Word2vec 2013: parole come vettori
Sei miliardi di parole, trecento dimensioni, un giorno di addestramento su CPU multi-core senza GPU. Word2vec produce vettori in cui, su un test famoso, il vettore di “king” meno il vettore di “man” più il vettore di “woman” cade vicino al vettore di “queen”. Per il natural language processing, il 2013 è l’anno in cui la rappresentazione del significato smette di essere un problema di feature engineering e diventa un problema di scala.
Perché questo capitolo
Sezione intitolata “Perché questo capitolo”Nel 1957 il linguista britannico John Rupert Firth (1890-1960, professore alla School of Oriental and African Studies di Londra, primo titolare di una cattedra di linguistica generale nel Regno Unito) pubblica una raccolta di saggi in cui compare la frase che entrerà in tutti i corsi di semantica computazionale dei decenni successivi: “You shall know a word by the company it keeps”. Conoscerai una parola dalla compagnia che frequenta. L’idea, in sé, è antica: è la semantica distribuzionale, la tesi che il significato di una parola si manifesti nei contesti in cui la parola appare. Cinquantasei anni dopo Firth, un paper di tredici pagine firmato da quattro ricercatori di Google trasforma quella tesi filosofica in un algoritmo che gira su un laptop e produce vettori utili per quasi qualunque task di NLP.
Word2vec ha per il natural language processing il ruolo che imagenet-alexnet-2012 ha per la computer vision, sull’altro lato della frontiera percettiva. AlexNet dimostra a settembre 2012 che addestrare reti profonde su grandi dataset di immagini batte il feature engineering manuale. Sei mesi dopo, a gennaio 2013, Mikolov e colleghi mostrano che addestrare un modello molto più semplice su un grande corpus di testo produce rappresentazioni dense che battono il feature engineering linguistico. La simmetria è notevole: due paradigmi paralleli, due benchmark diversi, lo stesso messaggio. La conoscenza di dominio cristallizzata in feature progettate a mano cede il passo a rappresentazioni apprese end-to-end da grandi corpora.
C’è una terza ragione per cui il capitolo conta, ed è di lessico. Prima del 2013, “embedding” è un termine di nicchia, usato in pochi paper di language modeling neurale. Dopo word2vec, “embedding” diventa una parola standard del vocabolario operativo del machine learning: si parla di word embeddings, sentence embeddings, image embeddings, user embeddings, knowledge graph embeddings, fino agli embedding layer dei transformer e ai vector store dei sistemi di retrieval. Word2vec non inventa l’idea di rappresentare oggetti come vettori densi, ma è il momento in cui l’idea diventa cultura comune e infrastruttura riusabile.
Contesto
Sezione intitolata “Contesto”Il capitolo prende il filo direttamente da reti-neurali-80-90, dove abbiamo visto la traversata silenziosa del filone connessionista, e da imagenet-alexnet-2012, che racconta il momento spartiacque sull’altro lato del benchmark. Per il NLP, lo stato dell’arte nel 2012 è ancora dominato da pipeline sopra feature manuali: lemmatizzazione, part-of-speech tagging, parsing sintattico, n-gram statistics, TF-IDF (Term Frequency-Inverse Document Frequency, una pesatura statistica che dà importanza alle parole frequenti in un documento ma rare nel corpus). Sopra queste feature gira spesso una Support Vector Machine o un classificatore lineare regolarizzato. Le rappresentazioni delle parole, dove esistono, sono sparse e simboliche: un vocabolario di centomila parole produce vettori con centomila dimensioni, una sola posizione a 1 per ciascuna parola (one-hot encoding), oppure una matrice termine-documento con la stessa logica.
Il filone alternativo della semantica distribuzionale ha però una storia che parte da molto prima. Latent Semantic Analysis (LSA), introdotta da Scott Deerwester, Susan Dumais e collaboratori a Bellcore in un paper del 1990 sul Journal of the American Society for Information Science, applica una decomposizione ai valori singolari (Singular Value Decomposition, SVD) a una matrice termine-documento per ottenere una rappresentazione a bassa dimensione delle parole. L’intuizione di base: parole che appaiono in documenti simili finiscono vicine nello spazio ridotto. LSA produce vettori densi di poche centinaia di dimensioni e funziona bene per recupero di documenti, ma è costosa (SVD su matrici enormi) e statica (ogni nuovo documento richiede ricalcolo). L’Hyperspace Analogue to Language di Curt Burgess e Kevin Lund (1996) è una variante coeva basata su matrici di co-occorrenza in finestre testuali.
Il filone neurale arriva con Yoshua Bengio, Rejean Ducharme, Pascal Vincent e Christian Jauvin, che pubblicano nel 2003 sul Journal of Machine Learning Research il paper “A Neural Probabilistic Language Model”. L’idea: addestrare una rete neurale a predire la parola successiva data una finestra di parole precedenti, e nel farlo apprendere automaticamente una matrice di embedding in cui ogni parola è un vettore di poche centinaia di dimensioni. Gli embedding sono effetto collaterale del task di language modeling. Il problema: la rete è lenta. L’output softmax sull’intero vocabolario costa proporzionalmente al numero di parole (decine di migliaia o più), e ogni passo di training è pesante. Bengio et al. devono ridurre il vocabolario e accettare tempi di training di settimane per corpora modesti.
Ronan Collobert (informatico francese, allora a NEC Labs Princeton, poi a IDIAP e Facebook AI Research) e Jason Weston (informatico britannico, NEC Labs poi Google poi Meta) pubblicano nel 2008 a ICML il paper “A Unified Architecture for Natural Language Processing”, che propone di apprendere word embeddings tramite un task ausiliario diverso dal language modeling pieno: distinguere finestre di testo reali da finestre con la parola centrale sostituita a caso. Il task è più economico, gli embedding emergono comunque, e il paper estende l’idea a part-of-speech tagging, named entity recognition e altri task downstream con gli stessi vettori. Lo stesso gruppo di idee viene esplorato nei tardi anni 2000 da Andriy Mnih e Geoffrey Hinton con i log-bilinear models e dalle loro varianti gerarchiche.
A inizio 2013, gli ingredienti per un salto sono pronti. La semantica distribuzionale è un’idea vecchia di mezzo secolo. Le architetture neurali per language modeling esistono da dieci anni. I corpora di scala internet sono disponibili dentro Google. Mancava qualcuno che semplificasse l’architettura abbastanza da poterla addestrare su miliardi di parole in un giorno, e che dimostrasse che gli embedding così prodotti hanno proprietà inattese.
Quel qualcuno è Tomas Mikolov, informatico ceco nato nel 1982 a Brno. Mikolov fa il PhD alla Brno University of Technology con tesi del 2012 su modelli ricorrenti per language modeling: il suo lavoro mostra che le RNN (Recurrent Neural Networks, reti neurali con stato interno che si aggiorna passo passo lungo una sequenza) battono i modelli n-gram su dataset standard di speech recognition. Durante il dottorato fa stage prima a Microsoft Research, poi a Google Brain (2012-2014). È a Google, lavorando con Kai Chen, Greg Corrado e Jeffrey Dean (informatico statunitense, 1968-, uno degli ingegneri leggendari di Google, co-creatore di MapReduce, BigTable, TensorFlow), che concepisce ed esegue word2vec. Dopo Google, Mikolov si trasferisce a Facebook AI Research nel 2014, dove sviluppa fastText con Bojanowski, Grave e Joulin. Nel 2020 lascia FAIR e torna in Repubblica Ceca, al Czech Institute of Informatics, Robotics and Cybernetics (CIIRC) della Czech Technical University di Praga, dove continua a lavorare su modelli di linguaggio.
Vale la pena un dettaglio sulle traiettorie dei co-autori, perché’ aiutano a inquadrare l’ecosistema da cui word2vec emerge. Jeff Dean è a Google dal 1999, ha co-progettato gli scheduler distribuiti che rendono possibile elaborare il corpus Google News in tempi praticabili. Greg Corrado è uno dei co-fondatori di Google Brain (2011, insieme ad Andrew Ng e Jeff Dean stesso). Kai Chen è un ricercatore di Google con background in machine learning applicato. Il gruppo non è un laboratorio di teoria pura: è un mix di ingegneri di sistemi e ricercatori che hanno accesso diretto sia a corpora enormi sia a infrastruttura di calcolo distribuita. La velocità con cui word2vec passa da idea a paper a codice rilasciato pubblicamente (gennaio-luglio 2013) riflette questa combinazione.

