “theory theory” di Alison Gopnik (psicologa a Berkeley): il bambino come piccolo scienziato che testa ipotesi.
World models in RL: Dyna e la sua eredità (per il bridge AI)
Sezione intitolata “World models in RL: Dyna e la sua eredità (per il bridge AI)”La struttura algoritmica di Dyna 1990 vale la pena vederla nel dettaglio, perché è il punto in cui mental simulation di Craik diventa codice eseguibile.
Pseudocodice essenziale di Dyna-Q (versione descritta da Sutton-Barto, Reinforcement Learning: An Introduction, MIT Press, prima edizione 1998):
inizializza Q(s, a) per ogni s, ainizializza Model(s, a) come dizionario vuotoripeti per sempre: s = stato corrente a = scegli azione da Q (epsilon-greedy) esegui a, osserva s', r Q(s, a) += alpha * (r + gamma * max_a' Q(s', a') - Q(s, a)) # update da esperienza reale Model(s, a) = (s', r) # aggiorna world model ripeti N volte (planning): s_p, a_p = scegli (s, a) già visitati s'_p, r_p = Model(s_p, a_p) Q(s_p, a_p) += alpha * (r_p + gamma * max_a' Q(s'_p, a') - Q(s_p, a_p)) # update da rollout immaginarioTre cose da notare. Primo, c’è un singolo aggiornamento da esperienza reale per ogni passo nel mondo, e N aggiornamenti da esperienza simulata. Il numero N controlla il rapporto fra learning reale e learning immaginato; con N=0 si ricade nel Q-learning standard, con N grande si ricade in un agente che impara quasi tutto dalla simulazione (richiamo diretto a Craik: “try out various alternatives, conclude which is the best of them”). Secondo, il world model è esplicito: Model(s, a) è un dizionario che memorizza l’esperienza; è una rappresentazione tabulare e perfetta per ambienti deterministici discreti, sostituita poi da reti neurali in versioni successive. Terzo, l’architettura separa policy (la cosa che agisce, codificata in Q) da model (la cosa che predice, codificata in Model). Questa separazione è il cuore del paradigma model-based, e torna identica in Dreamer e MuZero trent’anni dopo.
Da Dyna 1990 a Dreamer 2019 c’è continuità tecnica via prioritized sweeping (Moore-Atkeson 1993), Sutton-Barto 1998 capitolo 9, R-MAX (Brafman-Tennenholtz 2002), Linear Dyna (Sutton 2008), PILCO (Deisenroth-Rasmussen 2011 con world models gaussiani), Ha-Schmidhuber 2018 (VAE+RNN). Ogni passaggio sposta il world model verso architetture più espressive (da tabella a rete neurale a latente compresso) ma mantiene lo schema “modello esplicito + planning dentro”.
Esempio 1 — Battaglia-Hamrick-Tenenbaum 2013, fisica intuitiva di blocchi
Sezione intitolata “Esempio 1 — Battaglia-Hamrick-Tenenbaum 2013, fisica intuitiva di blocchi”Setup. Sessanta configurazioni di pile di otto-dieci blocchi colorati (rossi, blu, gialli) su una base grigia. I blocchi sono leggermente sfalsati per produrre situazioni ambigue — a volte chiaramente stabili, a volte chiaramente instabili, spesso ai limiti. Soggetti umani vedono ogni configurazione e rispondono a due domande: “questa pila cadrà?” e “in che direzione?”. Quaranta soggetti, ogni configurazione vista da tutti.
Modello noisy-Newton. Si usa un physics simulator (Bullet, fisica rigida 3D, gravità standard, contatti con attrito statico e dinamico). I parametri non osservabili sono trattati come variabili aleatorie: posizione di ciascun blocco con rumore gaussiano σ ≈ 0.1 (in unità di lato del blocco), attrito con rumore σ ≈ 0.3 attorno a un valore medio. Per ogni configurazione si campionano N=100 rollouts; per ciascun rollout si simula 2 secondi e si registra se la pila è caduta. La predizione del modello è la frazione di rollouts in cui la pila cade.
