TD-Gammon: la rete neurale che imparò il backgammon giocando contro sé stessa
Nel 1992, mentre l’industria dei sistemi esperti collassa e le reti neurali sono fuori moda, un singolo programma a IBM Research dimostra che la combinazione condannata — rete neurale più reinforcement learning — basta a battere i campioni umani di backgammon. La scena AI mainstream lo nota appena. Ventiquattro anni dopo, AlphaGo ne erediterà l’idea centrale.
Perché questo capitolo
Sezione intitolata “Perché questo capitolo”Tra il 1991 e il 1995 Gerald Tesauro (informatico statunitense, 1955-, ricercatore al Thomas J. Watson Research Center di IBM, formatosi in fisica teorica e poi migrato al machine learning) costruisce a Yorktown Heights una serie di programmi chiamati TD-Gammon. Sono reti neurali feedforward addestrate a giocare a backgammon attraverso milioni di partite contro sé stesse, senza alcun database di partite umane, senza euristiche scritte a mano, senza apertura preconfezionata. La regola di apprendimento è la temporal-difference learning formalizzata da Richard Sutton (informatico canadese, 1957-, oggi all’Università di Alberta) nel paper “Learning to Predict by the Methods of Temporal Differences”, pubblicato su Machine Learning vol. 3 nel 1988.
Questo capitolo conta per tre ragioni distinte. La prima è di filiazione: TD-Gammon è il primo programma in assoluto a dimostrare, su un dominio non banale, che la combinazione “rete neurale come approssimatore di funzione valore + reinforcement learning + self-play” può raggiungere e superare il livello dei campioni umani. È un risultato isolato per quasi due decenni; quando AlphaGo lo ricalca nel 2016 il filo storico è esplicito, citato in nota nei Methods del paper Nature di Silver e collaboratori. La seconda è metodologica: TD-Gammon esibisce, su un caso concreto, una proprietà poi diventata centrale nel dibattito moderno — un sistema puramente learning-based, senza alcuna conoscenza del dominio iniettata, può scoprire strategie controintuitive che gli esperti umani avevano scartato per pregiudizio. I master di backgammon studiarono le mosse di TD-Gammon e modificarono il loro repertorio di aperture. La terza è di storia delle scelte sbagliate: nonostante questo successo plateale, l’industria e l’accademia AI degli anni 90 non hanno investito su reinforcement learning combinato a reti neurali. Hanno investito su sistemi esperti, prima, e sul paradigma statistico (SVM, Bayesian nets, gradient boosting), poi. Una riflessione su perché questo accadde aiuta a riconoscere quando un risultato spettacolare non viene assorbito dalla comunità di riferimento, e perché.
C’è poi una ragione narrativa. La storia di TD-Gammon è una storia di laboratorio industriale ben funzionante: un singolo ricercatore, una macchina IBM RS/6000, una libreria di reti neurali scritta in C, qualche mese di tempo macchina, due paper e un risultato che invecchia poco. Il contrasto con la macchina pubblicitaria di Deep Blue cinque anni dopo è istruttivo: stesso ente di ricerca, stesso quartiere geografico, due approcci radicalmente diversi a “una macchina batte i campioni umani in un gioco”. Uno (Deep Blue, 1997) entra nella memoria pubblica. L’altro (TD-Gammon, 1992-1995) resta noto soprattutto nella comunità reinforcement learning. I motivi non sono tecnici.
Contesto
Sezione intitolata “Contesto”Il capitolo prende il filo da reti-neurali-80-90, che racconta la traversata silenziosa del filone neurale tra il 1982 di Hopfield e il 2012 di AlexNet. In quella traversata, TD-Gammon è uno dei pochi successi pratici e plateali del filone connessionista applicato a un dominio non banale, e arriva nel mezzo del periodo più difficile per le reti neurali: il secondo-inverno-ai sta erodendo gli ultimi finanziamenti sui sistemi esperti, la rinascita-statistica-90 sta spostando il consenso accademico verso metodi probabilistici, e la conferenza NIPS è ancora una nicchia.
Il backgammon come problema
Sezione intitolata “Il backgammon come problema”Il backgammon è un gioco di tavoliere per due giocatori, di origine antichissima (le sue regole moderne si stabilizzano nel mondo anglosassone tra Ottocento e Novecento, ma varianti esistono dall’antica Mesopotamia). Si gioca su 24 case (point) disposte in due quadranti per giocatore. Ogni giocatore ha 15 pedine (checker) che deve portare nella propria zona di casa e poi rimuovere dal tavoliere (bear off). A ogni turno, il giocatore tira due dadi e muove una o più pedine in base ai numeri usciti. La presenza dei dadi rende il gioco stocastico, e questo è il suo elemento più interessante per chi pensa in termini di intelligenza artificiale.
Ci sono tre proprietà del backgammon che lo rendono un testbed singolare. La prima: la branching factor (numero di mosse legali per turno) è alta — tipicamente 15-20, in alcune posizioni più di 100 — perché ogni tiro di dadi apre molte combinazioni di mosse legali. La seconda: la terminazione è garantita, salvo casi patologici (raddoppio infinito), e in tempo finito — una partita di backgammon dura circa 50-60 mosse medie. La terza, decisiva: la stocasticita dei dadi rende la search-tree minimax meno utile che negli scacchi. In una posizione di backgammon, la mossa “ottimale” dipende dalla distribuzione dei tiri futuri; un albero minimax di profondita 4-5 contiene un numero di nodi che esplode rapidamente perché ogni livello deve aggregare 21 possibili tiri di dadi distinti.
Per queste ragioni il backgammon era considerato, negli anni 80, un dominio dove la valutazione di posizione contava più della ricerca in profondita. Una buona valutazione statica (data una posizione, stimare la probabilita di vincere) basta, in linea di principio, per giocare bene anche con poca o nessuna ricerca in avanti. Questa proprietà è quella che rende il backgammon adatto a una rete neurale che impara a stimare il valore della posizione.
BKG e il precedente di Berliner
Sezione intitolata “BKG e il precedente di Berliner”Il principale predecessore di TD-Gammon è BKG, un programma scritto da Hans Berliner (informatico statunitense di origine tedesca, 1929-2017, professore alla Carnegie Mellon University, a sua volta ex campione mondiale di scacchi per corrispondenza nel 1968) negli anni 70. BKG era un sistema fondamentalmente simbolico: decine di regole euristiche scritte a mano per valutare la posizione (controllo del proprio quadrante interno, sicurezza delle pedine, race vs contact game), combinate con una piccola ricerca in avanti.
Nel luglio 1979 BKG batte in una sfida pubblica a Monte Carlo il campione del mondo in carica, l’italiano Luigi Villa (giocatore professionista, vincitore del campionato del mondo di backgammon nel 1979), per 7-1 in una serie di partite. È la prima volta che un programma batte un campione mondiale in qualsiasi gioco non banale. Il risultato fa notizia, ma Berliner stesso, in un report tecnico CMU pubblicato poco dopo, ammette che il suo programma era stato fortunato sui dadi e che, nel gioco complessivo, restava inferiore al meglio degli umani. La vittoria a Monte Carlo era stata reale ma non rappresentativa.
BKG resta per oltre dieci anni il riferimento di “stato dell’arte” in backgammon programmatico. Diversi successori (Mickey, Expert Backgammon nei primi anni 90) seguono lo stesso schema: knowledge engineering pesante, regole valutative scritte a mano da maestri umani, piccola ricerca in avanti. Tutti meglio di un giocatore amatoriale forte, nessuno al livello dei top-10 mondiali umani.
C’è una nota sul confronto BKG-TD-Gammon che merita di essere fissata. Berliner stesso, dopo aver letto i primi paper di Tesauro nei primi anni 90, riconobbe pubblicamente la superiorità dell’approccio learning-based. È un caso interessante di trasferimento intellettuale dentro lo stesso problema: l’autore del miglior sistema simbolico ammette che il sub-simbolico funziona meglio. La transizione fu meno traumatica di quanto sarebbe stata in altri domini, perché il backgammon offriva una metrica oggettiva (vince chi vince le partite) e perché Berliner era stesso un campione di backgammon, in grado di leggere le mosse di TD-Gammon e riconoscerne la qualità.
Tesauro e NeuroGammon: la prova generale
Sezione intitolata “Tesauro e NeuroGammon: la prova generale”Prima di TD-Gammon, Tesauro aveva costruito NeuroGammon, una rete neurale feedforward addestrata in modo supervisionato su un dataset di circa 3000 posizioni etichettate con la mossa “giusta” da un giocatore esperto (Tesauro stesso, secondo le sue dichiarazioni successive, e altri maestri amici). Il programma fu presentato alla prima edizione delle Computer Olympiad a Londra nel 1989 e vinse la categoria backgammon battendo gli altri programmi simbolici concorrenti.
Il successo di NeuroGammon convinse Tesauro che le reti neurali fossero un buon approssimatore di funzioni di valutazione, ma il programma era limitato in due modi importanti. Primo: la qualità massima di gioco era limitata dalla qualità del dataset di partenza — la rete poteva al massimo imitare il livello del maestro che aveva etichettato le posizioni, non superarlo. Secondo: produrre il dataset era costoso. Etichettare migliaia di posizioni di backgammon richiede ore di lavoro di un esperto per ogni centinaio di posizioni, e Tesauro aveva esaurito sia il budget di tempo proprio sia la pazienza dei colleghi.
L’idea di TD-Gammon nasce da queste due limitazioni. Se la rete potesse imparare giocando contro sé stessa, il limite della qualità umana sparirebbe (potenzialmente la rete potrebbe superare il maestro che l’ha addestrata) e il costo di produzione del dataset si annullerebbe (il dataset si genera automaticamente attraverso il self-play). Tesauro racconta nei colloqui successivi che l’idea gli venne leggendo il paper di Sutton 1988 e immaginando un loop in cui la rete generasse i propri dati di training partita dopo partita.
Lo stato delle reti neurali e di IBM Research nei primi anni 90
Sezione intitolata “Lo stato delle reti neurali e di IBM Research nei primi anni 90”Le reti neurali sono, nei primi anni 90, in disgrazia accademica. Il paper di Rumelhart-Hinton-Williams del 1986 ha rilanciato l’interesse, NETtalk (Sejnowski-Rosenberg 1987) ha impressionato, ma la comunità ML mainstream sta migrando verso metodi statistici con migliori garanzie teoriche. Vladimir Vapnik (matematico russo-americano, 1936-, allora a Bell Labs) pubblicherà sulle SVM nel 1995, Leo Breiman (statistico americano, 1928-2005, Berkeley) sui random forest nel 2001, ma già all’inizio degli anni 90 i Bayesian networks di Judea Pearl (informatico israelo-americano, 1936-, UCLA) del 1988, gli HMM per speech recognition e i decision tree dominano la scena pratica. Il secondo-inverno-ai si sovrappone, almeno in parte, al periodo di TD-Gammon: il mercato delle Lisp machines crolla nel 1987, i programmi di sistemi esperti corporate vengono ridimensionati, i finanziamenti DARPA si riducono. La conferenza NIPS (Neural Information Processing Systems) ha circa 700 partecipanti l’anno; ICML (International Conference on Machine Learning) sta crescendo ma è ancora dominata da paper su decision tree, induzione di regole e apprendimento simbolico.