L’intuizione
Sezione intitolata “L’intuizione”Angolo linguistico-filosofico: il significato come compagnia
Sezione intitolata “Angolo linguistico-filosofico: il significato come compagnia”Il primo angolo è quello che Firth aveva indicato. La tesi distribuzionale dice: il significato di una parola non è un’entità platonica fissata in un dizionario, è un pattern di co-occorrenza. Se nei testi che hai a disposizione la parola medico compare spesso vicino a paziente, ospedale, visita, diagnosi, e raramente vicino a trattore, raccolto, aratro, allora il significato di medico si lascia descrivere — almeno parzialmente — da quel profilo di vicinanze. Cambia il profilo, cambia il significato. Una parola che cambia compagnia col tempo cambia anche significato (gli storici della lingua chiamano questo fenomeno semantic shift).
Filiazione esplicita: word2vec discende dalla semantica distribuzionale di Firth nel senso storiografico forte. I paper di Mikolov citano la tradizione, e l’intero framework operativo poggia sull’assunzione che predire il contesto (o predire una parola dal suo contesto) sia un buon proxy per imparare significato. Non è un’analogia: è un’implementazione algoritmica diretta di un’ipotesi linguistica. La filiazione passa attraverso LSA, attraverso Bengio 2003, attraverso Collobert-Weston 2008. Word2vec ne è il punto di cristallizzazione efficiente.
L’idea ha una conseguenza che colpisce. Se due parole hanno profili di co-occorrenza molto simili — gatto e cane compaiono entrambe vicino a animale, coda, pelo, cibo, padrone, cucciolo — allora i loro vettori, per costruzione, dovranno essere vicini nello spazio. Se invece i profili divergono — gatto vicino a miagola, cane vicino a abbaia — i vettori conserveranno una direzione di differenza. Lo spazio degli embedding diventa una mappa in cui similarità semantica e similarità geometrica coincidono per costruzione.
C’è anche un risvolto epistemologico. Se accetti la tesi distribuzionale, il significato non è qualcosa che il sistema deve “capire” nel senso forte, è qualcosa che il sistema può’ approssimare a partire da statistiche di superficie. Per chi viene dalla tradizione simbolica (vedi ai-simbolica-anni-60 e sistemi-esperti), è una posizione filosoficamente provocatoria: dice che gran parte del significato lessicale è computabile senza referenti, senza ontologie esplicite, senza grounding sensoriale. Negli anni successivi a word2vec, questa posizione diventerà una delle linee di faglia tra chi vede gli LLM come “pappagalli stocastici” e chi vede in essi una forma legittima di rappresentazione semantica.
Angolo algoritmico: predire come task ausiliario per imparare
Sezione intitolata “Angolo algoritmico: predire come task ausiliario per imparare”Il secondo angolo è tecnico. Per ottenere embedding utili, serve un compito di addestramento. Il compito non è “produrre un buon embedding” — questo è troppo vago per essere ottimizzato direttamente. Il compito è predire: data una parola, predire le parole vicine; oppure date le parole vicine, predire la parola al centro. L’embedding è ciò che rende facile la predizione, ed emerge come effetto collaterale dell’addestramento.
Mikolov propone due architetture, speculari tra loro. CBOW (Continuous Bag-of-Words): prendi la parola centrale come bersaglio, prendi le parole intorno come input, e addestra un modello a predire la centrale dalle laterali. Skip-gram: prendi la parola centrale come input, prendi le parole intorno come bersagli, e addestra un modello a predire le laterali dalla centrale. Le due architetture sono speculari ma non equivalenti: CBOW è più veloce e funziona meglio su parole frequenti, Skip-gram è più lento e funziona meglio su parole rare e su dataset grandi.
L’innovazione di word2vec rispetto a Bengio 2003 e a Collobert-Weston 2008 non sta tanto nella formulazione del task — predire il contesto è un’idea già’ nell’aria — quanto in una serie di tagli ingegneristici che riducono drasticamente il costo computazionale. Senza quei tagli, il modello non si sarebbe potuto addestrare su sei miliardi di parole in tempi praticabili. Word2vec è un esempio paradigmatico di un risultato che dipende meno dall’idea generale e più dalla cura di rendere efficiente ogni passo del calcolo.
La meccanica
Sezione intitolata “La meccanica”Semantica distribuzionale e LSA: la preistoria operativa
Sezione intitolata “Semantica distribuzionale e LSA: la preistoria operativa”Per ancorare l’intuizione, conviene partire dalla preistoria operativa. La forma più semplice di rappresentazione distribuzionale è la matrice di co-occorrenza. Costruisci una matrice di dimensione , dove è la dimensione del vocabolario. La cella contiene il numero di volte in cui la parola compare entro una finestra di parole dalla parola , conteggiato su un grande corpus. Ogni riga di è un vettore di dimensioni che rappresenta la parola tramite il suo profilo di vicinanze.
Il problema della matrice cruda: è enorme (un vocabolario di centomila parole produce una matrice da dieci miliardi di celle), è sparsa (la maggior parte delle celle è zero), e ogni dimensione corrisponde a una specifica parola del vocabolario, il che la rende ridondante. LSA risolve i tre problemi insieme con una decomposizione ai valori singolari: , dove e sono matrici ortogonali e è diagonale. Tronchi a dimensioni (tipicamente 200-500) e ottieni una rappresentazione densa: . Ogni parola è ora un vettore di numeri reali. La SVD ha la proprietà di concentrare l’informazione nelle prime componenti, quindi molto minore di conserva la maggior parte della struttura.
LSA funziona, ma ha tre limiti pratici. Primo: il costo. SVD su matrici di milioni di righe e colonne è computazionalmente proibitivo prima dell’arrivo di metodi randomizzati efficienti. Secondo: l’aggiornamento. Aggiungere nuovi documenti richiede ricalcolare la decomposizione. Terzo: l’unità di analisi. LSA usa di solito matrici termine-documento, non termine-contesto a finestra; la struttura locale del linguaggio si perde.
Bengio 2003: la prima rete che impara embeddings
Sezione intitolata “Bengio 2003: la prima rete che impara embeddings”Il Neural Probabilistic Language Model di Bengio et al. è la prima rete neurale che impara word embeddings come parte naturale del proprio processo di addestramento. L’architettura: prendi una finestra di parole precedenti, mappa ciascuna in un vettore di dimensione (questa è la matrice di embedding , di dimensione ), concatena gli vettori in un unico vettore di dimensione , passalo attraverso uno o due strati hidden con attivazione tanh, e produci in output un vettore di logit. Applica softmax per ottenere una distribuzione di probabilità sulla parola successiva.
La loss è la log-likelihood negativa della parola successiva osservata. Backpropagation aggiorna sia i pesi degli strati hidden e di output, sia la matrice di embedding . Dopo l’addestramento, le righe di sono i word embeddings: ogni riga è il vettore -dimensionale che rappresenta la parola corrispondente.
Bengio et al. dimostrano che il modello batte i tradizionali n-gram su perplexity, e che gli embedding catturano somiglianze semantiche. Il problema computazionale: il softmax finale costa per esempio, e con nell’ordine delle centinaia di migliaia diventa il collo di bottiglia. Bengio et al. lavorano con vocabolari di ~17000 parole e impiegano settimane per addestrare un modello.
Tra il 2003 e il 2013, una serie di paper cerca di rendere praticabile il modello di Bengio con varie strategie: hierarchical softmax (Morin-Bengio 2005), noise contrastive estimation (Mnih-Teh 2012), training importance sampling (Bengio-Senecal 2008). Ognuna riduce il costo del softmax ma mantiene l’architettura ricca con strati hidden non lineari. Mikolov 2013 rompe il pattern: mantiene i tagli di efficienza sul softmax (hierarchical o negative sampling) e in più’ rimuove gli strati hidden. La combinazione dei due tagli è quello che porta lo speedup di tre ordini di grandezza rispetto a Bengio 2003.