Risultato. Correlazione fra predizioni del modello e probabilità medie dei soggetti: circa r ≈ 0.86. Confronti: un modello geometrico statico (centro di massa proiettato sopra la base) ha correlazione circa r ≈ 0.43. Un modello di sole feature visive (numero di blocchi, altezza, sbilanciamento approssimato) ha correlazione vicina allo zero. La direzione di caduta predetta dal modello noisy-Newton coincide con quella media dei soggetti in larga maggioranza dei casi.
Interpretazione. Il cervello non applica regole geometriche statiche tipo “il centro di massa deve cadere dentro la base”. Fa girare un piccolo numero di simulazioni mentali con rumore sui parametri non osservabili, e legge una statistica del risultato. È mental simulation operativa, non euristica visuale. Esempio numerico pulito di Craik 1943 implementato e misurato.
Esempio 2 — Sterman 1989, beer game
Sezione intitolata “Esempio 2 — Sterman 1989, beer game”Setup. Quattro ruoli — retailer, wholesaler, distributor, factory — connessi in catena. Ogni stadio ha un inventory iniziale di 12 unità e un livello di ordini in transito di 4 unità per i lead time iniziali. Lead time di consegna fra stadi: 4 settimane simulate (2 di processing, 2 di transit). La factory ha un lead time di produzione di 4 settimane.
Domanda esogena al retailer: 4 unità a settimana per le settimane 1-4, poi 8 unità a settimana costante per le settimane 5-36. Step singolo, mai annunciato. Il livello stazionario di inventory richiesto, calcolabile esattamente, è 16 unità per stadio.
Soggetti: 192 manager e studenti MBA al MIT Sloan, in 48 squadre da 4. Ognuno gestisce un ruolo, vede solo il proprio inventory, gli ordini del livello inferiore, i propri ordini in transito. Decide quante unità ordinare al livello superiore ogni settimana.
Risultato. Pattern dominante in tutte le squadre: oscillazioni amplificate dal basso verso l’alto (bullwhip effect). Picco di inventory: 35-40 unità nei livelli upstream, con valore medio di circa 25 contro lo stazionario di 16. Costo totale per squadra: media osservata 0.50 per unità di inventory in eccesso, 200. Rapporto: dieci a uno.
Causa identificata via regressione. I soggetti pesano gli ordini correnti del cliente diretto e l’inventory on-hand, ma sotto-pesano sistematicamente l’inventory in transito (gli ordini già piazzati ma non ancora arrivati). Il loro mental model non simula correttamente il delay. Quando vedono inventory scendere, ordinano per ricoprire, dimenticando che hanno già ordini in arrivo che li ricopriranno.
Interpretazione. Il mental model umano funziona bene per stocks istantanei (“questo magazzino ha tot pezzi”). Fallisce per stocks dinamici con delay nei feedback (“ho già ordinato, arriverà fra due settimane”). È bounded fidelity quantificata su un esperimento riproducibile, e una delle evidenze più nette del programma di Forrester.
Esempio 3 — Othello-GPT (Li et al. 2022)
Sezione intitolata “Esempio 3 — Othello-GPT (Li et al. 2022)”Setup. Si addestra un GPT in stile decoder-only (configurazione GPT-2-style, 8 layer, 8 head, ~25M parametri) su 20 milioni di sequenze di partite di Othello. Le sequenze sono in notazione PGN-like: una mossa per token, ogni token codifica una casella (A1-H8). Nessuna regola del gioco viene fornita; nessuna rappresentazione esplicita della board; nessun reward signal. Il task è puro next-token prediction sulla sequenza di mosse.
Probing. Dopo l’addestramento, si congela il modello. Si addestra un classificatore non-lineare (un MLP a 2 layer) sulle activations di un layer interno del modello, con il task di predire — per ogni casella della board, dato l’input della sequenza fino a quel punto — lo stato della casella (vuota, mia, avversaria) nella board che corrisponderebbe alla sequenza giocata. Risultato: accuracy ~99% sullo stato corrente della board, decodibile dalle activations di layer intermedi.
Intervento causale. Si modificano le activations corrispondenti a una specifica casella (per spingere il classificatore a “vedere” la casella in uno stato diverso) e si lasciano propagare in avanti. Le predizioni del modello sulle mosse legali successive cambiano in modo coerente con la modifica della board. Non è solo correlazione: il modello usa la rappresentazione interna per generare predizioni.
