Percezione come inferenza bayesiana
La percezione non è registrazione. È inferenza guidata da priors: il sistema visivo prende dati ambigui e impoveriti dai sensi, li combina con assunzioni implicite sul mondo, e produce un percetto coerente. Helmholtz lo intuisce nel 1867 chiamandolo “unbewusster Schluss” — inferenza inconscia. Gestaltpsychologie nel 1912 lo formalizza in leggi di organizzazione. Bruner-Goodman 1947 mostra che valore e bisogno modulano il percetto. Knill-Richards 1996 lo formalizza in linguaggio bayesiano — likelihood × prior → posterior. Rao-Ballard 1999 e Friston 2010 lo generalizzano in predictive coding gerarchico. Le illusioni — Müller-Lyer, Kanizsa, Adelson, hollow-mask, The Dress 2015 — non sono “errori” del sistema ma finestre sulle assunzioni che il sistema fa quotidianamente con successo. Patologie come la schizofrenia e la sindrome di Charles Bonnet sono esperimenti naturali che mostrano cosa succede quando i priors sono mal-calibrati o privati di input. Il capitolo distingue con cura le classi di affermazioni — analogia, filiazione, equivalenza — e marca esplicitamente le tentazioni: hallucination LLM non è percezione umana con prior dominante, predictive coding non è next-token prediction, diffusion models non sono modelli percettivi. È un sotto-registro storico-scientifico: il presente AI sta confinato in una sezione marcata.
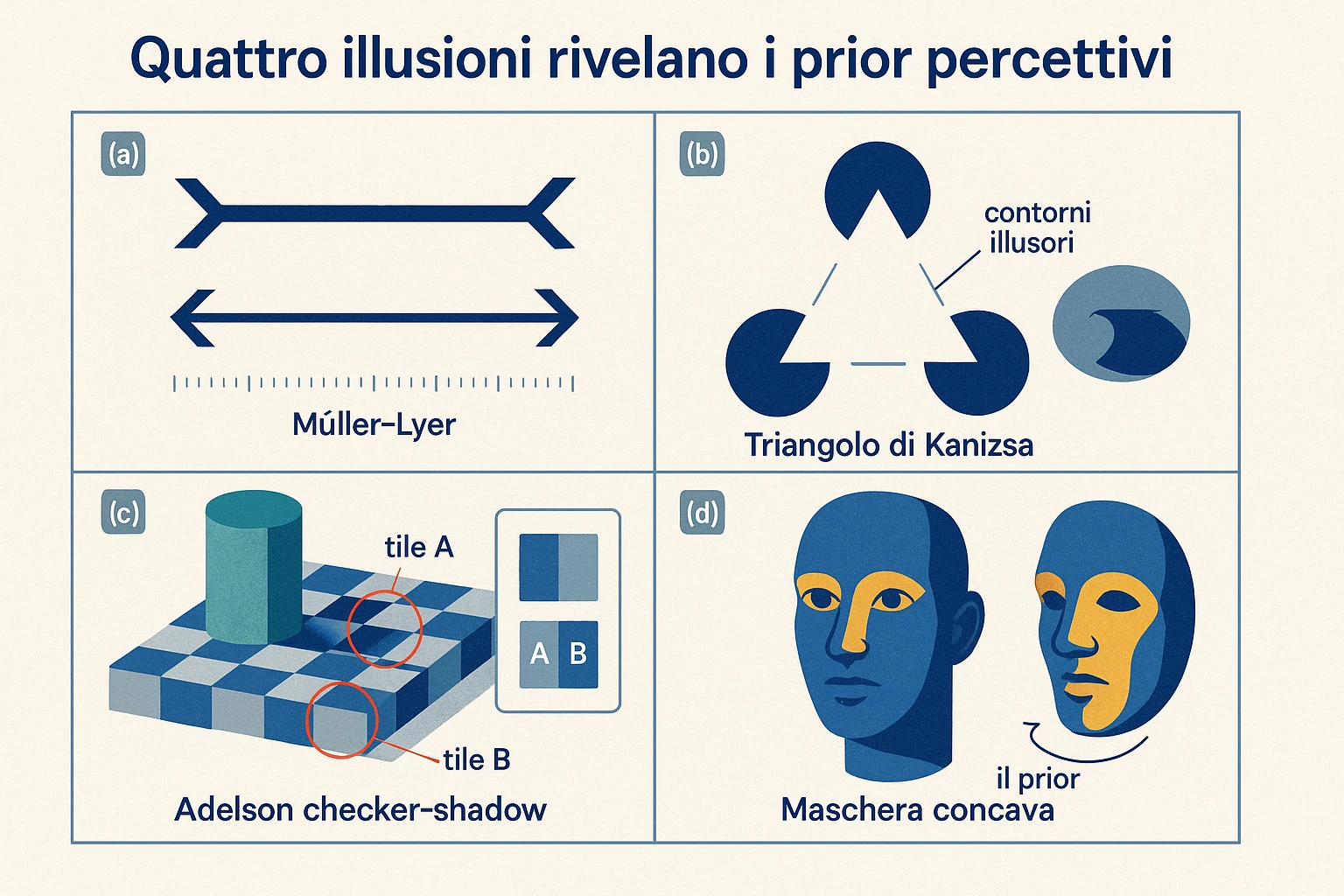
Guarda due piastrelle su una scacchiera in penombra. Le chiamiamo A e B. A è quella chiara, fuori dall’ombra di un cilindro; B è quella scura, sotto l’ombra. È evidente — evidente al punto che se qualcuno ti dicesse il contrario lo chiameresti pazzo — che A è più chiara di B.
Sei pixel. Misuri il valore di luminanza di A. Misuri B. Sono identici. La piastrella A e la piastrella B emettono verso il tuo occhio la stessa quantità di luce. Eppure il tuo sistema visivo, di fronte a quel singolo dato fisico, produce due percetti incompatibili: “A chiara, B scura”.