Su questo sfondo, IBM Research è una delle poche istituzioni in cui un ricercatore ha relativa libertà di esplorare temi controversi senza dover giustificare ogni mese cosa stia producendo. Il Thomas J. Watson Research Center a Yorktown Heights (New York) ha tradizionalmente ospitato fisici teorici, matematici puri, computer scientist su agende a lungo termine. È lo stesso laboratorio dove Benoit Mandelbrot aveva sviluppato la geometria frattale negli anni 60-70 e dove negli anni 80 si lavora su crittografia, complessità computazionale, fisica statistica. La cultura interna privilegia ricerca curiosity-driven con orizzonti temporali pluriennali, una rarita nell’industria degli anni 90.
Tesauro entra a IBM nel 1985, dopo un dottorato in fisica teorica a Princeton e un postdoc in teoria del caos al Center for Complex Systems Research di Urbana-Champaign. La sua transizione al machine learning è graduale: i primi lavori al Watson Center sono su sistemi dinamici e fisica statistica delle reti neurali, in continuita con il background di fisica teorica. L’incontro con il backgammon avviene in modo quasi accidentale: Tesauro è un appassionato di giochi (in particolare backgammon e bridge), e gli sembra naturale provare le tecniche di reti neurali su un dominio con cui ha familiarita personale.
L’idea di TD-Gammon nasce da una domanda che Tesauro si pone leggendo Sutton 1988: e se, invece di addestrare la rete su dati umani, la facessi giocare contro sé stessa e la facessi imparare dagli esiti delle proprie partite? La regola di update sarebbe quella della temporal difference: la stima della posizione corrente si aggiorna verso la stima della posizione successiva, propagando alla fine il segnale di vittoria/sconfitta. L’esperimento, scritto in C su una workstation IBM RS/6000, gira per qualche settimana e produce risultati incoraggianti già nei primi 100.000 episodi. Tesauro lascia girare il sistema più a lungo e vede la performance continuare a salire. Il paper Machine Learning del 1992 documenta questi primi mesi.
Sutton 1988 e la genealogia di TD-learning
Sezione intitolata “Sutton 1988 e la genealogia di TD-learning”Vale la pena ancorare il paper di Sutton 1988 nel suo contesto. Sutton stava completando il dottorato all’Università del Massachusetts Amherst sotto la supervisione di Andrew Barto. La sua tesi del 1984, “Temporal Credit Assignment in Reinforcement Learning”, aveva già introdotto le idee centrali di TD; il paper Machine Learning del 1988 le formalizza in forma matura, dimostra alcune proprietà di convergenza e fornisce esperimenti su problemi giocattolo (random walk markoviano).
L’idea di TD non nasceva dal nulla. Era ispirata in parte dal lavoro precedente di Samuel sul learning a dama, in parte dal lavoro di Klopf sull’apprendimento adattivo eterostatico (anni 70-80), in parte dalla letteratura di Sutton-Barto stessi sull’actor-critic (1983), una architettura in cui un “critico” impara a stimare il valore degli stati e un “attore” usa quella stima per migliorare la policy. La pubblicazione del 1988 cristallizza l’idea separando TD-learning come tecnica autonoma di stima della funzione valore, indipendente da uno specifico schema di policy improvement.
Negli anni successivi, il framework si arricchisce: Q-learning di Watkins (1989) estende TD a stime di azione-valore anziche solo state-valore ; SARSA (Sutton 1996) aggiunge una variante on-policy; eligibility trace di Watkins (1989) e eligibility trace di Peng-Williams (1996) raffinano la propagazione del segnale. TD-Gammon usa essenzialmente il TD() originale di Sutton 1988, con le modifiche minime necessarie per gestire l’output sigmoidale e l’addestramento a-fine-partita.
La piccola comunità reinforcement learning del periodo
Sezione intitolata “La piccola comunità reinforcement learning del periodo”Vale la pena collocare TD-Gammon nella mappa della comunità RL dei primi anni 90, perché aiuta a capire perché il risultato non scateno la corsa che retrospettivamente ci aspetteremmo. La comunità era piccola e geograficamente sparsa. Richard Sutton lavorava al GTE Labs in Massachusetts dopo una carriera che era passata per Stanford, l’Università del Massachusetts ad Amherst (con Andrew Barto come supervisor di dottorato), e che lo avrebbe portato negli anni 2000 all’AT&T Labs e poi all’Università di Alberta. Andrew Barto (informatico statunitense, 1948-, professore ad Amherst) era il riferimento accademico principale per RL su ambienti markoviani. Chris Watkins (informatico britannico) aveva pubblicato il paper su Q-learning nel 1989 (tesi PhD a Cambridge). Leslie Kaelbling (informatica statunitense, allora a Brown, poi al MIT) aveva pubblicato lavori su POMDP. Michael Littman stava lavorando sul suo dottorato a Brown e poi a Duke su markov games e RL multi-agent.
Questa comunità aveva una conferenza dedicata embrionalmente — un workshop annuale che sarebbe diventato la base di NIPS Workshop on Reinforcement Learning — e una manciata di paper su Machine Learning Journal. Il libro di Sutton-Barto, Reinforcement Learning: An Introduction, sarebbe uscito solo nel 1998. Prima di allora, chi voleva imparare RL doveva mettere insieme paper sparsi, technical report, e capitoli di libri di sistemi adattivi degli anni 80.
Quando TD-Gammon esce, viene riconosciuto come uno dei pochi successi pratici dell’approccio, ma la comunità non ha la massa critica per costruirci sopra programmi di ricerca paralleli. Negli anni 90 il numero di gruppi accademici che lavorano seriamente su RL applicato si conta sulle dita di una mano: Sutton-Barto ad Amherst, Watkins-Dayan in Inghilterra, qualche gruppo a Stanford con Andrew Ng dopo la fine degli anni 90, Schmidhuber a IDSIA su recurrent reinforcement learning. Industria: nessun investimento sistematico fino all’acquisto di DeepMind da parte di Google nel 2014.
L’intuizione
Sezione intitolata “L’intuizione”Angolo algoritmico: imparare dai propri errori a posteriori
Sezione intitolata “Angolo algoritmico: imparare dai propri errori a posteriori”Il problema centrale del reinforcement learning è il credit assignment: data una sequenza di decisioni che porta a un esito (vittoria o sconfitta), come distribuire il “merito” o la “colpa” sulle singole decisioni? Una mossa fatta dieci turni prima della vittoria è stata buona o cattiva? Senza un metodo per attribuire credito, la rete non sa cosa rinforzare.
L’idea della temporal difference è elegante. Anziche aspettare la fine della partita per aggiornare le stime, si aggiorna ad ogni mossa la stima della posizione corrente verso la stima della posizione successiva. Se la mia rete crede che la posizione attuale valga 0.55 (cioe il 55% di probabilita di vincere) e la posizione successiva valga 0.62, allora la stima attuale era pessimista: la sposto un poco verso 0.62. Quando la partita termina con una vittoria, la stima dell’ultima posizione è sicuramente 1.0; quel segnale si propaga all’indietro, mossa dopo mossa, attraverso la catena di update.
Detto in modo intuitivo: la rete impara dai propri errori a posteriori, ma non aspetta la fine della partita per cominciare a imparare. Ogni transizione è già un frammento di insegnamento. Questa è la differenza più importante con i metodi di Monte Carlo del reinforcement learning, che invece aggiornano solo a fine episodio usando il return totale. TD aggiorna ad ogni passo, in modo incrementale, e questo rende l’apprendimento molto più efficiente in termini di numero di partite richieste per convergere.
C’è una dimensione ancora più sottile. La stima della posizione successiva è essa stessa una stima della rete, non un valore vero. Quindi la rete sta imparando a predire un bersaglio che lei stessa produce, un bersaglio mobile (bootstrapping, in gergo). Sembra una procedura instabile, e in alcuni casi lo è — la combinazione “function approximation + bootstrapping + off-policy” è nota come deadly triad in letteratura RL e può divergere. TD-Gammon evita la divergenza in pratica per ragioni che la teoria post-1992 ha chiarito solo in parte: il backgammon ha una struttura particolarmente benigna (terminazione garantita, esplorazione naturale via dadi, valore atteso ben definito), e l’architettura di rete che Tesauro sceglie è abbastanza piccola da convergere senza oscillazioni catastrofiche.
Angolo pratico: pure self-play in un dominio con feedback affidabile
Sezione intitolata “Angolo pratico: pure self-play in un dominio con feedback affidabile”L’idea operativa di TD-Gammon è radicale per l’epoca: nessuna conoscenza di backgammon viene programmata nella rete. Solo le regole del gioco (quali mosse sono legali data una posizione e un tiro di dadi) sono fornite dall’esterno. Tutto il resto — quale posizione è buona, quale apertura è forte, quale strategia adottare in fase di race — la rete deve scoprirlo da sola attraverso self-play.
Questo è un atto di fede teorico. Negli anni 80-90 il consenso era che, per ottenere un programma forte, dovessi iniettare conoscenza esperta nel sistema. BKG faceva esattamente questo. Le scuole di knowledge engineering dei sistemi esperti facevano questo (vedi sistemi-esperti). TD-Gammon fa il contrario: assume che il sistema di apprendimento sia in grado di estrarre tutta la conoscenza necessaria dall’esperienza, a patto che il segnale di feedback (vittoria/sconfitta) sia affidabile e che ci sia abbastanza esperienza.
La lezione, retrospettivamente, è duplice. Primo: in un dominio con feedback affidabile, pure-learning può competere con e superare expert systems con knowledge engineering. Secondo: la condizione “feedback affidabile” è restrittiva. Vince/perde è un segnale binario non ambiguo. La performance al sintomo “il paziente sta meglio” non lo è. La qualità di un saggio scolastico non lo è. La conformita di un’azione agentica all’intento di un utente non lo è. Quando il segnale è affidabile, l’approccio TD-Gammon scala. Quando non lo è, il problema è altrove.
Una nota sull’esplorazione. In molti algoritmi RL serve un meccanismo esplicito di esplorazione (epsilon-greedy, Boltzmann sampling, intrinsic motivation) per evitare che la policy si fissi troppo presto su comportamenti subottimi. TD-Gammon non ne ha bisogno: i dadi forniscono esplorazione naturale. A ogni turno la rete è obbligata a considerare mosse che dipendono dal tiro casuale, e diversi tiri possono portare a regioni diverse dello spazio di stato. Questa è una proprietà benigna del backgammon che non si trasferisce a giochi deterministici come gli scacchi o il Go.
C’è un terzo angolo, più cognitivo, che vale la pena menzionare. La temporal difference è in qualche modo analoga al modo in cui sembra funzionare l’apprendimento dopaminergico nel cervello dei mammiferi. Studi neuroscientifici a partire dagli anni 90 (in particolare Wolfram Schultz e collaboratori, Nature 1997, “A neural substrate of prediction and reward”) hanno mostrato che i neuroni dopaminergici nel sistema mesolimbico codificano un segnale che assomiglia all’errore di temporal difference: scaricano in proporzione alla differenza tra ricompensa attesa e ricompensa ricevuta. Questa è un’analogia, non una filiazione: nessuno sostiene che TD-learning algoritmico fu progettato pensando alla biologia dopaminergica, e nessuno sostiene che il cervello implementi esattamente l’algoritmo di Sutton 1988. Ma la convergenza tra il modello matematico ottimale per RL e il pattern osservato in biologia è suggestiva, ed è uno dei motivi per cui RL è studiato anche in neuroscienze computazionali. Per TD-Gammon questa connessione non è essenziale, ma fornisce una cornice intellettuale aggiuntiva per chi vede l’AI in dialogo con le scienze cognitive.