Interpretazione. Un sistema addestrato solo su sequenze di mosse — senza conoscenza esplicita delle regole, della board, del gioco — sviluppa una rappresentazione interna ricostruibile dello stato del gioco. È un world model implicito, emergente da next-token prediction su un task strutturato. Il paper introduce esplicitamente il termine “world model” e cita Craik 1943.
Importante: questo è evidenza di una rappresentazione, non implementazione del framework Craik nello stesso senso di Dreamer o JEPA. Non c’è un modulo separato che rappresenta il mondo e fa rollouts dentro; c’è un modello unico le cui activations contengono informazione decodibile sullo stato. La distinzione fra esplicito e implicito è critica per non confondere i due tipi di world model.
timeline
title Lineage dei world model 1943-2024
1943 : Craik — modello in piccola scala della realtà esterna
1948 : Tolman — mappe cognitive nei ratti e negli uomini (convergenza)
1983 : Johnson-Laird — modelli mentali del ragionamento (convergenza)
1990 : Sutton (Dyna) — model-based RL (cita la tradizione di Craik)
2018 : Ha & Schmidhuber (World Models) — VAE + RNN + controller, cita Craik
2022 : LeCun (JEPA) — joint-embedding predictive architecture
Figura 3 — Intuitive physics simulation: stack of blocks stimulus and four ghost rollouts of noisy Newton predicting fall direction
Esempio 4 — Norman door e mismatch fra mental models
Sezione intitolata “Esempio 4 — Norman door e mismatch fra mental models”Un esempio che non richiede laboratorio. Una porta a vetri all’ingresso di un edificio universitario, con maniglia verticale a barra su entrambi i lati. La maniglia ha l’affordance fisica di poter essere sia tirata sia spinta: una barra cilindrica orizzontale o verticale è simmetrica rispetto a quelle due azioni. Ma la perceived affordance per la maggior parte degli utenti è il tirare: una mano che si chiude attorno a una barra trova naturale tirarla a sé.
Il designer della porta ha un modello: il chiudiporta funziona meglio se la porta si apre verso l’esterno, quindi va spinta dall’interno e tirata dall’esterno. Designer’s model coerente. La system image — la maniglia identica sui due lati — non comunica questa asimmetria. Lo user’s model che si forma è “questa maniglia si tira” su entrambi i lati. Risultato: dall’interno, l’utente tira invece di spingere, sbatte contro la porta o è costretto a una correzione goffa.
Il fenomeno si vede ovunque: porte che richiedono cartelli “PUSH” / “PULL” perché l’affordance non è chiara, manopole che richiedono indicatori di rotazione perché senza non si capisce in che senso girarle, schermate software con bottoni il cui label non corrisponde all’azione. Ogni cartello esplicativo è la documentazione di un mismatch: il designer ha dovuto comunicare verbalmente quello che la system image non riesce a comunicare strutturalmente.
L’esempio non ha numeri come Battaglia 2013 o Sterman 1989, ma ha un valore complementare: mostra che i mental models non sono solo dentro la testa, sono prodotti dall’interazione con artefatti del mondo. Il designer plasma lo user’s model attraverso ogni scelta di forma, di etichetta, di feedback. Quando il design è opaco, lo user’s model converge a una configurazione disfunzionale e gli errori sono inevitabili.
Eredità oggi
Sezione intitolata “Eredità oggi”[DATATO 2026-04] La sezione registra lo stato dei world models in AI al momento di scrittura, e marca esplicitamente la classe di ciascuna affermazione (filiazione documentata, analogia funzionale, equivalenza pericolosa).
La traiettoria mental models cognitive science → world models AI è un caso raro di filiazione documentata che attraversa tre discipline. La catena di citazioni esiste: Craik 1943 viene citato esplicitamente da Ha-Schmidhuber 2018 in apertura del paper “World Models”, che a sua volta è citato da LeCun 2022 nel manifesto JEPA. Sutton 1990 (Dyna) sta nel mezzo come anello di collegamento dell’RL model-based, ma non cita Craik direttamente; la convergenza Sutton-Craik è resa esplicita da chi è venuto dopo.
Quattro famiglie di sistemi attuali, da distinguere con cura.