CBOW: il contesto predice la parola
Sezione intitolata “CBOW: il contesto predice la parola”L’architettura CBOW di word2vec semplifica drasticamente Bengio 2003 togliendo gli strati hidden non lineari. Resta solo: una matrice di embedding di dimensione per gli input, una matrice di dimensione per gli output, e in mezzo una somma (o media) dei vettori di contesto.
In pseudocodice:
# Input: una finestra di parole di contesto attorno alla target# Output: predire la parola target
context_words = [w_{t-c}, ..., w_{t-1}, w_{t+1}, ..., w_{t+c}]target_word = w_t
# 1. Lookup degli embedding dei contesticontext_vectors = [W[w] for w in context_words] # ciascuno è R^d
# 2. Media dei vettori di contestoh = mean(context_vectors) # h è R^d
# 3. Score per ogni parola del vocabolarioscores = W_prime.T @ h # scores è R^V
# 4. Softmax e cross-entropy con la targetprobs = softmax(scores)loss = -log(probs[target_word])Il modello ha parametri (le due matrici e ) ed è essenzialmente una regressione logistica multinomiale sopra un embedding mediato. Eliminate le non linearità, resta un modello quasi-lineare. Mikolov giustifica la scelta osservando che le non linearità di Bengio 2003 contribuiscono poco alla qualità degli embedding e molto al costo. Sacrificare un pò di accuratezza di language modeling per guadagnare tre ordini di grandezza in velocità di training rende possibile usare corpora di scala incomparabilmente maggiore. Su corpora abbastanza grandi, il modello “stupido” produce embedding migliori del modello “intelligente” addestrato su corpora piccoli.
Un dettaglio notevole: dopo il training, l’embedding di una parola è la riga corrispondente di , non di . Le due matrici giocano ruoli asimmetrici: è la rappresentazione della parola “come input” (come contesto), è la rappresentazione “come output” (come target). Si potrebbe usare o la media di e come embedding finale; la pratica standard è usare solo , e questa scelta empirica produce embedding leggermente migliori sui benchmark di analogia. La ragione precisa dell’asimmetria è tema di letteratura successiva (Press-Wolf 2017 propongono il weight tying che lega le due matrici nei language models, vedi embedding-input-output (in preparazione)). Per word2vec originale, resta la scelta canonica.

Skip-gram: la parola predice il contesto
Sezione intitolata “Skip-gram: la parola predice il contesto”Skip-gram inverte le frecce. La parola centrale è input, le parole di contesto sono i target separati. Per ogni coppia (target, contesto) il modello produce uno score e calcola una loss.
In pseudocodice:
# Input: una parola target# Output: predire ciascuna delle parole di contesto
target_word = w_tcontext_words = [w_{t-c}, ..., w_{t-1}, w_{t+1}, ..., w_{t+c}]
# 1. Lookup dell'embedding della targeth = W[target_word] # h è R^d
# 2. Per ogni parola di contesto, score e cross-entropyloss = 0for w_ctx in context_words: scores = W_prime.T @ h # scores è R^V probs = softmax(scores) loss += -log(probs[w_ctx])Skip-gram tratta ogni parola del contesto come un esempio di training indipendente. Per una finestra di parole, ogni occorrenza della target genera esempi. La struttura asimmetrica produce più segnale di addestramento per parola, e Mikolov osserva empiricamente che Skip-gram supera CBOW sulle parole rare: anche poche occorrenze di una parola rara generano molte coppie (parola_rara, contesto_frequente) che il modello sfrutta per piazzarla nello spazio.
Un dettaglio implementativo importante: la window size in word2vec è dinamica, non fissa. Per ogni occorrenza della parola target, l’algoritmo campiona uniformemente una window size effettiva tra 1 e . Risultato: le parole più’ vicine alla target ricevono peso maggiore (compaiono in più’ campioni), le parole più’ lontane peso minore. È un trucco che simula l’effetto di una decadenza con la distanza senza dover mantenere pesi espliciti, e si rivela importante per la qualità degli embedding finali.

Trick di efficienza 1: hierarchical softmax
Sezione intitolata “Trick di efficienza 1: hierarchical softmax”Anche con l’architettura semplificata, il softmax finale resta il collo di bottiglia: per ogni esempio, calcolare e poi normalizzare costa per vocabolari di milioni di parole. Mikolov prende dalla letteratura due alternative.
La prima è il hierarchical softmax, proposto originariamente da Frederic Morin e Yoshua Bengio nel 2005. Invece di trattare il vocabolario come una lista piatta di parole, lo organizzi in un albero binario di Huffman: parole frequenti vicino alla radice, parole rare lontane. Ogni parola è una foglia, raggiungibile da un cammino unico che parte dalla radice. Lungo il cammino, ad ogni nodo interno ci sono due rami; il modello associa a ogni nodo interno un vettore di dimensione e calcola la probabilità di andare a sinistra come , dove è la sigmoide.
La probabilità di una parola è il prodotto delle probabilità delle scelte lungo il cammino. Per un vocabolario di parole, il cammino medio ha lunghezza . Per , : si passa da un milione di prodotti scalari a venti. La struttura di Huffman favorisce ulteriormente le parole frequenti, che hanno cammini più corti.

Trick di efficienza 2: negative sampling
Sezione intitolata “Trick di efficienza 2: negative sampling”La seconda alternativa, e quella che diventa lo standard de facto nei due anni successivi, è il negative sampling. L’idea viene da Noise Contrastive Estimation (NCE) di Michael Gutmann e Aapo Hyvarinen (2010), semplificata da Mikolov per word2vec.
Riformuli il problema così’: invece di chiedere “qual è la probabilità della parola di contesto dato il target , normalizzata su tutto il vocabolario?”, chiedi “questa coppia è una vera co-occorrenza osservata nel corpus, oppure una coppia inventata?”. È una classificazione binaria. Per ogni esempio positivo visto nel corpus, campiona esempi negativi dove è estratta da una distribuzione di rumore. Allena un classificatore binario a distinguere positivi da negativi.
In pseudocodice:
# Per ogni coppia positiva osservata:positive_pair = (target, context)negative_pairs = [(target, sample_from_noise()) for _ in range(k)]
# Loss binaria con sigmoide:loss = -log(sigmoid(W'[context].T @ W[target]))for (t, neg) in negative_pairs: loss += -log(sigmoid(-W'[neg].T @ W[t]))Per ogni esempio di training si aggiornano solo vettori di output, non . Mikolov suggerisce a per dataset piccoli e a per dataset grandi. La distribuzione di rumore funziona meglio con la frequenza unigramma elevata alla : non uniforme (penalizza troppo le parole comuni), non proporzionale (non dà abbastanza segnale alle rare). Il taglio empirico è uno dei tanti dettagli che fanno la differenza in pratica.