La meccanica
Sezione intitolata “La meccanica”Backgammon in breve: regole minime per chi non gioca
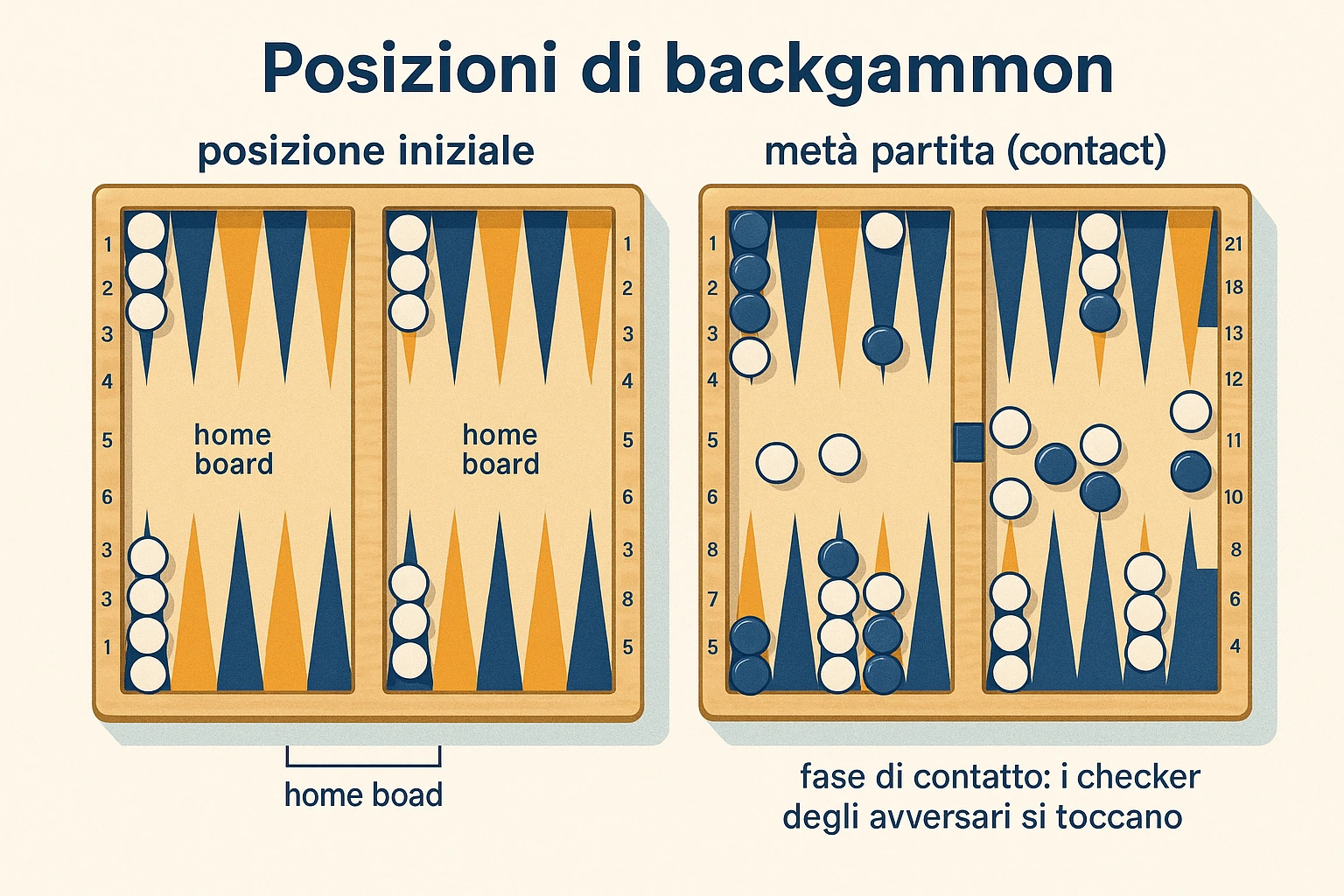
Sezione intitolata “Backgammon in breve: regole minime per chi non gioca”Per chi non ha mai giocato a backgammon, vale la pena fissare le regole minime utili a leggere il resto del capitolo. Il tavoliere ha 24 case (point) numerate, 12 per giocatore. Ogni giocatore parte con una distribuzione iniziale fissa di 15 pedine sparse su quattro case (2 pedine sul punto 24, 5 sul punto 13, 3 sul punto 8, 5 sul punto 6, in una notazione standard). L’obiettivo è muovere tutte le proprie pedine nel proprio quadrante interno (i punti 1-6) e poi rimuoverle dal tavoliere (bear off).
A ogni turno il giocatore tira due dadi a sei facce e muove pedine in base ai numeri usciti. Se i dadi mostrano 5 e 3, può muovere una pedina di 5 case e un’altra di 3 case, oppure la stessa pedina di 5 e poi di 3 (se le case intermedie sono accessibili). Se esce un doppio (es. 4-4), può fare quattro mosse da 4 case ciascuna. Una pedina può entrare in una casa vuota, in una propria casa (con altre pedine dello stesso colore, formando un punto sicuro), o in una casa avversaria con una sola pedina (catturandola e mandandola sulla bar al centro del tavoliere). Una casa con due o più pedine avversarie è bloccata.
Una pedina catturata deve rientrare dalla bar nel quadrante interno avversario prima che il giocatore possa fare altre mosse. Se non riesce a rientrare (tutte le case del quadrante avversario sono bloccate), perde il turno. Bloccare il proprio quadrante interno (i 6 punti tutti coperti) è una strategia potente: l’avversario non può rientrare, e ogni turno perso peggiora la sua posizione.
Le tipologie di vittoria sono tre: vittoria semplice (1 punto), gammon (2 punti, l’avversario non ha rimosso nessuna pedina), backgammon (3 punti, l’avversario non ha rimosso nessuna pedina e ha pedine sulla bar o nel proprio quadrante avversario). Il match play ufficiale si gioca a un numero predefinito di punti.
Questa è la base. Il doubling cube (un dado a sei facce con i numeri 2, 4, 8, 16, 32, 64 usato per raddoppiare la posta in palio durante la partita) aggiunge una dimensione strategica importante che TD-Gammon nelle prime versioni ignora; le versioni successive lo gestiscono con un modulo separato addestrato su rollout statistici.
TD-learning: la regola di update
Sezione intitolata “TD-learning: la regola di update”Sutton 1988 introduce la famiglia di algoritmi TD(lambda), parametrizzata da un numero che controlla quanto in profondita nel passato si propaghi il segnale di update. Per ogni transizione da uno stato a uno stato con ricompensa istantanea e fattore di sconto , l’errore di temporal difference è:
dove è la stima del valore dello stato prodotta dalla rete. In parole povere, misura quanto la stima di era sbagliata, vista alla luce della stima aggiornata di e della ricompensa appena ricevuta. Se la stima era pessimista, se era ottimista.
Per il backgammon, la ricompensa istantanea è zero ad ogni mossa intermedia e vale (vittoria del giocatore corrente) o (sconfitta) a fine partita. Il fattore di sconto è tipicamente fissato a 1 (nessuno sconto, perché le partite sono finite). Quindi per tutte le mosse intermedie e per la mossa finale.
L’update dei pesi della rete usa il gradiente di rispetto ai parametri della rete:
dove è il learning rate ed è la eligibility trace, una sorta di “memoria di responsabilita” per gli stati visitati nel recente passato. La trace è aggiornata ad ogni passo come:
Quando , la trace è solo il gradiente corrente: si aggiorna solo la stima dello stato corrente. È equivalente a TD(0), il caso più semplice. Quando , la trace accumula tutti i gradienti passati senza decadimento: l’algoritmo diventa equivalente a un metodo Monte Carlo che propaga il segnale di fine partita su tutta la sequenza. I valori intermedi realizzano un trade-off bias-varianza: alto riduce il bias (i target sono più vicini al return reale) ma aumenta la varianza (i target dipendono da molti passi rumorosi); basso fa il contrario. TD-Gammon usa tipicamente nelle prime versioni, scendendo verso nelle versioni successive man mano che la rete diventa più accurata.
Vale la pena fissare l’intuizione della eligibility trace con un’immagine. Pensa a una catena di stati visitati . Ogni stato lascia una “traccia” di responsabilita per gli update futuri, che decade nel tempo. Quando arriva un errore di TD al passo , quell’errore si distribuisce su tutti gli stati ancora “responsabili”, in proporzione alla loro traccia. Gli stati più recenti hanno traccia alta e ricevono il grosso dell’update; gli stati più remoti hanno traccia decaduta e ricevono solo una piccola correzione. Il parametro controlla la velocità del decadimento. È come una “coda di responsabilita” che la rete trascina dietro di sé mentre gioca.
La trace si resetta a fine partita: i pesi tornano “puliti” prima della partita successiva (la trace è azzerata, non i pesi della rete). Questo è importante per evitare che le decisioni di una partita propaghino update a stati di partite diverse, che sarebbero correlazioni spurie.
L’architettura di TD-Gammon
Sezione intitolata “L’architettura di TD-Gammon”La rete è una rete neurale feedforward con un singolo hidden layer nelle prime versioni, due hidden layer in quelle successive. L’input è una rappresentazione binaria della posizione del backgammon, l’output è una singola unità sigmoidale che stima la probabilita di vittoria del giocatore al tratto.
L’input encoding è un punto importante. Tesauro sceglie una codifica densa con circa 198 unità binarie per ciascuna posizione. Per ognuna delle 24 case (point) del tavoliere, alloca quattro unità binarie per le pedine bianche e quattro per le nere, codificando in modo “termometro” il numero di pedine: la prima unità è accesa se ci sono ≥1 pedine, la seconda se ≥2, la terza se ≥3, la quarta porta un valore proporzionale per ≥4. Questa codifica è non distribuita: non comprime la posizione, la espande in una rappresentazione che la rete può usare facilmente per apprendere feature di alto livello (blot esposti, blocchi, prime). Aggiunge poi unità per le pedine sulla bar (catturate), per le pedine borne off (rimosse dal gioco), e per il giocatore al tratto. Nelle versioni più avanzate, Tesauro inserisce alcune feature ingegnerizzate come indicatori di race vs contact game: questa è una concessione esplicita al knowledge engineering, motivata dall’osservazione che la rete fatica a distinguere autonomamente le due fasi.
L’hidden layer ha 40 unità in TD-Gammon 0.0 (1991), 80 unità in TD-Gammon 1.0 (1992), 160 unità in TD-Gammon 2.0 (1993), simili o doppi nelle versioni successive. Le attivazioni hidden sono sigmoidali. L’output è una singola unità sigmoidale che produce un valore in , interpretato come probabilita stimata di vittoria del giocatore al tratto. (Nelle versioni successive l’output diventa multi-dimensionale per stimare separatamente vittoria semplice, gammon e backgammon, le tre tipologie di vittoria che danno punteggi diversi nel match play.)
La taglia totale della rete TD-Gammon 2.1 è di circa pesi, più i bias. Una taglia ridicola per gli standard del 2026 (un transformer moderno ha miliardi di parametri) ma proporzionata al compute disponibile nei primi anni 90 e al volume di dati prodotti dal self-play. È una rete che gira comodamente su una workstation, addestramento incluso, in qualche giorno o settimana di tempo macchina. Nessuna GPU, nessun cluster, nessun parallelismo: una sola CPU che alterna forward pass, backward pass, update dei pesi.