World models espliciti per RL. Architetture in cui un modulo separato apprende a predire next state (in pixel o latente) data l’azione, e un controller separato fa planning dentro il model. La famiglia Dreamer di Hafner et al. (2019, 2020, 2023) è il filone più sviluppato: encoder che comprime osservazioni in latent state, dynamics model che predice latent states futuri, reward predictor, value head, actor che decide azioni. Il training del policy avviene quasi interamente nei rollout immaginari del world model. MuZero di Schrittwieser et al. 2020 è una variante per giochi: model latente appreso senza accesso alle regole, MCTS dentro il model. Per questa famiglia la filiazione con Craik è ben documentata: Ha-Schmidhuber 2018 cita la frase del 1943, Hafner cita Ha-Schmidhuber, e così via.
JEPA e world models predittivi in spazio latente. LeCun 2022 propone una variante: invece di predire pixel futuri, predici embeddings futuri condizionati su embeddings correnti, addestrati con joint embedding objective che evita la trappola di “voler predire ogni pixel”. I-JEPA (Assran et al. 2023) e V-JEPA (2024) sono implementazioni operative su immagini e video. Status concettuale: filiazione esplicita con la tradizione mental models (LeCun cita Craik nella sezione introduttiva del manifesto), differenza tecnica con Dreamer sulla scelta del target di predizione.
World models impliciti emergenti. Othello-GPT (Li et al. 2022) e Gurnee-Tegmark 2023 (“Language Models Represent Space and Time”) sono evidenze empiriche di rappresentazioni interne decodibili in modelli addestrati a obiettivi diversi (next-token prediction). Status: evidenza di rappresentazioni, non implementazione del framework Craik nel senso di un modulo dedicato che fa rollouts. Distinzione critica per non confondere i due tipi.
Generative video models pitchati come world simulators. Sora di OpenAI (febbraio 2024), Veo di Google (2024), Gen-3 di Runway (2024) sono diffusion-based video models che producono video plausibili da prompt. Pitch di marketing: “world simulators”. Status epistemico controverso. Predire video plausibili a 60 secondi non implica avere un world model usable per planning in modo Dreamer-style. Le metriche su consistenza fisica (oggetti che obbediscono a conservation laws nel video, persistenza di scene attraverso occlusion) restano debole; la valutazione come world model è prematura nella letteratura 2024-2026.
Equivalenze pericolose da non scivolare:
- “Mental model umano è un world model AI”. Analogia funzionale produttiva (entrambi sono modelli interni del mondo con cui simulare alternative); equivalenza implementativa errata (mental models umani sono multi-modali, embedded nel corpo, sviluppati per evoluzione e ontogenesi; world models AI sono moduli artificiali allenati su dati specifici).
- “LLM è un world model”. Parzialmente vero per probing-style results (Othello-GPT, Gurnee-Tegmark): l’LLM contiene rappresentazioni decodibili di spazio, tempo, stato di giochi specifici. Funzionalmente non equivalente a Dreamer: l’LLM non fa rollouts espliciti, non separa model e controller, non offre le proprietà di planning di un sistema model-based.
- “Predictive coding cervello è next-token prediction LLM”. Già discussa in percezione-priors. Convergenza concettuale (entrambi minimizzano errore di predizione), divergenza implementativa (gerarchia, modalità, scala temporale, embedding fisico).
- “Sora è un mental model fisico”. Video plausibile alla osservazione casuale non implica rappresentazione causale usable. Marketing claim, non risultato scientifico al 2026.
La regola pratica per leggere paper su world models in AI: chiedere sempre dove vive il modulo che predice next state, come è addestrato, come si fa planning dentro. Le tre domande separano architetture vere da analogie imprecise.
Dove si rompe
Sezione intitolata “Dove si rompe”I mental models sono potenti ma bounded. Le rotture sono di tre tipi: bounded fidelity sulla struttura del mondo, mismatch fra modelli diversi nello stesso agente, equivalenze AI che falliscono.
Bounded fidelity sui feedback loops e i delays. Sterman 1989 è il caso paradigmatico. I mental models umani simulano bene stocks istantanei, male stocks con delay. La conseguenza è strutturale, non aneddotica: ogni sistema con feedback ritardato — supply chain, politiche pubbliche, dinamiche climatiche, dosaggio terapeutico — è dominato da bias sistematici nei mental models di chi lo gestisce. Soluzioni operative: simulazioni esterne (computer-based simulations come strumento di pensiero), metriche che rendono visibili i delays, design che disaccoppia decisioni rapide da effetti lenti.