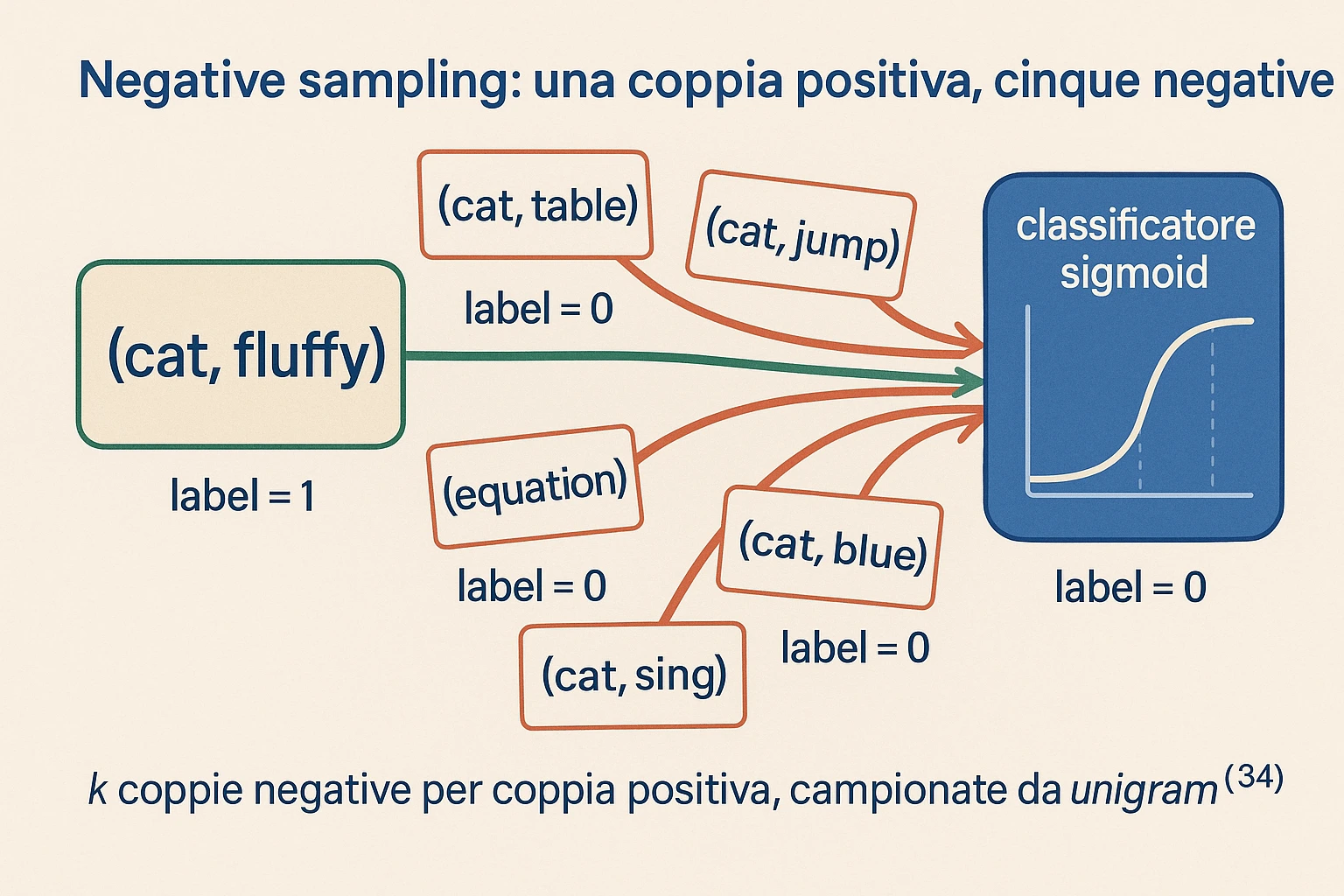
Trick di efficienza 3: subsampling delle parole frequenti
Sezione intitolata “Trick di efficienza 3: subsampling delle parole frequenti”Parole come the, of, and, a in inglese ricorrono con frequenze ordini di grandezza superiori al resto del vocabolario. Trattarle come tutte le altre durante il training significa spendere una quota enorme di iterazioni su pattern poco informativi. Mikolov introduce il subsampling: ogni occorrenza di una parola viene scartata con probabilità
dove è la frequenza relativa di nel corpus e è una soglia (Mikolov usa ). Parole più rare di vengono mantenute sempre; parole molto più frequenti di vengono scartate aggressivamente. Effetti collaterali: training più veloce (meno occorrenze da processare), embedding migliori per parole intermedie (le rappresentazioni di “Parigi” non vengono “tirate” in continuazione verso “the” e “is”).
Trick di efficienza 4: SGD asincrono multi-thread
Sezione intitolata “Trick di efficienza 4: SGD asincrono multi-thread”L’ultimo dettaglio implementativo che fa la differenza è meno teoricamente vistoso ma altrettanto importante. Word2vec usa Hogwild! (Niu, Recht, Re, Wright, NIPS 2011), uno schema di SGD parallelo senza lock: più’ thread leggono e scrivono concorrentemente sulle stesse matrici di pesi senza sincronizzazione esplicita. La giustificazione: gli aggiornamenti tipici toccano vettori sparsi (un embedding alla volta), le collisioni sono rare, e il rumore introdotto dalle race condition occasionali è piccolo rispetto al rumore intrinseco di SGD. Risultato: speedup quasi lineare nel numero di core. Su una macchina con 16-32 core, word2vec sfrutta tutto il parallelismo disponibile senza riscrivere l’algoritmo per architetture distribuite.
Le analogie vettoriali: la sorpresa che rende word2vec virale
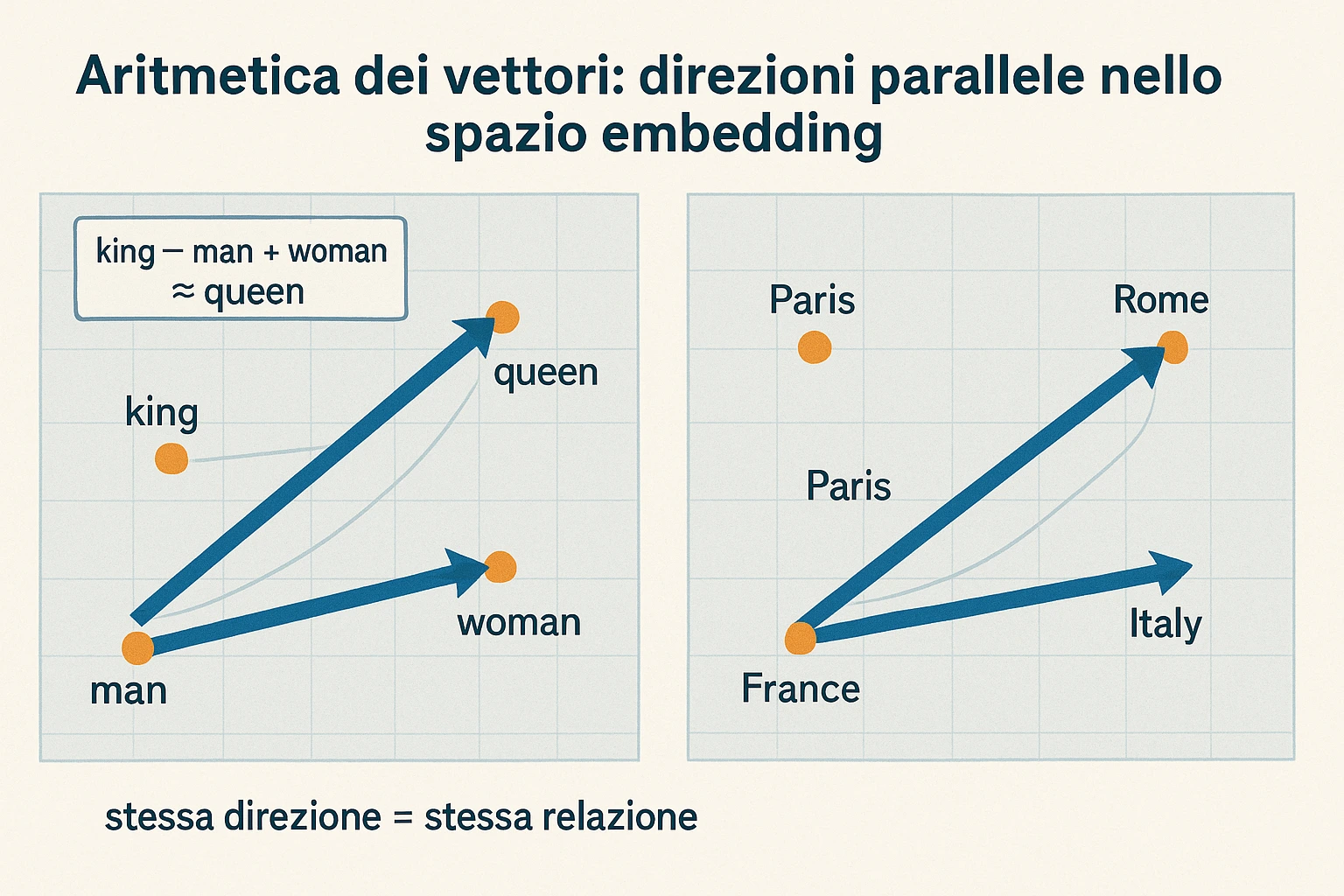
Sezione intitolata “Le analogie vettoriali: la sorpresa che rende word2vec virale”La parte della ricerca che fa esplodere word2vec nel dibattito divulgativo non è la performance sui benchmark di language modeling. È un’osservazione apparentemente magica. Prendi i vettori di king, man, woman, queen. Calcola
e cerca la parola del vocabolario il cui vettore è più vicino al risultato (distanza coseno). Spesso, su modelli word2vec ben addestrati, la risposta è queen. Lo stesso vale per molte analogie:
Mikolov costruisce un dataset standard di analogie (~19000 esempi divisi in categorie semantiche e sintattiche: capitali e paesi, valuta e paese, generi grammaticali, comparativi, superlativi, tempi verbali) e mostra che word2vec raggiunge accuratezze del 50-70%, contro il <10% dei baseline LSA e il ~20% dei modelli neurali precedenti. Il salto è netto.