Una scelta architetturale che vale la pena commentare: Tesauro non usa convoluzioni per il backgammon. Negli anni 90 le CNN erano già note (LeCun ne aveva pubblicato versioni dal 1989) ma applicabili principalmente a immagini. Per una posizione di backgammon, il tavoliere ha una struttura pseudo-lineare (24 case in sequenza, con la bar nel mezzo) che non beneficia in modo evidente di filtri convoluzionali; una rete fully-connected è sufficiente. Le posizioni del Go (griglia 19x19) sono diverse: AlphaGo nel 2016 userà CNN proprio perché la struttura spaziale del Go le rende efficaci.
Self-play training
Sezione intitolata “Self-play training”L’addestramento procede così. La rete gioca contro sé stessa una partita. Ad ogni turno, calcola il valore di tutte le posizioni risultanti dalle mosse legali date dai dadi tirati, sceglie la mossa che massimizza il valore (assumendo, per simmetria, che l’avversario faccia altrettanto sul proprio turno), aggiorna i pesi via TD() sulla transizione appena fatta. La partita finisce quando uno dei due giocatori ha rimosso tutte le sue pedine. Il segnale di vittoria/sconfitta entra nell’ultima mossa e si propaga all’indietro attraverso le eligibility trace.
I numeri sono significativi. TD-Gammon 0.0 viene addestrato su circa 200.000 partite di self-play. TD-Gammon 1.0 (quello pubblicato sul paper Machine Learning del 1992) su circa 300.000 partite. TD-Gammon 2.0 su 800.000. TD-Gammon 2.1 su 1.5 milioni. Le versioni successive (3.0 e seguenti) arrivano a 6 milioni di partite di self-play. Tradotto: l’esperienza accumulata da TD-Gammon 3.0 corrisponde a quanto un campione umano giocherebbe in centinaia di anni di pratica continua.
Una dinamica osservata da Tesauro durante l’addestramento è la presenza di ondate di scoperte: la rete migliora rapidamente nelle prime decine di migliaia di partite (impara le basi: portare le pedine verso casa, evitare blot esposti), poi entra in una fase di plateau apparente, poi salta improvvisamente di nuovo a un livello superiore. I salti corrispondono spesso a strategie nuove che la rete “scopre” attraverso self-play e che, una volta integrate nella sua valutazione, si propagano ad altre situazioni. Tesauro descrive questo nel paper del 1995 sulla Communications of the ACM: dopo circa 800.000 partite, la rete inizia a privilegiare il back game (lasciare due o più pedine nel quadrante interno avversario per sperare in colpi di fortuna sui dadi futuri), una strategia che gli umani consideravano pericolosa e che TD-Gammon usa con maggior frequenza e successo dei giocatori umani.
Un dettaglio implementativo importante: per evitare loop o stalli durante il self-play, Tesauro non implementa esplicitamente epsilon-greedy o altri schemi di esplorazione forzata. La stocasticita dei dadi è sufficiente per garantire varietà nelle posizioni visitate. Una conseguenza interessante è che, nelle prime decine di migliaia di partite, la rete è ancora così imprecisa che le sue mosse “ottimali” sono di fatto quasi casuali, e il sistema esplora ampiamente lo spazio di stato. Solo gradualmente la policy diventa coerente, ma a quel punto il segnale di TD ha già ridotto sensibilmente l’errore sulle stime di valore. È un esempio di come un dominio benigno possa sostituire meccanismi di esplorazione esplicita con esplorazione naturale.
Un altro dettaglio: la rete gioca contro una copia di sé stessa ad ogni partita, ma è la stessa rete in fase di update — non c’è separazione tra rete corrente e rete target come in DQN. Questa scelta semplifica l’implementazione e funziona bene per il backgammon, dove la stocasticita dei dadi smussa le instabilita. In domini deterministici come il Go o gli scacchi, la stessa scelta può portare a oscillazioni e divergenze; AlphaGo e DQN introducono separazioni esplicite (target network, replay buffer) per mitigare questi effetti.
Evoluzione 0.0 -> 1.0 -> 2.0 -> 3.0
Sezione intitolata “Evoluzione 0.0 -> 1.0 -> 2.0 -> 3.0”La sequenza delle versioni illustra il progresso. TD-Gammon 0.0 (1991): un singolo hidden layer con 40 unità, ~200.000 partite di training, nessuna feature ingegnerizzata, nessuna ricerca in avanti. Performance approssimativamente al livello di un giocatore amatoriale forte, paragonabile ad Andy Grossman (ex-campione nazionale americano). Vista come una prova di concetto.
TD-Gammon 1.0 (1992, descritto nel paper Machine Learning vol. 8, pp. 257-277): hidden layer ampliato, training più lungo, qualche aggiustamento di iperparametri. Performance al livello di un giocatore esperto medio del circuito mondiale.
TD-Gammon 2.0 / 2.1 (1993): due hidden layer, ~80-160 unità per layer, ~1.5 milioni di partite di self-play, feature ingegnerizzate per race vs contact game, ricerca in avanti a 2 ply (cioe valutazione di tutte le posizioni risultanti dalla propria mossa e dalla risposta avversaria attesa, su tutti i possibili tiri di dadi). Performance al livello di Bill Robertie (giocatore professionista americano, ex campione mondiale negli anni 80, autore di libri di teoria del backgammon poi diventati riferimento standard).
TD-Gammon 3.0 (1995): rete più grande, ~6 milioni di partite, ricerca a 2-3 ply. Performance superiore a tutti i giocatori umani conosciuti, secondo le valutazioni dei master che lo testarono e secondo il sistema di rating Snowie/FIBS. A questo punto la valutazione era confermata da molteplici sessioni di test contro Bill Robertie, Kit Woolsey (giocatore professionista americano, autore di “How to Play Tournament Backgammon” del 1993), Malcolm Davis e altri top player del periodo. Tutti riportavano che TD-Gammon 3.0 giocava in modo “diverso ma non sbagliato” e che, nei match, spesso vinceva o pareggiava con loro.
Una nota numerica: i 6 milioni di partite di self-play di TD-Gammon 3.0 corrispondono a circa 300 milioni di posizioni distinte visitate, considerando una media di 50 mosse per partita. La rete vede ogni posizione tipicamente una sola volta o poche volte; non c’è memorizzazione, c’è generalizzazione. Questa proprietà — generalizzazione attraverso function approximation, su un volume enorme di esperienza — è ricca di conseguenze: la rete impara a valutare posizioni che non ha mai visto esattamente, perché le rappresenta nello spazio di feature interno e interpola.

Le aperture nuove: scoperte controintuitive
Sezione intitolata “Le aperture nuove: scoperte controintuitive”L’aspetto più suggestivo del successo di TD-Gammon è culturale. Attorno al 1993-1995, alcuni master di backgammon iniziano a studiare le mosse del programma. Notano che TD-Gammon, in alcune posizioni di apertura, preferisce mosse che la teoria umana aveva scartato.
L’esempio canonico citato nel paper CACM del 1995 e in successive analisi è la risposta al tiro 5-1 all’apertura. Per decenni, la mossa “standard” insegnata nei manuali era 13/8 24/23 (spostare una pedina dalla casa 13 alla casa 8, e una dalla casa 24 alla casa 23), una mossa cauta che mira a iniziare un blocco e a posizionare una pedina sicura nel quadrante avversario. TD-Gammon preferiva sistematicamente 13/8 24/23 in alcune varianti e 24/23 13/8 in altre, con leggere differenze rispetto alla teoria classica, e in particolare sceglieva con maggior frequenza l’inizio di un back game o di un holding game in posizioni dove gli umani avrebbero giocato in modo più “aperto”. Analisi successive con software più potente confermarono che le scelte di TD-Gammon erano spesso (non sempre) marginalmente migliori di quelle umane.
Un altro esempio frequentemente citato è la risposta al tiro 2-1 all’apertura. La teoria umana classica raccomandava la slot del 5-point: muovere 13/11 e 24/23, oppure 13/11 6/5, lasciando un blot sul punto 5 (proprio quadrante interno) sperando di costruirlo nel turno successivo. TD-Gammon, invece, preferiva spesso una mossa più conservativa che evitava la slot. Analisi successive con rollout statistici di milioni di posizioni mostrarono che le due alternative erano molto vicine in equity, con la mossa di TD-Gammon leggermente preferibile in match play (dove la varianza è importante) e la slot leggermente preferibile in money play (dove conta solo il valore atteso). Una sottigliezza che la teoria umana, costruita su intuizione e non su simulazione, non aveva colto.
Un terzo caso: la gestione del 5-4 split in apertura (l’avversario ha appena giocato 24/20 13/8 dopo un tiro 5-4 iniziale). La teoria umana raccomandava di rispondere aggressivamente attaccando il blot esposto sul punto 20. TD-Gammon a volte preferiva una risposta più posizionale, costruendo punti propri anziche attaccare. Anche qui, la simulazione di milioni di posizioni post-1995 confermo che la scelta della rete era difendibile in molte varianti, anche se non sempre superiore.
L’effetto culturale fu reale. Bill Robertie e altri teorici del gioco rividero alcuni capitoli dei loro libri. Nuove edizioni di manuali (“Modern Backgammon” di Robertie, edizioni dal 2002 in poi) integrano analisi computer-assistita e citano TD-Gammon come catalizzatore del cambiamento. Nel mondo del backgammon competitivo, il pre-1995 e il post-1995 si distinguono per un livello di rigore analitico molto diverso: prima si discuteva di principi euristici, dopo si fanno simulazioni di milioni di rollout. La transizione fu accelerata da TD-Gammon e dai suoi successori commerciali (Jellyfish, poi Snowie, poi GNU Backgammon) che incorporavano architetture simili.
Vale la pena fissare una distinzione importante. TD-Gammon non aveva accesso a un database di partite umane, e quindi non poteva “imitare” gli umani. Le sue scoperte non erano ricalcate da repertori esistenti: emergevano dalla pura interazione della rete con sé stessa, a partire da pesi inizializzati casualmente. Quando un essere umano studia il gioco, è inevitabilmente influenzato dalla teoria precedente, dai propri maestri, dalle convenzioni del circuito. La rete partiva da zero. Questo è il senso preciso in cui TD-Gammon “scopri” cose nuove: trovo strategie che la teoria umana, accumulata in secoli, aveva trascurato perché guardava le posizioni con lente differenti.
Una nota di fairness storica: non tutte le scoperte di TD-Gammon erano genuinamente “nuove” in senso assoluto. Alcune erano state intuite da pochi giocatori molto avanzati ma rifiutate dalla teoria mainstream perché difficili da giustificare con argomenti euristici. TD-Gammon aveva il vantaggio di non dover giustificare le sue scelte: bastava che funzionassero meglio in pratica. Una volta dimostrato che funzionavano, gli umani potevano ricostruirne a posteriori la logica. Questo pattern — la rete trova qualcosa che funziona, gli esperti umani lo razionalizzano dopo — diventerebbe centrale nel periodo AlphaGo e seguenti.