Bounded fidelity sui processi esponenziali. Sterman e altri hanno documentato la “exponential growth misperception”: i soggetti predicono crescita lineare quando il sistema cresce esponenzialmente. Esempio illustrativo classico: COVID-19 marzo 2020. Un raddoppiamento dei casi ogni tre giorni produce, in tre settimane, un fattore 128. Mental models lineari sottostimavano cronicamente le proiezioni; i sistemi sanitari basati su mental models lineari pianificavano per crescite lineari e venivano superati. Il pattern è strutturale: l’intuizione umana sui valori futuri di processi moltiplicativi è sistematicamente sbagliata.
Misconceptions in fisica. John Clement (1982), “Students’ Preconceptions in Introductory Mechanics”, American Journal of Physics 50:66-71, documenta che studenti di ingegneria al primo anno mantengono mental models pre-newtoniani (impeto, “la forza segue il moto”) nonostante l’istruzione formale. I mental models radicati resistono all’istruzione esplicita; cambiarli richiede confronto diretto con casi che il mental model errato non riesce a simulare correttamente.
Michael McCloskey (1983, “Intuitive physics”, Scientific American 248(4):122-130) racconta esperimenti più drammatici. Setup: un soggetto vede una pallina che esce orizzontalmente da un tubo curvo a forma di spirale. Domanda: che traiettoria seguirà la pallina dopo l’uscita? Risposta corretta (newtoniana): la pallina prosegue in linea retta nella direzione della velocità all’uscita. Risposta tipica del soggetto: la pallina continua a girare in spirale per un po’ prima di rettilinearsi, perché ha “memoria” del moto curvilineo. Il mental model è impetus theory medievale, ovvio per chiunque guardi un sasso lanciato (sembra che decelleri “perché finisce l’impeto”) ma falso. McCloskey trova lo stesso pattern in studenti universitari di scienze, in popolazioni adulte non-scientifiche, e — in modo attenuato — anche dopo corsi di fisica. Cambiare un mental model fisico radicato richiede più di una lezione.
Belief perseverance. Anderson, Lepper, Ross (1980), “Perseverance of Social Theories”, Journal of Personality and Social Psychology 39:1037-1049. Esperimento: i soggetti formano un mental model causale sulla base di evidenze fittizie (“le persone con voti alti sono più empatiche”); poi vengono informati che le evidenze erano completamente fabbricate; il mental model persiste. La spiegazione causale costruita si auto-sostiene, e l’evidenza disconfermante non basta a smontarla. È un limite strutturale del processo di costruzione del modello: una volta che il modello rende intelligibile il mondo, scartarlo richiede più che l’invalidazione del dato che lo ha originato.
Curse of knowledge. L’esperto non simula bene il mental model del novizio. Conseguenze in didattica (l’insegnante salta passaggi che per il novizio sono il punto critico), in interface design (il designer non vede gli ostacoli che l’utente vede), in pair programming (il senior non capisce dove il junior si è bloccato). La ragione è che il mental model esperto, una volta interiorizzato, è opaco al richiamo cosciente: l’esperto sa, ma non sa cosa sapeva prima.
L’evidenza sperimentale è abbondante. Camerer-Loewenstein-Weber (1989, Journal of Political Economy 97:1232-1254) mostrano in esperimenti di mercato che traders informati su un valore fondamentale non riescono a non far trapelare l’informazione nei prezzi proposti, anche quando dovrebbero. Newton (1990, dissertation Stanford, “tappers and listeners”) chiede a soggetti di battere col dito il ritmo di canzoni famose; i tapper predicono che il 50% degli ascoltatori indovinerà la canzone, in realtà la indovina meno del 3%. È il tipico curse of knowledge: il tapper sente la melodia nella propria testa mentre batte, e non riesce a simulare l’esperienza dell’ascoltatore che sente solo la sequenza di battiti.
In didattica della programmazione, il pattern è epidemico. Un senior che spiega un debug “ovviamente bisogna controllare il return code della system call” non simula il modello del junior che non ha ancora costruito l’aspettativa che ogni system call possa fallire. Lo scaffolding pedagogico esiste esattamente per compensare il curse of knowledge: rendere espliciti i passaggi che l’esperto fa automaticamente.