Questa immagine è la checker-shadow illusion di Edward Adelson (1952–, scienziato della visione al MIT, autore del 1995 “Lightness perception and lightness illusions”). Non è un trucco grafico. È un’esibizione pubblica di un fatto che la scienza della percezione ha impiegato due secoli a rendere preciso: ciò che vedi non è una funzione semplice di ciò che colpisce la retina. È il risultato di un’inferenza che il sistema visivo compie sotto la soglia della consapevolezza, combinando i dati sensoriali con un sapere implicito sul mondo. In particolare: “le ombre attenuano la luminanza; se una superficie sotto un’ombra emette tanta luce quanto una superficie in piena illuminazione, allora la superficie sotto l’ombra è — di fatto — molto più chiara”. Il sistema applica questa regola automaticamente, prima che la coscienza arrivi al percetto.
L’idea che la percezione sia inferenza ha un nome storico: unbewusster Schluss, inferenza inconscia. Il termine appare nel terzo volume del Handbuch der physiologischen Optik di Hermann von Helmholtz (1821–1894, fisico e fisiologo tedesco, prima a Heidelberg poi a Berlino, una delle figure piene del XIX secolo scientifico), pubblicato a Lipsia nel 1867 dall’editore Voss. Helmholtz scrive — semplificando — che le sensazioni nude non sono percezioni: la percezione è il prodotto di un’inferenza che il cervello fa sui dati sensoriali, basandosi sull’esperienza pregressa. Lo schema è già lì: dati ambigui + sapere implicito → percetto.
Questo capitolo ricostruisce centocinquant’anni di lavoro scientifico su quell’intuizione. Si parte da Helmholtz 1867, si passa per la Gestaltpsychologie di Max Wertheimer (1880–1943, psicologo cecoslovacco-tedesco a Francoforte) nel 1912, per il New Look di Jerome Bruner (1915–2016, psicologo americano a Harvard) nel 1947, per il costruttivismo di Richard Gregory (1923–2010, psicologo britannico a Bristol) negli anni Settanta in dialettica con il realismo ecologico di James J. Gibson (1904–1979, psicologo americano alla Cornell). Si arriva al programma bayesiano formale di David Knill e Whitman Richards (vision scientists al MIT) nel 1996, all’integrazione multisensoriale ottimale di Marc Ernst e Martin Banks del 2002, al predictive coding gerarchico di Rajesh Rao e Dana Ballard (informatici a Rochester) del 1999, fino al free-energy principle di Karl Friston (neuroscienziato all’University College London) del 2010 e alla sintesi filosofica di Andy Clark (filosofo della mente, prima a Edinburgh poi a Sussex) nel 2013.