Il dettaglio del bootstrapping: perché funziona qui
Sezione intitolata “Il dettaglio del bootstrapping: perché funziona qui”Vale la pena entrare nel dettaglio di perché il bootstrapping di TD() non diverge in TD-Gammon, mentre in altri contesti può divergere catastroficamente. La teoria della deadly triad in RL identifica tre ingredienti che, combinati, possono causare divergenza: function approximation (la rete), bootstrapping (i target di TD sono stime), off-policy learning (la policy di comportamento differisce dalla policy che si sta valutando). Quando tutti e tre sono presenti, esistono controesempi noti in cui i pesi divergono verso infinito.
TD-Gammon ha i primi due ingredienti (rete neurale come approssimatore, target di TD basati su stime della rete stessa) ma non il terzo: la policy di comportamento è la stessa che si sta valutando (on-policy). Questo, combinato con altre proprietà benigne (stocasticita dei dadi che smussa le instabilita, terminazione garantita che fornisce un segnale “ground truth” a fine partita, dimensione della rete sufficientemente piccola), evita la divergenza in pratica.
Una conferma sperimentale viene da varianti di TD-Gammon che hanno provato a usare schemi off-policy o reti molto più grandi: in alcuni casi convergono lentamente, in altri oscillano. La stabilità dell’algoritmo originale è in parte fortuna dovuta alle scelte di Tesauro, in parte una proprietà del dominio. Algoritmi RL moderni (DQN, double DQN, dueling networks, distributional RL) hanno introdotto trucchi specifici (target network, experience replay, distribuzioni di valore anziche stime puntuali) per stabilizzare l’apprendimento in contesti meno benigni.
Tornando al lettore non specialista: l’osservazione utile è che TD-Gammon “funziona” perché è la combinazione giusta di algoritmo e dominio. Non è una formula magica replicabile ovunque. Quando il dominio coopera (feedback affidabile, simulatore veloce, struttura stocastica benigna), l’approccio scala. Quando non coopera, servono adattamenti significativi.
Note su Tesauro e la sua traiettoria post-TD-Gammon
Sezione intitolata “Note su Tesauro e la sua traiettoria post-TD-Gammon”Tesauro continua a lavorare a IBM Research per oltre tre decenni. Dopo TD-Gammon, le sue principali aree sono:
- Reinforcement learning per resource allocation (anni 2000): allocazione di server e risorse computazionali in data center, in collaborazione con il gruppo IBM Autonomic Computing.
- Multi-agent learning (fine anni 90 e 2000): estensioni di TD-learning a contesti con più agenti che imparano simultaneamente, in particolare per giochi a somma generale (non solo zero-sum).
- Wagering strategy in IBM Watson (2009-2011): nel team che costruisce Watson per Jeopardy!, Tesauro contribuisce ai componenti decisionali del sistema, incluso il problema di quanto scommettere nelle Daily Doubles e nel Final Jeopardy. È una applicazione di RL e teoria delle decisioni che ricicla parte dell’expertise sviluppata su TD-Gammon.
- Lavori successivi a IBM Research (anni 2010-2020): contributi su RL applicato a vari domini industriali e di decision support, proseguendo una traiettoria più da ricercatore di laboratorio che da figura pubblica del campo.
La sua carriera è quella di un ricercatore solido con un grande successo isolato e molti contributi minori ma significativi. Non è la traiettoria spettacolare di Hinton, LeCun, Bengio (premi Turing 2018, fama mediatica), ma è una traiettoria di valore tecnico riconosciuto nella comunità di riferimento.
Pollack-Blair 1996: la critica costruttiva
Sezione intitolata “Pollack-Blair 1996: la critica costruttiva”Vale la pena espandere la critica di Pollack-Blair perché è un esempio interessante di rigore scientifico applicato a un risultato spettacolare. Pollack e Blair non contestano che TD-Gammon giochi bene a backgammon. Mostrano qualcosa di più sottile: una rete neurale di simile dimensione, addestrata con un algoritmo radicalmente più semplice (co-evolution di una popolazione di reti, senza alcun TD-learning, senza alcun gradient descent — solo selezione di reti che giocano meglio della media e mutazione casuale dei pesi), raggiunge un livello di gioco comparable a TD-Gammon 0.0.
L’implicazione: gran parte del merito che TD-Gammon attribuisce a TD-learning potrebbe in realta essere attribuibile a (a) la struttura del backgammon che facilita l’esplorazione, (b) la rappresentazione di input ben scelta, (c) la dimensione della rete adeguata al problema. TD-learning aggiunge qualcosa, ma forse meno di quanto si pensava.
Tesauro ha riconosciuto la critica nei suoi paper successivi e nelle interviste degli anni 2000. Le versioni 2.x e 3.x di TD-Gammon, che includono ricerca in avanti a 2-3 ply e training più lungo, vanno significativamente oltre il livello che il co-evolution di Pollack-Blair raggiunge. Ma il paper Pollack-Blair resta un richiamo metodologico importante: quando un metodo nuovo (TD-learning + NN) ottiene un risultato spettacolare, vale la pena chiedersi se metodi più semplici lo raggiungerebbero. Se si, il merito tecnico va ridimensionato. Se no, la differenza è la misura del valore aggiunto del metodo nuovo.
Questa cultura della baseline rigorosa è diventata standard nella comunità ML moderna. Ogni paper su un nuovo algoritmo deve confrontarsi con baseline serie. Pollack-Blair 1996 è uno dei primi esempi di questa cultura applicata a un risultato di reinforcement learning.
Come si usava TD-Gammon: il flusso di gioco
Sezione intitolata “Come si usava TD-Gammon: il flusso di gioco”Una nota operativa per chi vuole immaginare come si usava il programma. TD-Gammon non era un giocatore in tempo reale per umani: era un programma di ricerca che consumava ore di tempo macchina per addestrarsi e poi poteva essere usato in modalità “play” per generare mosse data una posizione. Per giocare contro un umano, serviva un’interfaccia esterna (Tesauro ne usava una rudimentale, basata su input testuale di posizioni e dadi). I match contro Robertie e altri master erano giocati di persona o via email, con il programma che produceva la mossa data una posizione e i dadi.
A partire dalla fine degli anni 90, programmi commerciali come Snowie e Jellyfish, derivati architetturalmente da TD-Gammon, hanno fornito interfacce grafiche complete e diventarono strumenti standard nel circuito competitivo. Un giocatore poteva analizzare le proprie partite mossa per mossa, vedere quale mossa la rete avrebbe scelto, calcolare l’equity (la differenza in millipoint tra la mossa fatta e la migliore mossa) e identificare gli errori. Questa pratica, oggi standard nel backgammon ad alto livello, è iniziata grazie all’accessibilità di programmi di livello world-class derivati da TD-Gammon.
La ricezione del paper Machine Learning 1992
Sezione intitolata “La ricezione del paper Machine Learning 1992”Il paper di Tesauro su Machine Learning del 1992, quattro pagine principali più appendici, viene pubblicato senza grande clamore. Machine Learning Journal era una rivista accademica seria ma di nicchia, letta principalmente dalla comunità ML; non era Nature o Science, e non aveva la visibilita necessaria per attirare attenzione fuori dal campo. La citazione count del paper cresce lentamente nei primi anni: poche decine di citazioni nel 1993-1995, qualche centinaio negli anni 2000, qualche migliaio dopo l’esplosione del deep RL post-2013. Oggi il paper è ovunque nei corsi RL, ma all’epoca era una pubblicazione “tra le altre”.
Il paper Communications of the ACM del 1995 ha avuto un impatto più ampio per due ragioni: CACM è una rivista letta da una comunità CS molto più vasta della sola ML, e l’esposizione era divulgativa, accessibile anche a chi non aveva familiarita con il formalismo RL. Ancora così, l’effetto “wake-up call” sul resto della comunità AI fu modesto. La narrativa dominante dell’AI degli anni 90 restava quella simbolica e poi statistica; le reti neurali erano una nicchia, e RL era una nicchia dentro la nicchia.
L’ironia storica è che, retrospettivamente, TD-Gammon è citato in quasi ogni introduzione di reinforcement learning come “il primo grande successo”. All’epoca, pochi lo videro così. Ci vollero AlphaGo (2016) e l’onda di pubblicità del deep RL post-DQN (2013-2015) perché TD-Gammon fosse riconosciuto come il precedente storico che era. Una conferma del pattern generale: i risultati spettacolari nelle scienze applicate non sono sempre riconosciuti subito; servono spesso eventi successivi che ricontestualizzano i precedenti, retrospettivamente, come pionieristici.
Una lezione metodologica generale
Sezione intitolata “Una lezione metodologica generale”C’è una lezione che vale la pena estrarre, valida non solo per TD-Gammon ma per tutti i risultati di ML applicato ai giochi. Quando un sistema raggiunge livello world-class in un dominio specifico, è facile commettere uno di due errori opposti: sopravvalutare (“la macchina capisce, è il futuro dell’AI”) o sottovalutare (“è solo un trucco, vale solo per quel gioco”). Entrambi gli errori sono comuni. La verita è che ogni successo è informativo per quanto riguarda il principio sottostante — in questo caso, RL + function approximation con self-play — e l’estensione di quel principio ad altri domini è una questione empirica, non automatica.
TD-Gammon dimostro nel 1992 il principio. Vent’anni dopo, AlphaGo e DQN dimostrarono che il principio scala a domini molto diversi, con adattamenti significativi. Il filo è continuo, ma le innovazioni di scala e di tecnica (deep CNN, MCTS, experience replay, target network, distributional RL) sono sostanziali. Riconoscere insieme la continuita e la discontinuita è il modo onesto di leggere la storia: TD-Gammon è il proof-of-concept del principio; AlphaGo è la prova che il principio scala; AlphaZero è la realizzazione pura del principio originale.

Esempio 1: una transizione TD su una posizione specifica
Sezione intitolata “Esempio 1: una transizione TD su una posizione specifica”Considera una posizione di backgammon in cui la rete stima . Il giocatore tira 6-3, valuta tutte le mosse legali, sceglie quella che porta alla posizione con stima . Non c’è ricompensa istantanea perché la partita non è finita. Con :
L’errore di TD è positivo: la stima di era pessimista. Con learning rate e gradiente calcolato dalla backpropagation sulla rete, l’update sposta i pesi nella direzione che aumenta leggermente . La stessa transizione contribuisce, attraverso la eligibility trace con , a propagare una piccola quota di update anche alla stima della mossa precedente , e a quella prima ancora con peso , e così via decadendo.
Nel corso di una singola partita di 50 mosse, la rete fa 50 update così. Nel corso di 1.5 milioni di partite, ne fa 75 milioni. Ognuno è piccolo, ma la struttura del segnale (vittoria/sconfitta a fine partita propagata all’indietro) garantisce che, in media, la rete migliori le sue stime nella direzione del valore vero della posizione.
Esempio 2: BKG vs TD-Gammon sulla stessa posizione
Sezione intitolata “Esempio 2: BKG vs TD-Gammon sulla stessa posizione”Immagina una posizione di metà partita in cui un giocatore deve decidere se rischiare un blot (pedina singola esposta) per costruire un punto chiave del proprio quadrante interno, o giocare conservativo. BKG, il programma di Berliner, valuta la posizione applicando un pacchetto di regole esplicite: “il controllo del punto 5 vale X, una pedina esposta in zona di tiro vale -Y, la fase di gioco è race quindi pesa Z di più il pip count”. Le costanti X, Y, Z sono state fissate a mano da Berliner sulla base della propria esperienza e di quella di consulenti maestri di backgammon. La valutazione è interpretabile riga per riga.