Disputa rule-based vs model-based reasoning. Lance Rips (1994) ha sostenuto contro Johnson-Laird che la gente applica regole logiche mentali, non costruisce modelli. Il dibattito è durato decenni. Consenso post-2010: dual mechanism — entrambi i sistemi co-esistono. Il rule-based si attiva preferenzialmente per dimostrazioni formali, problemi che abbiano appreso da training esplicito; il model-based si attiva per situazioni nuove, ragionamento su contenuti familiari, fisica intuitiva. Trattare la questione come “vince un sistema” è quasi sempre sbagliato.
L’evidenza moderna include studi di neuroimaging (Goel-Dolan 2003, NeuroImage 20:2314-2321) che separano substrati per content-laden reasoning (che attiva regioni temporali e parietali, compatibile con simulazione) e abstract formal reasoning (che attiva regioni prefrontali). Il dibattito non è risolto in senso forte — i due gruppi continuano a pubblicare evidenze a favore della propria tesi — ma la posizione “esiste un singolo meccanismo unico per il ragionamento” è ormai isolata.
Bounded fidelity sulla composizionalità. Un altro limite, meno discusso ma operativamente importante. I mental models umani gestiscono male composizioni profonde: ragionare su “l’effetto sul mercato che produrrebbe la decisione di un regolatore di rispondere alle previsioni di un’agenzia che valuta gli effetti delle decisioni dei regolatori” satura la capacità di simulazione mentale. Si fa fatica a tenere insieme più di 3-4 livelli di indirezione causale. Il limite si interseca con working memory (memoria-working): la mental simulation sta dentro working memory, e quindi è soggetta ai vincoli di capacità della working memory.
Equivalenze AI che falliscono. Quattro casi specifici da segnalare.
Primo: il mental model umano non è un world model AI nel senso implementativo. Le proprietà multi-modali, embodied, sviluppali del mental model umano non si riducono a un VAE+RNN. La somiglianza funzionale (entrambi sono modelli interni del mondo) è genuina; l’equivalenza è marketing.
Secondo: predizione video di alta fedeltà non è world model. Sora 2024 può produrre clip plausibili, ma non si conoscono evidenze pubblicate al 2026 che la rappresentazione interna sia usable per planning Dreamer-style. Pitchare Sora come “world simulator” è un overclaim.
Terzo: rappresentazione interna decodibile (Othello-GPT, Gurnee-Tegmark) non è world model esplicito. Il fatto che le activations contengano informazione recuperabile sullo stato del gioco è interessante e supporta l’idea che next-token prediction su task strutturati produca rappresentazioni utili. Non è equivalente a un’architettura in cui un modulo dedicato predice next state e un altro fa planning dentro.
Quarto: l’analogia “LLM ragiona via chain-of-thought = mental simulation” funziona a livello descrittivo (entrambi producono passi intermedi), ma vive su substrati diversi. Il mental simulation di Battaglia 2013 attiva un physics engine implicito; il chain-of-thought di un LLM produce token che condizionano i token successivi. Sono pattern simili in superficie, meccanismi diversi. La connessione produttiva sta in ponte-bounded-rationality-ttc, che la tratta come analogia funzionale di test-time compute.
Limiti epistemici dei probing-style results. Una parola di cautela su Othello-GPT e affini. Il fatto che un classificatore lineare possa decodificare lo stato della board dalle activations è un risultato sull’informazione presente, non necessariamente sull’informazione usata. Esiste un dibattito metodologico aperto (Belinkov 2022 review su probing; Hewitt-Liang 2019 sul control task per testare se il probing impara genuinamente o memorizza) sul cosa esattamente dimostri il successo di un probe. Il caso Othello-GPT è uno dei più puliti perché aggiunge l’intervento causale: modificare le activations cambia le predizioni in modo coerente. Ma non tutti i probing results in letteratura raggiungono questo standard. Trattare ogni “decoding successful” come prova di world model interno è prematuro.