Cosa significa “vettori sui generi formano direzioni coerenti”? Significa che la differenza è approssimativamente uguale alla differenza ed è approssimativamente uguale a e così’ via. Esiste, nello spazio degli embedding, una direzione che corrisponde al genere maschile-femminile, ortogonale (o quasi) alla direzione che corrisponde al ruolo (re-attore-bambino vs cuoco-pittore-medico). Lo spazio degli embedding non è una nuvola amorfa di vettori: ha direzioni interpretabili.
L’esempio king-man+woman=queen diventa virale nei mesi successivi alla pubblicazione. Compare in talk, in articoli divulgativi su MIT Technology Review e Wired, in keynote di conferenze, in slide di corporate presentation. Ha tre qualità che lo rendono perfetto per la divulgazione: è immediatamente comprensibile (chiunque sa cosa sono re, regina, uomo, donna), è algebricamente elegante (una somma e una sottrazione), e dà l’impressione che il modello “capisca” qualcosa di profondo. La terza qualità è, come vedremo, la più’ problematica: è anche fonte dei più’ grandi malintesi pubblici su cosa facciano davvero gli embedding.
Phrases: oltre le parole singole
Sezione intitolata “Phrases: oltre le parole singole”Il paper NIPS 2013 introduce anche un trattamento delle frasi multi-parola (phrases): unità come “New York”, “United States”, “machine learning” che compaiono insieme con frequenza molto più alta di quanto suggerirebbe la frequenza delle singole parole. Mikolov propone un metodo statistico semplice basato sulla pointwise mutual information:
dove è una soglia di smoothing che evita di considerare bigrammi raramente osservati. Bigrammi con score sopra una soglia vengono fusi in un singolo token (new_york, machine_learning) e poi trattati come parole regolari. Iterando il processo (run multipli che fondono bigrammi, poi trigrammi, eccetera), si ottengono entità multi-parola con embedding propri. Risultato: . La compositionality si estende dal livello morfo-sintattico a quello delle entità nominate.
La scala dell’esperimento
Sezione intitolata “La scala dell’esperimento”I numeri dell’esperimento principale del paper NIPS 2013 fissano l’ordine di grandezza. Corpus: Google News, ~6 miliardi di token, vocabolario filtrato a ~700000 parole (le parole con frequenza inferiore a una soglia vengono scartate). Dimensione embedding: 300, scelta empiricamente come buon compromesso tra qualità e costo. Window size: 5 o 10 a seconda dell’esperimento. Numero di negativi: 5-15. Tempo di training: circa un giorno su una macchina con qualche decina di core CPU. Nessuna GPU.
Il modello pre-addestrato sui 100 miliardi di token di Google News (versione estesa rispetto al paper) viene rilasciato pubblicamente da Mikolov insieme al codice C originale (word2vec.c, ~700 righe). Diventa immediatamente uno standard di facto: chiunque voglia inizializzare gli embedding di un sistema NLP scarica i vettori pre-trained di Google News e li usa come punto di partenza. La distribuzione gratuita di codice e modello è un fattore decisivo della popolarizzazione: per la prima volta nel NLP, un risultato di Google è direttamente riusabile senza riaddestrarlo.
Cronologia compatta del 2013
Sezione intitolata “Cronologia compatta del 2013”Per fissare le date, conviene una micro-cronologia degli eventi del 2013 attorno a word2vec.
- 16 gennaio 2013: prima versione del paper “Efficient Estimation of Word Representations in Vector Space” su arXiv (1301.3781). Mikolov, Chen, Corrado, Dean. Il paper introduce CBOW e Skip-gram con softmax pieno e con hierarchical softmax.
- Aprile-maggio 2013: codice C
word2vec.crilasciato pubblicamente su Google Code (poi migrato su GitHub). Incluso script per scaricare modelli pre-trained. - Maggio 2013: workshop ICLR a Scottsdale, Arizona. Presentazione del paper. Reazioni miste: la comunità di NLP non riconosce immediatamente la portata del lavoro.
- Estate 2013: i vettori pre-trained su Google News (100 miliardi di token, 300 dimensioni) vengono distribuiti pubblicamente. Adozione virale tra ricercatori e industria.
- 17 ottobre 2013: secondo paper su arXiv (1310.4546) “Distributed Representations of Words and Phrases and their Compositionality”. Mikolov, Sutskever, Chen, Corrado, Dean. Aggiunge negative sampling, subsampling, phrases.
- Dicembre 2013: NIPS a Lake Tahoe. Presentazione del secondo paper. Questa volta la comunità coglie la portata: word2vec diventa il termine standard.
Tra gennaio e dicembre 2013, in meno di un anno, il filone passa da paper di workshop a tecnologia adottata in produzione in decine di aziende.
Il codice C originale è istruttivo da leggere. Mikolov scrive un singolo file di poche centinaia di righe che implementa lettura del corpus, costruzione del vocabolario, costruzione dell’albero di Huffman per hierarchical softmax, generazione di campioni negativi, training multi-thread con SGD asincrono. Niente framework di alto livello, niente librerie esotiche: math.h, pthread, malloc. La filosofia ricorda quella di Krizhevsky che scriveva CUDA a mano per AlexNet: in un’epoca in cui PyTorch e TensorFlow non esistono ancora (TensorFlow uscirà a novembre 2015), chi vuole spingere lo state of the art deve scrivere codice di sistema. La leggibilità di word2vec.c ha contribuito alla diffusione: ricercatori di tutto il mondo lo hanno letto, riprodotto, portato in altri linguaggi (Python via gensim di Radim Rehurek, Java via deeplearning4j, Spark MLlib). Una conseguenza non banale è la rapida convergenza di un’intera comunità su una API mentale comune: training su corpora di testo, parametri tipici, output come matrice .
Cinque esempi concreti, di natura eterogenea: uno numerico, uno in pseudocodice, uno di visualizzazione, uno di recupero, uno di applicazione downstream.
Esempio 1: generazione delle coppie skip-gram da una frase
Sezione intitolata “Esempio 1: generazione delle coppie skip-gram da una frase”Considera la frase: “the quick brown fox jumps over the lazy dog”. Window size (due parole a sinistra, due a destra). Per ogni parola della frase generi le coppie (target, contesto):
target=the, contesto={quick, brown}target=quick, contesto={the, brown, fox}target=brown, contesto={the, quick, fox, jumps}target=fox, contesto={quick, brown, jumps, over}target=jumps, contesto={brown, fox, over, the}target=over, contesto={fox, jumps, the, lazy}target=the, contesto={jumps, over, lazy, dog}target=lazy, contesto={over, the, dog}target=dog, contesto={the, lazy}Espandendo ogni target nella sua lista di coppie (target, parola_di_contesto) singole, ottieni 30 esempi positivi di training da una sola frase di nove parole. Su un corpus da sei miliardi di token, il numero totale di esempi positivi supera le decine di miliardi: ogni esempio costa pochi prodotti scalari grazie a negative sampling, e il training resta gestibile.