TD-Gammon prende la stessa posizione, la trasforma nelle 198 unità binarie di input, fa un forward pass attraverso la rete, e produce un singolo numero — diciamo 0.58. Non c’è una “spiegazione” della valutazione che si possa leggere come una concatenazione di regole. C’è solo il numero, prodotto da matrici di pesi che rappresentano cose imparate da centinaia di migliaia di partite. Se chiedi alla rete “perché 0.58?”, non ha risposta interpretabile. Ha solo un numero che, statisticamente, è risultato accurato in milioni di posizioni simili.
La differenza è ontologica. BKG è un sistema simbolico: ogni componente della valutazione corrisponde a un concetto leggibile da un esperto umano. TD-Gammon è un sistema sub-simbolico: la valutazione emerge da un calcolo distribuito su migliaia di parametri numerici, nessuno dei quali ha un’interpretazione individuale. La lezione storiografica che questo confronto suggeriva nel 1995 era che, a parita di domain (e a parita di sufficienza di dati e di compute), il sub-simbolico poteva battere il simbolico anche senza interpretabilita. Sarebbe diventato un tema centrale del dibattito post-2012 sul deep learning.
Esempio 3: il calcolo dell’eligibility trace su una sequenza breve
Sezione intitolata “Esempio 3: il calcolo dell’eligibility trace su una sequenza breve”Per fissare la meccanica della trace, immaginiamo una partita brevissima di tre stati: , dove è terminale con vittoria del giocatore al tratto. Le stime della rete sono , , (lo stato terminale ha valore noto). Usiamo , , .
Al passo 0: la trace è . Nessun update, perché non c’è ancora un errore di TD da applicare (è il primo stato).
Transizione : l’errore è . Aggiorniamo i pesi: , ossia un piccolo aumento dei pesi nella direzione che alza . La trace si aggiorna a .
Transizione : l’errore è . Aggiorniamo i pesi: . Notiamo che contiene sia il gradiente di (con peso 1) sia quello di (con peso , scontato). Quindi questo singolo update propaga una quota dell’informazione “ho appena vinto” anche allo stato , che era due passi prima.
In una partita reale di 50 mosse, ogni mossa contribuisce a una catena di update con decadimento . Il segnale di fine partita raggiunge mosse di metà partita con peso ancora significativo (es. , piccolo ma non zero), e mosse vicine alla fine con peso quasi pieno. È come se il segnale di vittoria/sconfitta “rimbalzasse” all’indietro lungo la partita, decadendo gradualmente.
Questo esempio è semplificato: la trace reale opera su milioni di parametri della rete, non su un singolo numero, e ogni update modifica simultaneamente tutti i parametri secondo i loro gradienti rispettivi. Ma la struttura concettuale è quella mostrata sopra.
Esempio 4: confronto con un metodo Monte Carlo puro
Sezione intitolata “Esempio 4: confronto con un metodo Monte Carlo puro”Per chiarire il vantaggio operativo di TD su Monte Carlo puro, immaginiamo un metodo alternativo: ogni partita si gioca fino in fondo senza alcun update, poi a fine partita si aggiornano le stime di tutte le posizioni visitate verso il return finale (1 o -1). È il metodo Monte Carlo “first-visit” (o “every-visit”), classico in RL.
Il problema: in una partita lunga 50 mosse, anche le mosse iniziali ricevono lo stesso segnale del return finale. Ma il return è dominato dal caso (i tiri di dadi) e dalle decisioni di tutte le mosse intermedie, non solo da quella iniziale. Quindi l’update sulla mossa iniziale è molto rumoroso: la mossa può essere stata buona ma la partita persa per altri motivi, o cattiva ma la partita vinta per fortuna. La varianza dell’update è alta, la convergenza è lenta.
TD() con fa l’opposto: aggiorna ogni stima verso la stima del prossimo passo, che è essa stessa rumorosa ma molto più vicina al valore vero (perché è separata da un solo passo, non da 50). La varianza è bassa, la convergenza è rapida ma c’è bias dovuto al bootstrapping. TD() con media tra i due estremi.
Tesauro misura sperimentalmente nel paper Machine Learning 1992 che converge più velocemente sia di sia di per il backgammon. La curva di apprendimento è quasi-monotona, senza catastrofiche oscillazioni. È un risultato empirico importante: dimostra che il trade-off bias-varianza ha un ottimo intermedio per il dominio del backgammon, e suggerisce (senza dimostrarlo formalmente) che lo stesso possa valere per altri domini con struttura simile.
Esempio 5: la scoperta del back game
Sezione intitolata “Esempio 5: la scoperta del back game”Tesauro racconta nel paper CACM del 1995 un episodio specifico. Durante la fase di addestramento di TD-Gammon 2.1, attorno alle 800.000 partite di self-play, osserva che la rete inizia a privilegiare strategie di back game (mantenere due o più pedine ancorate nel quadrante interno avversario) in posizioni dove la teoria umana raccomandava di ritirarsi e correre verso casa. Il back game è una strategia rischiosa: se l’avversario chiude il proprio quadrante interno prima che tu riesca a colpire una sua pedina, le tue pedine ancorate restano intrappolate e perdi quasi sicuramente. Ma se riesci a colpire, l’avversario deve rientrare attraverso il tuo quadrante interno (potenzialmente bloccato), e le probabilita si invertono.
I maestri umani consideravano il back game una strategia di disperazione, da usare solo quando il pip count era così sfavorevole da rendere comunque persa una corsa diretta. TD-Gammon lo usava più spesso, anche in posizioni meno disperate, e con un tasso di successo migliore della media umana. L’analisi successiva mostro che la rete aveva imparato, da self-play, a riconoscere posizioni in cui il rischio del back game era favorevole non in modo macroscopicamente ovvio, ma in una combinazione sottile di feature posizionali. Era una scoperta empirica fatta dalla rete, validata poi dai master.
Tesauro racconta nel paper CACM che, osservando questa scoperta, rimase sorpreso. Aveva pensato, all’inizio dell’esperimento, che se la rete avesse imparato a giocare ragionevolmente bene il backgammon, avrebbe replicato in modo approssimativo la teoria umana esistente. Non aveva immaginato che potesse trovare strategie nuove. La spiegazione, retrospettivamente, è che la teoria umana del backgammon era costruita su euristiche ragionevoli ma incomplete; la rete, non vincolata da quelle euristiche, esplorava lo spazio delle strategie da prospettive diverse e talvolta trovava ottimi locali che gli umani non avevano notato. Questo è il contributo metodologico più duraturo di TD-Gammon: la dimostrazione concreta che un sistema learning-based può scoprire strategie non ricalcabili dall’esperienza umana accumulata, anche in domini studiati per secoli.
Vale la pena fissare che il livello di novità delle scoperte di TD-Gammon è modesto rispetto a quanto AlphaGo dimostrerà vent’anni dopo nel Go (la celebre mossa 37 della partita 2 contro Lee Sedol, una mossa così inconsueta che gli analisti umani inizialmente la giudicarono un errore, e che si rivelo poi una mossa profonda). Ma il principio è lo stesso: il sistema impara senza pregiudizi umani e produce mosse che gli umani non avrebbero mai considerato, alcune delle quali si rivelano oggettivamente migliori. TD-Gammon è il primo programma a esibire questo pattern in modo ripetibile e documentato.
Applicazioni pratiche
Sezione intitolata “Applicazioni pratiche”[DATATO 2026-04] Questa sezione discute la filiazione documentata di TD-Gammon nei sistemi più recenti.
L’eredità di TD-Gammon è quasi esclusivamente nella linea di ricerca del reinforcement learning con function approximation. Il libro canonico di Sutton e Barto, Reinforcement Learning: An Introduction (prima edizione MIT Press 1998, seconda edizione 2018), dedica al programma una sezione intera (16.1 nella seconda edizione) come esempio paradigmatico di TD-learning applicato a un dominio non banale. Tutti i corsi universitari di RL post-2000 lo citano.
La filiazione documentata più rilevante è verso AlphaGo. Il paper Nature di David Silver e collaboratori (DeepMind, gennaio 2016, “Mastering the game of Go with deep neural networks and tree search”) cita esplicitamente Tesauro 1995 nei riferimenti dei Methods, e più nel dettaglio il successivo AlphaZero (Silver et al. Nature 2017) lo cita come precedente fondamentale per il principio di pure self-play senza dati umani. Le differenze tecniche sono significative: AlphaGo combina la rete di valutazione con Monte Carlo Tree Search (MCTS), mentre TD-Gammon usava al massimo una piccola ricerca a 2-3 ply senza MCTS. AlphaGo usa reti neurali convoluzionali profonde (decine di layer), mentre TD-Gammon era una rete shallow con uno o due hidden layer. AlphaGo separa policy network e value network, TD-Gammon ha una sola rete che produce direttamente la stima del valore. Ma il principio di base — pure self-play come unica fonte di dati di addestramento, temporal difference per propagare il segnale di esito, deep network come approssimatore — è quello di Tesauro.
C’è anche una filiazione indiretta verso DQN (Deep Q-Network), il sistema di Volodymyr Mnih e collaboratori (DeepMind, Nature febbraio 2015, “Human-level control through deep reinforcement learning”) che usa una rete neurale convoluzionale per giocare a videogame Atari. DQN usa Q-learning anziche TD-learning sulla state value, e introduce due trucchi importanti (experience replay e target network) per stabilizzare l’addestramento, ma il quadro concettuale è lo stesso: rete neurale come approssimatore di funzione valore, addestrata via reinforcement learning su esperienza generata interagendo con l’ambiente.
Una nota importante sulle differenze. AlphaGo aggiunge MCTS perché il Go ha una branching factor (≈250) molto più alta del backgammon (≈20) e perché manca della stocasticita dei dadi: una buona policy non basta, serve ricerca. AlphaZero (2017) rimuove ogni knowledge umana iniziale che AlphaGo conservava (training preliminare su partite umane, feature ingegnerizzate) e diventa il sistema più vicino allo spirito originale di TD-Gammon: solo regole del gioco, solo self-play, nessun dato umano. La citazione di Tesauro nel paper AlphaZero è quindi appropriata e non cerimoniale.
L’industria dei programmi di backgammon commerciali ha ereditato direttamente da TD-Gammon. Jellyfish (1995, di Fredrik Dahl, programma commerciale norvegese), Snowie (1998), e GNU Backgammon (open source, dai primi 2000) usano tutti reti neurali addestrate via TD-learning su self-play, con varianti architetturali e di training schedule. Tutti hanno raggiunto livello world-class entro la fine degli anni 90 e sono diventati strumenti standard di analisi nel circuito competitivo. Il rating system internazionale del backgammon online (FIBS, First Internet Backgammon Server, attivo dal 1992) registra regolarmente questi bot tra i top player globali.
C’è anche una linea di lavoro di Tesauro stesso che merita menzione: dopo TD-Gammon, negli anni 2000, lavoro a IBM su applicazioni di RL alla resource allocation in data center (allocazione di server a workload variabili) e alla gestione di sistemi computazionali complessi. Queste applicazioni sono meno note ma dimostrano che l’idea “RL come tecnica generale per problemi di decisione sequenziale sotto incertezza” si era radicata in IBM Research grazie al successo di TD-Gammon. Tesauro fece anche parte del team di IBM Watson nei primi 2010, contribuendo all’algoritmo di scelta della categoria (wagering strategy) durante le partite di Jeopardy! del 2011.