Il problema della valutazione di world models generativi. Sora produce video, Veo produce video. Sono world simulators? La domanda è mal posta finché non si specifica il task. Per “produrre clip plausibili a 5-10 secondi”, sì. Per “fare planning su un task fisico complesso, come un robot che impili oggetti”, non c’è evidenza pubblicata che le rappresentazioni interne dei video models siano usable in modo Dreamer-style. La metrica corretta non è “il video sembra realistico”, è “se uso questa rappresentazione per planning, l’agente raggiunge il goal?”. Le valutazioni 2024-2026 hanno appena iniziato a porsi la domanda nel modo giusto; rispondere richiederà altri anni.
Una nota sulle equivalenze pericolose, in dettaglio
Sezione intitolata “Una nota sulle equivalenze pericolose, in dettaglio”Vale la pena fermarsi su un caso specifico, perché è quello in cui la confusione divulgativa è più frequente. Il claim “GPT-4 ha un world model” circola in due forme: una difendibile, una indifendibile.
Forma difendibile: “GPT-4 contiene rappresentazioni interne di certe strutture (spazio geografico, tempo storico, stati di giochi specifici) che possono essere decodificate da probing experiments e che il modello usa nelle sue predizioni.” Questo è documentato da Gurnee-Tegmark 2023 per spazio/tempo, da Li et al. 2022 per Othello, da molti altri lavori per altri domini. È un risultato empirico solido.
Forma indifendibile: “GPT-4 fa planning interno tipo Dreamer, simulando outcome alternativi prima di rispondere.” Non c’è evidenza pubblicata che la generazione di un LLM standard implementi un loop di planning con world model esplicito. La generazione token-by-token è un processo autoregressive, non un loop di pianificazione su un model separato. Le architetture o1-style di OpenAI 2024 introducono un tipo di “thinking” che potrebbe essere più vicino al planning, ma il dettaglio implementativo non è pubblico e l’evidenza esterna è ancora scarsa.
La distinzione fra le due forme non è pedanteria. Determina cosa ci si può aspettare dal sistema, dove fallirà, come progettare attorno. Un sistema con rappresentazioni internalizzate decodibili è ottimo per task che richiedono richiamo coerente di conoscenza strutturata (mappa geografica, scadenza temporale, stato di un gioco visto in training). Un sistema che fa planning espliciti tipo Dreamer è bravo a task che richiedono ragionamento prospettico su stati nuovi. Le due cose generano aspettative diverse.
Collegamenti
Sezione intitolata “Collegamenti”- memoria-episodica-semantica (67-memoria-episodica-semantica.md). La semantica fornisce il knowledge base specifico-di-dominio su cui si costruiscono i mental models. La constructive episodic simulation di Schacter-Addis 2007 è un caso speciale di mental simulation applicato all’asse temporale.
- percezione-priors (73-percezione-priors.md). Il predictive coding gerarchico di Rao-Ballard 1999 e Friston 2010 è il livello sub-personale del pattern “modello interno + predizione + errore + aggiornamento”. Mental models qui trattati sono il livello personale-deliberativo dello stesso schema.
- bounded-rationality-simon (76-bounded-rationality-simon.md). Mental simulation come euristica operativa sotto vincolo di calcolo. Satisficing come stopping rule per la simulazione mentale: si esplora finché un’opzione “abbastanza buona” non viene trovata, non si esauriscono le alternative.
- dual-process-kahneman (74-dual-process-kahneman.md). Mental simulation deliberata è prevalentemente System 2; fisica intuitiva e simulazioni rapide tipo Battaglia 2013 sono più System 1. La distinzione non è binaria, è di scala temporale e di accessibilità cosciente.
- euristiche-bias (78-euristiche-bias.md). La simulation heuristic di Kahneman-Tversky 1982 (si giudica la probabilità di un evento simulando alternative) e la availability heuristic (probabilità giudicata in base a facilità di recupero) sono casi di mental simulation come euristica.
- architetture-cognitive (62-architetture-cognitive.md). SOAR e ACT-R hanno mental models impliciti nelle production rules e nei chunk dichiarativi. Anderson ACT-R distingue declarative chunks (frammenti di conoscenza dichiarativa) da productions (regole condizione-azione); i mental models specifici-di-dominio vivono nel modulo dichiarativo.
- attenzione-psicologia (71-attenzione-psicologia.md). L’attenzione seleziona quali parti del world model interno aggiornare a un certo tempo, e quale livello di dettaglio rendere disponibile alla simulazione.
- theory-of-mind (in preparazione). Il mental model dell’altro come caso speciale di mental model: simulare gli stati mentali dell’interlocutore per anticiparne le azioni.