Esempio 2: calcolo dell’analogia in pseudocodice
Sezione intitolata “Esempio 2: calcolo dell’analogia in pseudocodice”Dato un word2vec già’ addestrato e disponibile come dizionario embeddings[word] -> vector, l’analogia king-man+woman si calcola così’:
import numpy as np
def cosine_similarity(a, b): return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def find_analogy(a, b, c, embeddings, top_k=5, exclude=None): # Vogliamo trovare d tale che a - b + c ~= d target = embeddings[a] - embeddings[b] + embeddings[c]
# Escludi le parole di input dal candidate set: # senza questa esclusione la risposta più vicina è # spesso una delle parole di input stessa. if exclude is None: exclude = {a, b, c}
scores = [] for word, vec in embeddings.items(): if word in exclude: continue scores.append((word, cosine_similarity(target, vec)))
return sorted(scores, key=lambda x: -x[1])[:top_k]
# Esempio:result = find_analogy("king", "man", "woman", embeddings)# Tipicamente result[0] = ("queen", 0.71)Da notare il dettaglio dell’esclusione: senza filtrare le parole di input, il candidato più vicino al vettore è spesso king o woman stesse. La pratica standard nel testing delle analogie è escluderle. Questo dettaglio diventerà il centro della critica di Linzen 2016 che vedremo più avanti.
Esempio 3: cluster di paesi e capitali
Sezione intitolata “Esempio 3: cluster di paesi e capitali”Un esperimento di visualizzazione spesso ripetuto su word2vec pre-trained: prendi i vettori di una decina di paesi (Italia, Francia, Germania, Spagna, Russia, Giappone, Cina, Brasile, Egitto, India) e delle loro capitali (Roma, Parigi, Berlino, Madrid, Mosca, Tokyo, Pechino, Brasilia, Cairo, Nuova Delhi). Proietta i vettori 300-dimensionali in 2D usando PCA o t-SNE.
Il risultato che si osserva: i paesi formano un cluster, le capitali formano un altro cluster, e — questa è la parte sorprendente — ogni capitale è approssimativamente alla stessa distanza e nella stessa direzione dal proprio paese. Disegnando le frecce paese -> capitale, ottieni un fascio di vettori quasi paralleli. La direzione “paese-capitale” è codificata nello spazio degli embedding come una traslazione coerente.
Stessa osservazione, su scala diversa, vale per coppie infinito-participio (walk-walked, swim-swam, eat-ate), singolare-plurale (cat-cats, child-children), positivo-comparativo (big-bigger, small-smaller). Lo spazio non è isotropo: è attraversato da direzioni che corrispondono a relazioni semantiche o morfologiche specifiche.
Esempio 4: similarità coseno per recupero di parole simili
Sezione intitolata “Esempio 4: similarità coseno per recupero di parole simili”Un uso operativo immediato di word2vec, indipendente dalle analogie, è il recupero delle parole semanticamente più vicine a una data. Su un word2vec pre-trained di Google News, le 5 parole più vicine a Italy sono tipicamente: Spain (cosine ~0.71), Portugal (~0.69), Greece (~0.66), Italian (~0.65), Sicily (~0.62). Le 5 più vicine a Java dipendono da quale senso domina nel corpus: su Google News domina il linguaggio di programmazione, e si vede Python (~0.75), Ruby (~0.71), PHP (~0.69), Perl (~0.66), Scala (~0.61). La parola Java come isola indonesiana resta sotto la soglia. La polisemia collassa nel senso dominante del corpus di training: questa è una manifestazione concreta del limite “static embeddings” che vedremo nella sezione “Dove si rompe”.
Le cifre di similarità qui vanno lette come illustrative: ciò che conta è la struttura del vicinato semantico, non il secondo decimale.
Esempio 5: classificatore di sentiment con embedding pre-trained
Sezione intitolata “Esempio 5: classificatore di sentiment con embedding pre-trained”Un caso d’uso classico tra 2014 e 2017: classificare la polarità di una recensione (positiva/negativa). Pipeline: per ogni recensione, calcoli la media dei vettori word2vec delle parole che la compongono (un singolo vettore di 300 dimensioni per recensione), poi addestri un classificatore lineare (regressione logistica o SVM lineare) sopra il vettore mediato. Su benchmark come IMDB Movie Reviews o Yelp Reviews Polarity, questo baseline raggiunge accuratezze del 85-90% con poche righe di codice e training di pochi minuti su CPU. Sostituire la media con TF-IDF weighted average migliora marginalmente; sostituirla con embedding addestrati end-to-end dal task migliora di un altro paio di punti. Il salto vero arriva solo con architetture sequenziali (LSTM con attention) o transformer-based, ma il rapporto qualità/costo del baseline word2vec resta competitivo per anni.

Eredità oggi
Sezione intitolata “Eredità oggi”[DATATO 2026-04] La sezione che segue commenta lo stato di adozione e di superamento di word2vec a circa tredici anni dal paper originale. Il quadro generale è stabile, ma le percentuali di adozione e i nomi dei modelli dominanti cambiano frequentemente.
Word2vec ha segnato il punto di partenza di una linea di ricerca che, in poco più di un decennio, ha riscritto l’NLP. Le tappe principali della filiazione sono tre.
GloVe (Global Vectors for Word Representation), di Jeffrey Pennington, Richard Socher e Christopher Manning, pubblicato a EMNLP 2014, propone un’alternativa a word2vec che combina vantaggi di entrambi i mondi: la statistica globale di co-occorrenza di LSA (matrice termine-contesto, log-bilineare) e l’efficienza locale di word2vec (training online, scalabile). GloVe e word2vec producono embedding di qualità comparabile su benchmark standard; la scelta tra l’uno e l’altro nei progetti tra 2014 e 2017 è spesso una questione di preferenza dell’autore o di disponibilità dei vettori pre-trained. Glove rilascia vettori pre-trained su Common Crawl (~840 miliardi di token) che diventano un’alternativa o complemento ai vettori Google News di Mikolov.
fastText, sviluppato a Facebook AI Research (Mikolov stesso, dopo essere passato da Google a FAIR nel 2014, con Piotr Bojanowski, Edouard Grave e Armand Joulin, paper TACL 2017 “Enriching Word Vectors with Subword Information”), estende word2vec con una rappresentazione subword: ogni parola è rappresentata come somma dei vettori dei suoi n-grammi di caratteri. La parola playing viene scomposta in <pl, pla, lay, ayi, yin, ing, ng>. Conseguenza: parole out-of-vocabulary che non sono mai state viste durante il training ricevono comunque un embedding (somma degli n-gram presenti); la morfologia (suffissi -ing, -ed, -tion) viene catturata; le lingue morfologicamente ricche (turco, finlandese, ungherese) beneficiano enormemente.
Contextual embeddings: ELMo (Peters et al., NAACL 2018), BERT (Devlin et al., NAACL 2019), GPT (Radford et al., 2018-2019). Qui si rompe il principio “una parola, un vettore”. Una parola in un contesto specifico produce un vettore che dipende dalle parole intorno. Bank in river bank e bank in bank account hanno vettori diversi. Il problema della polisemia che word2vec non risolveva trova qui una risposta. I contextual embeddings dipendono però da architetture transformer pesanti (vedi transformer-2017 (in preparazione)), e ribaltano l’economia rispetto a word2vec: addestramento costoso, inferenza costosa, ma qualità molto superiore su task downstream.
Tra word2vec e i contextual embeddings c’è una generazione intermedia che vale la pena nominare. doc2vec o Paragraph Vector (Quoc Le e Tomas Mikolov, ICML 2014) estende word2vec per produrre vettori di paragrafi e documenti interi: il paragraph è trattato come un “token speciale” il cui vettore viene appreso insieme a quelli delle parole, in modo che catturi la specificità del paragrafo che gli altri token non catturano. Sent2Vec, InferSent, Universal Sentence Encoder, SBERT (Sentence-BERT, Reimers-Gurevych 2019) sono varianti successive che producono embedding di frase usando architetture progressivamente più sofisticate. La continuità con word2vec è netta: l’idea di base resta “una stringa, un vettore denso, distanza tra vettori = distanza semantica”. Quello che cambia è il tipo di stringa e il modo in cui il vettore viene prodotto.