Una filiazione meno discussa ma reale è verso il temporal difference learning per problemi finanziari. Diversi gruppi nei primi 2000 (in particolare a JP Morgan, Goldman Sachs, e in alcuni hedge fund quantitativi) sperimentarono TD-learning con reti neurali per trading e portfolio management. I risultati pubblici sono scarsi (per ovvi motivi di vantaggio competitivo) ma riferimenti accademici come Moody-Saffell (2001) “Learning to Trade via Direct Reinforcement” citano TD-Gammon come precedente metodologico.
Dove si rompe
Sezione intitolata “Dove si rompe”Vediamo i limiti reali di TD-Gammon e i fraintendimenti tipici che il suo successo ha attirato.
Il backgammon ha proprietà favorevoli che non si trasferiscono a tutti i giochi. La stocasticita dei dadi fornisce esplorazione naturale, evitando che la policy si fissi su comportamenti subottimi: ogni turno la rete è obbligata a considerare situazioni che non avrebbe scelto. La terminazione è garantita: ogni partita finisce in tempo finito con un esito ben definito. La branching factor è bassa (~15-20). La valutazione di posizione conta più della ricerca in profondita. Tutte queste proprietà rendono il backgammon un dominio benigno per l’approccio TD-Gammon. Negli scacchi, nel Go, nei videogame complessi, alcune di queste proprietà mancano e l’approccio puro non basta.
Pollack-Blair 1996 mostro che alcuni successi erano dovuti a quirks di backgammon, non solo a TD. Jordan Pollack e Alan Blair (informatici alla Brandeis University) pubblicano nel 1996 a NIPS un paper intitolato “Why did TD-Gammon work?” in cui mostrano che una rete neurale addestrata con un algoritmo di co-evolution (popolazione di reti che giocano l’una contro l’altra senza alcun TD-learning) raggiunge un livello di gioco intermedio non lontano da quello di TD-Gammon 0.0. La conclusione di Pollack-Blair, condivisa con Tesauro stesso, è che parte del successo di TD-Gammon era attribuibile alla struttura particolarmente liscia del fitness landscape del backgammon (per via della stocasticita dei dadi, che riduce le instabilita di self-play), più che alla potenza intrinseca di TD-learning. Il paper non sminuisce il risultato di Tesauro ma lo contestualizza: TD-learning era una scelta efficace, non l’unica possibile, e il dominio aiutava.
Schraudolph-Dayan-Sejnowski 1994 falli su Go. Nicol Schraudolph, Peter Dayan e Terry Sejnowski (allora al Salk Institute) provarono nel 1994 ad applicare lo stesso schema di TD-Gammon al Go con un paper a NIPS, “Temporal difference learning of position evaluation in the game of Go”. Il risultato fu modesto: la rete imparava qualcosa, ma restava molto al di sotto del livello di un giocatore intermedio umano. Le ragioni sono quelle accennate sopra (branching factor enorme, mancanza di stocasticita, valutazione di posizione molto più sottile), e per oltre vent’anni il Go è rimasto fuori portata per metodi simili. AlphaGo nel 2016 dovette aggiungere MCTS profondo, deep CNN, training su partite umane (poi rimosso in AlphaZero) per superare questi ostacoli.
Il successo non si tradusse in revival immediato del RL nel mainstream. Questa è forse la più sorprendente constatazione storica. Tra il 1995 e il 2013 (anno di pubblicazione del primo paper su DQN), il reinforcement learning combinato a reti neurali resta una nicchia accademica. Gli scacchi (Deep Blue, 1997) prendono la scena pubblica e suggeriscono che il “modo giusto” di battere i campioni umani sia brute force minimax con valutazioni hand-crafted, non self-play con reti neurali. Le pubblicazioni di Tesauro tra il 1995 e il 2002 vengono lette ma non scatenano una corsa di follow-up. Tesauro stesso a IBM continua a lavorare su altri temi (RL per resource allocation, jeopardy! con Watson) ma non riesce a generare un programma di ricerca su larga scala su RL+NN. La spiegazione più plausibile è una combinazione di (a) successo confined to backgammon che non sembrava trasferibile, (b) scarsita di hardware (GPU programmabili sarebbero arrivate dopo il 2007), (c) assenza di dati su larga scala (ImageNet 2009), (d) dominanza del paradigma statistico (SVM, ensemble) in ML. I tre ingredienti che faranno esplodere il deep learning nel 2012 — dati, GPU, accumulo di expertise — non erano ancora pronti per RL nel 1995.
Tesauro non è diventato celebrita ML mainstream come Hinton o LeCun. Resta un ricercatore stimato nella comunità RL ma poco noto al di fuori. Il suo successo era considerato “confined to backgammon” e questo limito la sua influenza sulla narrazione generale dell’AI. Una lezione storiografica utile: una vittoria isolata in un dominio specifico non basta a riorientare l’agenda di un campo, anche quando dimostra un principio generale. Servono successi ripetuti, in domini diversi, oppure un singolo risultato così spettacolare da catturare la stampa generalista (cosa che Deep Blue 1997 e AlphaGo 2016 fecero, e TD-Gammon 1992 non fece nonostante meritasse).
TD-Gammon NON ha rivitalizzato le reti neurali nell’AI mainstream. Quel rilancio arriva con AlexNet 2012, vedi imagenet-alexnet-2012, e con la disponibilita combinata di GPU programmabili, dataset su scala milione, e nuove tecniche di regolarizzazione (dropout, batch norm, ReLU). TD-Gammon è citato nei retrospettivi del periodo deep learning come precedente, ma il filo diretto che porta ad AlexNet passa per altri canali (CNN da LeCun, RBM pretraining da Hinton, supervised learning su dataset etichettati).
Confondere TD-Gammon con AlphaGo. Errore comune nelle ricostruzioni divulgative. Le due famiglie condividono il principio del self-play ma differiscono in molto altro: depth della rete (shallow vs deep), uso di MCTS (no vs si), separazione policy/value (no vs si), dimensione del dominio (backgammon vs Go), epoca di compute (workstation IBM 1992 vs cluster TPU 2016). TD-Gammon è il proof-of-concept; AlphaGo è il sistema industriale che esegue il principio su scala radicalmente diversa.
“Le strategie scoperte da TD-Gammon erano oggettivamente migliori di quelle umane”. Sfumatura. Erano marginalmente migliori in media, su grande numero di posizioni, secondo le metriche di rollout statistico. Su singole posizioni, gli umani migliori a volte facevano scelte ancora migliori. La differenza tra TD-Gammon 3.0 e i top player umani era piccola, dell’ordine di pochi millipoint per gioco (la metrica standard nel backgammon competitivo). Il programma non “stracciava” gli umani come AlphaGo stracciava Lee Sedol nel 2016: era leggermente superiore in media, sufficiente a essere considerato world-class ma non a chiudere il dominio. Solo le versioni più recenti di GNU Backgammon e Snowie, addestrate per anni con rollout su larga scala, hanno reso evidente la superiorità programmatica.
“Il doubling cube era un dettaglio”. Falso. Il doubling cube è una componente strategica importante del backgammon competitivo. Decidere quando offrire un raddoppio e quando accettarne uno richiede valutazioni probabilistiche che, in alcune posizioni, sono più sottili della scelta della mossa. TD-Gammon nelle versioni 0.0-2.0 ignora il cube. Le versioni 2.1 e 3.0 lo gestiscono con un modulo separato, addestrato su rollout statistici di posizioni etichettate dalla rete principale. Senza una buona strategia di cube, anche la migliore valutazione di mossa lascia molti punti sul tavolo. Le valutazioni “TD-Gammon ha raggiunto i top player umani” si riferiscono al gioco completo includendo cube management, e questo ha richiesto ingegneria aggiuntiva oltre alla rete TD principale.
“TD-learning è sempre la scelta giusta in RL”. No. TD-learning ha vantaggi (apprende online, propaga incrementalmente) ma soffre di problemi noti: bias dovuto al bootstrapping (i target sono stime, non valori veri), instabilita con function approximation off-policy (la deadly triad menzionata sopra), sensibilità all’inizializzazione. Per molti problemi RL moderni si preferiscono metodi policy gradient (REINFORCE, PPO, A3C) o metodi actor-critic ibridi. TD puro è raramente la prima scelta in sistemi state-of-the-art post-2015, anche se rimane un pezzo importante di molti algoritmi.
“6 milioni di partite sono sempre necessari”. No. La data efficiency dei metodi RL è notoriamente scadente, ma nel caso di TD-Gammon il numero astronomico di partite era reso possibile dalla rapidita del simulatore (una partita di backgammon simulata in pochi millisecondi su workstation 1995, oggi ancora più veloce). Per domini dove la simulazione è costosa (robotica reale, esperimenti fisici), l’approccio TD-Gammon non è applicabile così com’è: servono tecniche di sample efficiency molto più sofisticate (model-based RL, offline RL, transfer learning).
“La rete capisce il gioco”. Affermazione filosoficamente carica e sostanzialmente vacua. La rete codifica una funzione che approssima la probabilita di vittoria. Non c’è una rappresentazione interna leggibile come “controllo del punto 5” o “fase di race avanzata”; c’è solo un calcolo distribuito su 30.000 pesi. Dire che la rete “capisce” il backgammon è una metafora utile per la divulgazione ma non ha contenuto tecnico verificabile. Quello che si può dire è che la rete approssima accuratamente una funzione di valutazione che, applicata greedy su rollout statistici, produce gioco di qualità superiore a quello dei master umani. Niente di più, niente di meno.
“TD-Gammon ha risolto il backgammon”. No, nel senso tecnico di “soluzione” di un gioco. Risolvere un gioco significa calcolare la strategia ottimale per ogni posizione raggiungibile, una proprietà che è stata raggiunta solo per giochi piccoli (Connect Four, dama in alcune varianti). Il backgammon non è risolto: TD-Gammon e i suoi successori producono mosse molto buone, talvolta ottimali, ma non c’è nessuna garanzia formale di ottimalità. La probabilita di vincita stimata dalla rete è un’approssimazione, non un valore vero, e in alcune posizioni l’approssimazione è imprecisa. Per il backgammon, la “soluzione” formale è probabilmente fuori portata anche con il compute moderno, perché lo spazio di stati è enorme e il branching factor con i dadi è ampio.
“Self-play funziona sempre”. Un altro fraintendimento popolare post-AlphaGo. Self-play funziona quando: (a) il dominio ha un esito ben definito (vince uno, l’altro perde), (b) il simulatore è veloce e fedele, (c) la combinazione di esplorazione (intrinseca o esplicita) copre lo spazio di stato in modo ragionevole, (d) la function approximation è sufficientemente espressiva. Quando una di queste condizioni manca, self-play può collassare in equilibri patologici (entrambi i giocatori convergono a strategie subottimali ma reciprocamente bilanciate), oscillare ciclicamente tra strategie senza migliorare, o non riuscire a esplorare regioni importanti dello spazio di stato. AlphaStar (StarCraft, 2019) e OpenAI Five (Dota 2, 2018-2019) hanno richiesto innovazioni significative oltre il puro self-play per superare questi problemi: training contro popolazioni di avversari diversi, league play, regularizzazione esplicita.
“TD-Gammon era una rete deep”. Falso. TD-Gammon è una rete shallow: uno o due hidden layer, qualche centinaio di unità per layer al massimo. Le reti deep moderne hanno decine o centinaia di layer e milioni o miliardi di parametri. La differenza di scala è enorme. Quando si dice “TD-Gammon è il precursore del deep RL”, il “deep” non si riferisce all’architettura della rete (che era shallow) ma al principio “neural network as function approximator + RL”. La filiazione è concettuale, non architetturale.