- monte-carlo-tree-search (in preparazione). Rollouts in MCTS come analogia funzionale della mental simulation: campionare alternative e statisticarne il risultato.
- world-models-ai (in preparazione). Trattazione tecnica di Dreamer, JEPA, MuZero come implementazioni del framework Craik in RL moderno.
Applicazioni pratiche
Sezione intitolata “Applicazioni pratiche”Tre applicazioni in cui il framework mental models si traduce in scelte progettuali concrete.
Design di interfacce e agenti. Norman 1988 è il vademecum. Un’interfaccia ben progettata espone una system image che invita la costruzione di uno user’s model accurato. Per agenti AI, la versione 2026 della stessa lezione: l’agente deve esporre cosa sta facendo (logging visibile, chain-of-thought leggibile, indicatori di tool calls in corso), perché lo user’s model dell’utente sull’agente determina la fiducia, l’uso corretto, la capacità di intervenire. Agenti opachi producono gli stessi mismatch delle Norman doors: l’utente costruisce un mental model dell’agente che non corrisponde al designer’s model dei creatori.
Education e debugging di concetti. McCloskey 1983 e Clement 1982 mostrano che mental models radicati resistono all’istruzione esplicita. La conseguenza didattica: cambiare un mental model richiede confronto diretto con casi che il modello errato non riesce a simulare correttamente, non lezioni frontali. La tradizione del Force Concept Inventory di Hestenes-Wells-Swackhamer (1992, Physics Teacher 30:141-158) e il programma di Eric Mazur a Harvard (peer instruction, 1997) sono basati su questo principio: si presenta uno scenario, il studente predice secondo il proprio mental model, si discute con peer, si confronta con il dato. Il cambiamento concettuale è guidato dal mental model, non dalla parola dell’insegnante.
Decision-making in sistemi con feedback. Sterman 2000 estende il programma 1989 a domini operativi: gestione di progetti software, politiche climatiche, politiche di salute pubblica. La regola operativa: in qualunque sistema con feedback loops e delays, non fidarsi del mental model. Affiancare simulazioni esterne, scenari quantitativi, sensitivity analysis sui parametri non osservabili. È la stessa lezione che porta il programma noisy-Newton di Battaglia 2013: l’intuizione fa girare un piccolo numero di rollout con rumore — utile, ma con varianza alta. Per decisioni costose serve aumentare il numero di rollout, e lo si fa fuori dalla testa.
Per andare oltre
Sezione intitolata “Per andare oltre”- Craik, K. (1943). The Nature of Explanation. Cambridge University Press. Cap. 5 “Hypothesis on the Nature of Thought” è il testo fondativo. Il libro è breve (circa 120 pagine) e leggibile. Riedizioni 1952 e 1967.
- Johnson-Laird, P. (2006). How We Reason. Oxford University Press. Versione divulgativa post-1983; più accessibile della monografia originale per chi vuole un’introduzione alla mental model theory of reasoning.
- Norman, D. (2013). The Design of Everyday Things, revised edition. Basic Books. Capitoli 1-2 per i three models e le affordances. Lettura canonica per chi lavora a interfacce.
- Sterman, J. (2000). Business Dynamics: Systems Thinking and Modeling for a Complex World. McGraw-Hill. Estensione book-length del programma 1989. Cap. 17 sul beer game con dati estesi e analisi cross-team.
- Ha, D., Schmidhuber, J. (2018). “World Models”. arXiv:1803.10122. Lettura tecnica con riferimenti espliciti a Craik. Versione interattiva al sito worldmodels.github.io con animazioni dei rollout immaginari.
- Battaglia, P., Hamrick, J., Tenenbaum, J. (2013). “Simulation as an engine of physical scene understanding”. PNAS 110:18327-18332. Lettura tecnica concisa per il programma noisy-Newton.
- Tenenbaum, J., Kemp, C., Griffiths, T., Goodman, N. (2011). “How to grow a mind”. Science 331:1279-1285. Per il framework bayesiano sulle intuitive theories.
- Forrester, J. (1971). “Counterintuitive Behavior of Social Systems”. Technology Review 73(3):52-68. Saggio breve, accessibile, sintesi del programma system dynamics e delle sue motivazioni.