Filiazione documentata: la embedding matrix dei transformer eredita direttamente l’idea di word2vec: ogni token (sotto-parola, dopo BPE o SentencePiece) ha un vettore denso appreso end-to-end. L’embedding è il primo strato della rete; ogni strato successivo lo trasforma in funzione del contesto. Quello che cambia è che il vettore non resta statico dopo il lookup: viene aggiornato strato per strato. Ma la matrice di embedding di GPT-3, Llama, Claude è la pronipote diretta della matrice di Mikolov 2013. Vedi embedding-input-output (in preparazione) per la trattazione tecnica nei LLM moderni.
Word2vec resta usato in nicchie specifiche dove la semplicità batte la sofisticazione. Recommendation systems: item2vec (Barkan-Koenigstein 2016) tratta sequenze di acquisti come “frasi” in cui ogni prodotto è una “parola”, e impara embedding di prodotti che catturano somiglianze d’uso. Spotify, Yahoo, Netflix usano varianti di questa idea. Knowledge graph embeddings: node2vec (Grover-Leskovec 2016) e DeepWalk (Perozzi-Al-Rfou-Skiena 2014) generano “frasi” facendo random walk su grafi, poi applicano word2vec sulle sequenze. Bioinformatica: prot2vec, gene2vec applicano word2vec a sequenze biologiche. La struttura algoritmica è la stessa: trasforma il dominio in sequenze, applica skip-gram, ottieni embedding.
Vedi embeddings-retrieval (in preparazione) per il ruolo degli embedding nei sistemi di retrieval moderni (RAG), dove i vettori prodotti da modelli di embedding addestrati su scala — discendenti diretti dell’idea di word2vec — sono il sostrato per la ricerca semantica.
Applicazioni pratiche
Sezione intitolata “Applicazioni pratiche”Anche dieci anni dopo la sua pubblicazione, ci sono scenari in cui word2vec resta la scelta giusta, non un’eredità nostalgica. Tre situazioni concrete in cui un praticante può’ incontrarlo nel lavoro quotidiano.
Inizializzazione di sistemi NLP leggeri. Quando il vincolo è inferenza su CPU, latenza minima, modello distribuibile in pochi MB, un classificatore lineare sopra embedding word2vec o fastText pre-trained batte spesso architetture transformer per costo unitario. Sistemi di classificazione di intent in chatbot di prima generazione, filtri di spam, classificatori di lingua, taggers di topic per news: in tutti questi casi il rapporto qualità/costo di word2vec è competitivo. Non è lo stato dell’arte assoluto, ma è lo stato dell’arte vincolato.
Embedding per dati non testuali. Ogni volta che hai sequenze in un dominio (acquisti, click, sessioni di navigazione, percorsi su grafo, sequenze di chiamate API), puoi applicare l’algoritmo word2vec sostituendo “parole” con il tuo tipo di token. L’output è uno spazio vettoriale in cui token che appaiono in contesti simili hanno vettori vicini. È un trucco potente per feature engineering quando non hai etichette ma hai sequenze.
Baseline di confronto in ricerca e produzione. Prima di investire in un modello di embedding sofisticato per un nuovo task, tirare su una baseline word2vec/fastText e misurare è una pratica sana. Spesso la baseline copre l’80% del valore con il 5% del costo, e il modello sofisticato deve giustificare il delta. Senza la baseline, è difficile capire se la complessità aggiunta sta producendo valore reale.
In tutti e tre i casi, la lezione operativa è la stessa: la sofisticazione dei modelli moderni non rende automaticamente obsoleti i metodi precedenti. Per un’ampia fascia di task con vincoli di costo, latenza, o quantità di dati, word2vec è ancora la risposta corretta.
Dove si rompe
Sezione intitolata “Dove si rompe”Static embeddings e polisemia. Una parola, un vettore. La parola bank (sponda di fiume vs istituto finanziario) collassa in un unico embedding che è una sorta di media dei due significati. Per task in cui il contesto disambigua, la perdita è significativa: un classificatore che usa solo non può’ sapere quale dei due sensi sia attivo. Il problema diventa centrale quanto più si vuole risolvere task fini (word sense disambiguation, question answering preciso, information extraction). I contextual embeddings risolvono il problema, ma a costo di dover passare l’intera frase attraverso un transformer per ogni inferenza.
Out-of-vocabulary. Una parola mai vista in training non ha embedding. Non c’è fallback elegante: o ignori la parola, o la mappi a un token speciale <UNK> che perde tutta l’informazione. Il problema è particolarmente grave per i nomi propri, neologismi, lingue diverse. fastText e i tokenizer subword (BPE di Sennrich et al. 2016, SentencePiece di Kudo 2018) risolvono il problema garantendo che ogni stringa sia decomposta in unità note.
Bias del corpus. Se i corpora di training riflettono stereotipi sociali, gli embedding li ereditano. Il paper di Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama e Adam Kalai “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings” (NIPS 2016) dimostra in modo sistematico che gli embedding word2vec addestrati su Google News producono analogie come man:computer_programmer :: woman:homemaker e father:doctor :: mother:nurse. Il bias non è un artefatto isolato: è diffuso e misurabile. Il paper propone tecniche di debiasing post-hoc che rimuovono la componente di una direzione “genere” dai vettori delle parole occupazionali. Le tecniche funzionano in parte ma sono criticate da lavori successivi (Gonen-Goldberg 2019) che mostrano come il bias resti latente nella struttura geometrica dei vettori, non veramente rimosso. La discussione è aperta e tocca questioni più generali sui bias dei modelli (vedi etica-deontologica-ai (in preparazione), red-teaming (in preparazione)).
Una conseguenza pratica: gli embedding non sono “neutri” e non vanno mai usati in pipeline ad alto stake (selezione del personale, valutazione del credito, decisioni mediche) senza una valutazione esplicita dei bias che trasportano. La portabilità che ha reso word2vec popolare — scarico il modello, lo applico al mio task — è anche il vettore principale di propagazione di bias da un dominio all’altro. La community accademica ha imparato la lezione tra 2016 e 2018, l’industria con più’ lentezza, e oggi (2026) il tema è codificato in normative come l’EU AI Act (vedi eu-ai-act (in preparazione)).
Le analogie sono più fragili di quanto sembri. Tal Linzen (linguista computazionale, allora a Johns Hopkins, ora a NYU) pubblica nel 2016 al RepEval Workshop “Issues in Evaluating Semantic Spaces Using Word Analogies”, che dimostra un punto scomodo. Quando si calcola l’analogia king-man+woman e si cerca il vettore più vicino al risultato, il candidato più vicino è frequentemente una delle parole di input stesse (king, woman). Il protocollo standard di valutazione le esclude esplicitamente dal candidate set. Linzen mostra che senza l’esclusione, l’accuratezza crolla drasticamente, e che l’esclusione fa la maggior parte del lavoro. Anche varianti che semplicemente prendono il vettore più vicino a (senza neppure usare king e man) raggiungono accuratezze sorprendentemente alte sul dataset di Mikolov. Anna Schluter (RepEval 2018) e altri estendono la critica.
L’interpretazione: la “vector compositionality” celebrata nel 2013 è parzialmente un artefatto del protocollo di valutazione. Esiste una struttura geometrica reale che cattura relazioni come genere o capitalità, ma il salto da “esiste struttura” a “il modello fa ragionamento analogico” è eccessivo. Le analogie sono una proprietà degli embedding, non una capacità del modello.
Una critica correlata: il dataset di analogie di Mikolov contiene categorie facili (capitali di paesi grandi, generi grammaticali in inglese) ma poche categorie difficili. Su categorie meno frequenti nel corpus (capitali di paesi piccoli, parole tecniche, relazioni concettuali astratte) le accuratezze crollano. Il “70%” globale celebrato è una media che nasconde un’enorme variabilità. Per relazioni che richiedono conoscenza del mondo poco rappresentata nel corpus, gli embedding non hanno modo di catturarla.
Mito della precisione algebrica. Il modo in cui le analogie vengono raccontate nei talk divulgativi suggerisce un’eguaglianza esatta: . La verità è più’ modesta: il risultato è un vettore, e queen è la parola del vocabolario il cui vettore ha similarità coseno più alta col risultato (dopo aver escluso king, man, woman). La similarità tipica è nell’ordine di 0.7, non 1.0. Su molte analogie, soprattutto quelle meno frequenti nel corpus di training, la risposta corretta non è nemmeno tra i primi cinque candidati.