“Tesauro è stato l’unico a pensare a self-play”. Falso. Self-play come idea generale era stata proposta già negli anni 50 (Arthur Samuel con il suo programma di dama del 1959 usava una forma rudimentale di self-play, vedi capitoli sulla preistoria dell’AI). Quello che Tesauro fece di nuovo fu combinarlo con TD-learning e con una rete neurale come approssimatore. La novità era nella combinazione, non in nessuno dei tre ingredienti separatamente.
Vale la pena fissare il merito di Samuel, che è spesso dimenticato. Il programma di dama di Arthur Samuel su un IBM 701 nel 1959 usava una funzione di valutazione lineare con coefficienti aggiornati attraverso una forma primitiva di temporal difference (anche se Samuel non lo chiamava così). Imparava giocando contro versioni precedenti di sé stesso. Raggiunse un livello discreto di gioco (non world-class, ma chiaramente migliore di un principiante). La differenza con TD-Gammon è di scala (rete neurale con migliaia di parametri vs valutazione lineare con qualche decina di feature), di dominio (backgammon stocastico vs dama deterministica), e di formalizzazione algoritmica (TD() di Sutton vs euristica di Samuel). Ma il principio “self-play + funzione di valutazione adattata via gradient” è lo stesso. La filiazione storica è documentata in Sutton-Barto e in molte storie di AI.
“TD-Gammon avrebbe potuto essere fatto cinque anni prima”. Speculazione. Gli ingredienti (algoritmo TD, reti neurali con backprop, hardware adeguato) erano disponibili dal 1988-89. In linea di principio, qualcuno avrebbe potuto costruirlo prima. Nella pratica, serviva la combinazione di expertise specifica (Tesauro come backgammon player + ML researcher), accesso a un ambiente di ricerca con libertà esplorativa (IBM Research), e un’idea sufficientemente eretica per il periodo (pure self-play senza dataset umano). Ricostruzioni controfattuali sono interessanti ma non istruttive: TD-Gammon è successo quando è successo, e nessun programma simile è apparso in parallelo, suggerendo che la convergenza degli ingredienti non era casuale.


Collegamenti
Sezione intitolata “Collegamenti”- reti-neurali-80-90 — il filone neurale parallelo. TD-Gammon è uno dei pochi successi pratici plateali del filone connessionista negli anni 90, citato di passaggio nel cap 14 ma qui sviluppato per esteso.
- primo-inverno-ai — il colpo di Minsky-Papert 1969 contro le reti neurali a singolo strato a cui il filone connessionista risponde nei decenni successivi. TD-Gammon usa una rete multi-strato addestrata con backprop, l’algoritmo che Perceptrons aveva mostrato necessario.
- secondo-inverno-ai — il contesto in cui TD-Gammon emerge. Mentre i sistemi esperti collassano e i finanziamenti AI si riducono, IBM Research mantiene spazio per ricerca a lungo termine.
- sistemi-esperti — il paradigma simbolico di knowledge engineering che BKG di Berliner rappresenta nel dominio backgammon, e che TD-Gammon supera con un approccio puramente learning-based.
- rinascita-statistica-90 — il paradigma statistico (Bayesian nets, HMM, primi SVM) che domina ML accademico negli anni 90. TD-Gammon è ortogonale: usa reti neurali e RL, due famiglie ai margini di entrambi i paradigmi.
- imagenet-alexnet-2012 — il rilancio mainstream delle reti neurali. TD-Gammon non causo questo rilancio (passarono 20 anni in mezzo) ma è retrospettivamente riconosciuto come uno dei precedenti dimostrativi.
dqn-atari-2013(in preparazione) — la filiazione tecnica diretta. DQN usa reti neurali convoluzionali per giocare a videogame Atari via Q-learning, eredità da TD-Gammon il principio “deep approximator + RL”.alphago-2016(in preparazione) — la filiazione più citata. AlphaGo combina deep CNN, MCTS e self-play. Il paper Nature 2016 cita esplicitamente Tesauro 1995. AlphaZero 2017 è ancora più vicino allo spirito originale.deep-blue-1997(in preparazione) — il contrappunto degli scacchi. Stesso ente di ricerca (IBM), stesso obiettivo (battere campioni umani), approccio radicalmente diverso (brute force minimax con valutazione hand-crafted, no learning).q-learning(Parte V, in preparazione) — l’algoritmo cugino di TD-learning, addestra Q(s,a) anziche V(s). Watkins 1989. Base di DQN e di tutta la famiglia value-based RL.markov-decision-process(Parte V, in preparazione) — il framework formale che inquadra il backgammon e in generale ogni problema di RL. Stati, azioni, transizioni stocastiche, ricompense, policy ottimale.policy-gradient(Parte V, in preparazione) — la famiglia alternativa a value-based RL, addestra direttamente la policy. Non usata in TD-Gammon ma centrale in REINFORCE, A2C/A3C, PPO.mlp-backprop(Parte VIII, in preparazione) — la versione tecnica di backpropagation usata in TD-Gammon, indipendente dal contesto storico.rnn(Parte VIII, in preparazione) — TD-Gammon è una rete feedforward, non ricorrente. Ma il principio di propagare un segnale all’indietro nel tempo via eligibility trace ha analogie operative con il training di RNN tramite BPTT, da menzionare per chiarire la distinzione.
Per andare oltre
Sezione intitolata “Per andare oltre”- Tesauro, G. (1992). “Practical Issues in Temporal Difference Learning”. Machine Learning, 8, 257-277. Il paper che presenta TD-Gammon 1.0 alla comunità ML. Tecnico ma leggibile, con le scelte di iperparametri e le curve di apprendimento documentate.
- Tesauro, G. (1995). “Temporal Difference Learning and TD-Gammon”. Communications of the ACM, 38(3), 58-68. Esposizione divulgativa per un pubblico CS generalista, scritta dopo i risultati di TD-Gammon 2.1. Da leggere prima del paper Machine Learning per orientarsi.
- Sutton, R.S. (1988). “Learning to Predict by the Methods of Temporal Differences”. Machine Learning, 3(1), 9-44. Il paper foundational sul TD-learning. Necessario per capire la formula di update di TD-Gammon.
- Sutton, R.S., Barto, A.G. (2018, seconda edizione). Reinforcement Learning: An Introduction. MIT Press. Disponibile gratuitamente online sul sito di Sutton. Sezione 16.1 dedicata a TD-Gammon. Il riferimento canonico per RL.
- Pollack, J.B., Blair, A.D. (1996). “Why did TD-Gammon work?”. Advances in Neural Information Processing Systems, 9. Critica costruttiva del successo di TD-Gammon. Mostra che parte dei meriti vanno alla struttura del backgammon, non solo a TD.
- Schraudolph, N.N., Dayan, P., Sejnowski, T.J. (1994). “Temporal difference learning of position evaluation in the game of Go”. Advances in Neural Information Processing Systems, 7. Il tentativo fallito di replicare TD-Gammon su Go. Importante per capire i limiti del trasferimento.
- Berliner, H. (1980). “Backgammon Computer Program Beats World Champion”. Artificial Intelligence, 14(2), 205-220. Il report di Berliner sulla vittoria di BKG su Luigi Villa. Da leggere per capire come si pensava il problema prima di TD-Gammon, e per la franca ammissione di Berliner sul ruolo della fortuna.
- Silver, D. et al. (2016). “Mastering the game of Go with deep neural networks and tree search”. Nature, 529, 484-489. Il paper di AlphaGo. La sezione Methods cita Tesauro 1995 nei riferimenti.
- Silver, D. et al. (2017). “Mastering the game of Go without human knowledge”. Nature, 550, 354-359. Il paper di AlphaZero. Lo spirito puro self-play di TD-Gammon è qui realizzato su Go.
- Samuel, A.L. (1959). “Some Studies in Machine Learning Using the Game of Checkers”. IBM Journal of Research and Development, 3(3), 210-229. Il primissimo precedente storico di self-play applicato a un gioco. Da leggere come benchmark del livello di sofisticazione raggiungibile prima delle reti neurali e di TD formalizzato.
- Mnih, V. et al. (2015). “Human-level control through deep reinforcement learning”. Nature, 518, 529-533. Il paper di DQN. Dimostra che il principio “deep network + RL” scala a videogame Atari, decenni dopo TD-Gammon. Cita Tesauro nei riferimenti come precedente metodologico.
- Robertie, B. (2002). Modern Backgammon. Gammon Press. Il principale aggiornamento della teoria del backgammon competitivo dopo TD-Gammon. Documenta come e perché i master umani hanno modificato il loro repertorio in seguito alle scoperte computazionali.
- Schultz, W. (1997). “A neural substrate of prediction and reward”. Science, 275, 1593-1599. Il paper sui neuroni dopaminergici che codificano un segnale TD-like. Riferimento per il ponte tra RL algoritmico e neuroscienza.
- Watkins, C.J.C.H. (1989). Learning from Delayed Rewards. PhD thesis, Cambridge University. La tesi che introduce Q-learning, l’algoritmo cugino di TD-learning su cui si baserà DQN. Da leggere insieme a Sutton 1988 per il quadro completo della famiglia value-based.
Una nota finale sul lettore. Questo capitolo è denso di nomi, date, paper. Non è necessario memorizzare ogni dettaglio per usare la wiki: i collegamenti incrociati con i capitoli su
dqn-atari-2013,alphago-2016,q-learning,markov-decision-processpermettono di ricostruire la mappa concettuale più volte da angolazioni diverse. La cosa importante è il principio: nel 1992, in un piccolo laboratorio del Watson Center, è stato dimostrato per la prima volta che pure self-play con una rete neurale può battere i campioni umani in un gioco non banale. Il resto della storia, fino ad AlphaZero e oltre, è espansione e raffinamento di questa singola intuizione.
[DATATO 2026-04] Una nota su come si presenta TD-Gammon retrospettivamente alla luce dei sistemi più recenti. Nei corsi RL contemporanei e nei retrospettivi storici dell’AI, TD-Gammon è citato come pietra miliare quasi-dimenticata che anticipava AlphaGo di 24 anni. La frase è retorica e contiene del vero: il principio era li, già funzionante, prima che il filone deep learning lo riscoprisse. Ma “anticipare” non significa “causare”. AlphaGo non sarebbe esistito senza i progressi indipendenti su CNN profonde, MCTS, hardware GPU/TPU, dataset di partite umane di Go disponibili da KGS Go Server. La filiazione concettuale è reale; la filiazione causale è più sfumata. Riconoscere entrambe è il modo onesto di leggere la storia.
Per il lettore che vuole approfondire empiricamente il funzionamento di TD-Gammon, l’ambiente di reinforcement learning OpenAI Gym (poi Gymnasium dal 2022) include implementazioni di backgammon e altri giochi simili che permettono di sperimentare con algoritmi TD-learning, Q-learning, policy gradient su un dominio analogo. Ricostruire una versione semplificata di TD-Gammon è un esercizio classico nei corsi RL universitari ed è alla portata di chiunque conosca PyTorch o TensorFlow.
Questa è la fine del capitolo. Il prossimo passo logico nella mappa storica della wiki è imagenet-alexnet-2012, il rilancio mainstream delle reti neurali, oppure il filo dei giochi che porta a
deep-blue-1997e poi adalphago-2016.