Window size e simmetria. Word2vec tratta tutte le parole nella finestra come equivalenti, indipendentemente dalla distanza dalla target e dalla loro posizione sintattica. Una window troppo piccola perde relazioni a lunga distanza (soggetto-verbo separati da subordinate); una window troppo grande mescola contesti tematici eterogenei e produce embedding che catturano “argomento generale” piuttosto che “significato preciso”. La scelta della window è un iperparametro delicato. Modelli successivi che usano attention (vedi attention-bahdanau-2014 (in preparazione)) abbandonano l’idea di finestra fissa.
Una conseguenza della symmetric window: la struttura sintattica del linguaggio (chi è soggetto, chi è oggetto, ordine delle parole) viene in larga misura ignorata. Word2vec produce embedding che sono buoni per la “similarità tematica” e per relazioni paradigmatiche (sinonimi, iperonimi, classi semantiche) ma deboli per relazioni sintagmatiche (chi fa cosa a chi). Lavori come dependency-based word embeddings (Levy-Goldberg 2014) propongono di sostituire la window lineare con un contesto sintattico (parole connesse dalla dependency parse) e mostrano che gli embedding risultanti hanno proprietà diverse: più’ funzionali, meno tematici. Il messaggio: la scelta del “contesto” non è neutra, definisce cosa il modello impara a rappresentare.
Composizionalità delle frasi. Word2vec produce embedding di parole, non di frasi. Mediare gli embedding delle parole di una frase è un baseline povero: “il cane morde l’uomo” e “l’uomo morde il cane” producono lo stesso vettore (la media commuta). Il problema della composizionalità a livello di frase è aperto nel 2013 e porterà a paragraph2vec / doc2vec (Le-Mikolov 2014), poi a sentence transformers, poi ai contextual embeddings completi. Resta una verità generale: per task in cui l’ordine delle parole conta (parsing, traduzione, question answering preciso), gli embedding di parole isolate non bastano, servono modelli sequenziali sopra di essi.
Stabilità del training. Embedding diversi addestrati con seed diversi sullo stesso corpus producono spazi che non sono identici: la struttura globale (cluster, direzioni semantiche) è stabile, ma i vettori individuali ruotano e scalano. Confrontare embedding di due training distinti richiede di allineare gli spazi (procedure come Procrustes alignment, che trova la rotazione ortogonale ottimale tra due insiemi di punti). Questo limita gli usi che richiedono identità esatta dei vettori e complica gli studi diacronici (confrontare embedding addestrati su corpora di anni diversi per misurare semantic shift; vedi il lavoro di Hamilton-Leskovec-Jurafsky 2016 “Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change”).
Trasparenza interpretativa. Le 300 dimensioni di un embedding word2vec non sono interpretabili una per una. Non c’è una dimensione “genere”, una dimensione “concretezza”, una dimensione “valenza emotiva”. Le direzioni interpretabili (genere, capitalità, tempo verbale) sono combinazioni lineari delle 300 dimensioni grezze, ed emergono solo cercandole esplicitamente. Il modello non offre un’introspezione naturale sulla sua propria rappresentazione; chi vuole capire “cosa codifica” un vettore deve fare probing classifiers a posteriori. Il problema è generale del deep learning e diventa centrale nell’agenda di mechanistic interpretability più tardi.
Dipendenza dalla qualità del corpus. Word2vec è bravo quanto il corpus che gli dai. Se il corpus è rumoroso (forum a bassa qualità, traduzioni automatiche di basso livello, OCR errato di documenti antichi), gli embedding ereditano il rumore. Se il corpus è troppo specialistico (solo abstract di paper di fisica), gli embedding sono ottimi nel dominio ma inservibili fuori. Se il corpus copre una sola lingua, gli embedding non sono trasferibili a un’altra senza tecniche di allineamento cross-lingua. La scelta del corpus è una scelta di policy del modello, non un dettaglio implementativo. Per Mikolov 2013 il corpus Google News è un compromesso: grande, vario, in inglese standard. Per altri usi serve altro.
Collegamenti
Sezione intitolata “Collegamenti”- imagenet-alexnet-2012: paradigma parallelo sull’altro lato della frontiera percettiva. AlexNet su vision a settembre 2012, word2vec su NLP a gennaio 2013. Lo stesso messaggio (rappresentazioni apprese end-to-end battono feature engineering) attraverso due benchmark indipendenti.
- reti-neurali-80-90: il filone neurale che esplode anche nel NLP. In particolare, il paper Bengio 2003 sul Neural Probabilistic Language Model è il diretto antenato di word2vec.
- svm-era-2000: il paradigma feature-engineering + SVM che word2vec e i suoi successori soppiantano nel NLP. Stesso pattern visto in vision con AlexNet, due anni dopo.
- storia-sintesi: contesto generale della rivoluzione 2012-2015.
seq2seq-2014(in preparazione): l’architettura encoder-decoder per traduzione automatica, che usa embedding word2vec-like come primo strato e dimostra che si possono apprendere mappings tra sequenze intere.attention-bahdanau-2014(in preparazione): meccanismo di attention che permette al decoder di “guardare” tutte le posizioni dell’encoder. Supera la window fissa di word2vec con un meccanismo dinamico.transformer-2017(in preparazione): l’architettura che combina embedding densi (eredi di word2vec), attention multi-head e feed-forward, e che diventa la base di tutti i modelli linguistici moderni.bert-gpt-2018-2019(in preparazione): contextual embeddings. Una parola in un contesto specifico produce un vettore specifico. Risposta al limite della polisemia di word2vec.representation-learning(in preparazione): la teoria generale di apprendimento di rappresentazioni utili, di cui word2vec è un esempio canonico.self-supervised(in preparazione): word2vec è uno dei primi successi di self-supervised learning su testo. Il segnale di addestramento (predire il contesto) viene dal testo stesso, senza annotazioni umane.embedding-input-output(in preparazione): trattazione tecnica della embedding matrix nei LLM moderni, eredità diretta di word2vec.tokenizzazione-intro(in preparazione): come si segmenta il testo prima di applicare embedding. BPE e SentencePiece risolvono i problemi OOV che word2vec non gestiva.embeddings-retrieval(in preparazione): uso degli embedding nei sistemi di retrieval (RAG). Discendenti diretti dell’idea di word2vec, ora addestrati su scala con architetture transformer.
Per andare oltre
Sezione intitolata “Per andare oltre”- Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, “Efficient Estimation of Word Representations in Vector Space”, arXiv:1301.3781, ICLR Workshop 2013. https://arxiv.org/abs/1301.3781 — il paper che introduce CBOW e Skip-gram. Tredici pagine, leggibile in un’ora. Da leggere come prima fonte primaria.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean, “Distributed Representations of Words and Phrases and their Compositionality”, NIPS 2013. https://papers.nips.cc/paper/2013/hash/9aa42b31882ec039965f3c4923ce901b-Abstract.html — il paper che introduce negative sampling, hierarchical softmax efficiente e subsampling. Estensione tecnica del precedente.
- Yoshua Bengio, Rejean Ducharme, Pascal Vincent, Christian Jauvin, “A Neural Probabilistic Language Model”, Journal of Machine Learning Research, 2003. https://www.jmlr.org/papers/v3/bengio03a.html — l’antenato neurale diretto di word2vec, con architettura più’ ricca ma più’ costosa.
- Jeffrey Pennington, Richard Socher, Christopher D. Manning, “GloVe: Global Vectors for Word Representation”, EMNLP 2014. https://nlp.stanford.edu/pubs/glove.pdf — l’alternativa a word2vec, con fondamento basato su statistiche globali di co-occorrenza.
- Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, Adam Kalai, “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings”, NIPS 2016. https://arxiv.org/abs/1607.06520 — la critica dei bias degli embedding e una proposta (parziale) di debiasing.
- Tal Linzen, “Issues in Evaluating Semantic Spaces Using Word Analogies”, RepEval Workshop ACL 2016. https://aclanthology.org/W16-2503/ — la critica metodologica al protocollo di valutazione delle analogie.