Vale la pena fissare subito una distinzione che il capitolo attraverserà più volte. La parola “percezione” qui non significa “elaborazione di tutti i dati sensoriali in arrivo”. Significa il processo che, a partire da dati ambigui e parzialmente impoveriti, produce un percetto — un contenuto fenomenologico stabile, attribuito a oggetti e scene del mondo. Helmholtz lo chiama inferenza inconscia, i moderni lo chiamano inferenza bayesiana o predictive processing. Il punto è lo stesso: quello che vivi come “vedere il mondo” è il prodotto di un calcolo sotto la soglia, e quel calcolo è descrivibile.
Una seconda distinzione preliminare. Il framework discusso qui è computazionale nel senso di David Marr (Vision, 1982): descrive cosa il sistema percettivo calcola e perché è una soluzione razionale al problema posto dall’ambiente. Non è automaticamente una descrizione di come il cervello implementa il calcolo a livello neurale. La domanda implementativa — quali popolazioni di neuroni codificano cosa, con quali tempi — è una domanda separata, e meno risolta. Confondere i livelli (il che cosa con il come) è una causa frequente di confusione divulgativa, e ne riparleremo nella sezione “Dove si rompe”.
Perché questo capitolo
Sezione intitolata “Perché questo capitolo”Tre ragioni: epistemologica, fenomenologica, di igiene terminologica.
Epistemologica: la percezione è il caso paradigmatico in cui l’introspezione è ingannevole. Dal nostro punto di vista soggettivo, vedere è un’attività trasparente: gli occhi forniscono il mondo, il cervello lo riceve. La scienza della percezione mostra il contrario: il cervello costruisce attivamente il percetto, e la trasparenza fenomenica è essa stessa un prodotto della costruzione. Capire questo cambia il modo in cui un lettore tecnico legge le scienze cognitive: non come tassonomia di stati interni, ma come ingegneria inversa di un sistema computazionale che fa inferenza sotto vincoli.
Fenomenologica: le illusioni — Müller-Lyer, Kanizsa, Adelson, hollow-mask, The Dress 2015, Yanny vs Laurel 2018 — non sono divertimenti da rivista popolare. Sono evidenze sperimentali che mostrano quali assunzioni il cervello fa. Quando una piastrella in ombra appare più chiara di una identica fuori dall’ombra, hai osservato in vivo un prior all’opera. La storia delle illusioni è la storia delle ipotesi falsificate sui priors percettivi.
Di igiene terminologica, e per chi lavora con sistemi AI questa è probabilmente la ragione che pesa di più. Termini come prior, posterior, inference, prediction, generative model circolano oggi in due ambiti — neuroscienza percettiva e machine learning — con riferimenti talvolta sovrapposti, talvolta divergenti. È facile scivolare da analogia a filiazione a equivalenza nello stesso paragrafo. Hallucination di un LLM non è la percezione umana con prior dominante. Predictive coding non è next-token prediction. Un diffusion model non è un sistema percettivo. Marcare le differenze — quale parte è analogia produttiva, quale convergenza concettuale, quale niente — è un servizio. La sezione “Eredità oggi” ci torna in modo ordinato, e tutto quel discorso resta confinato lì, in una sidebar marcata [DATATO].
Contesto: una linea storica essenziale
Sezione intitolata “Contesto: una linea storica essenziale”1867 — Helmholtz, Handbuch der physiologischen Optik. Helmholtz è già famoso quando pubblica il terzo volume della sua opera ottica (i primi due 1856, 1860). È fisico, ha riformulato il principio di conservazione dell’energia, e ha inventato l’oftalmoscopio nel 1851. Quando scrive sull’unconscious inference, lo fa con la disinvoltura di chi pensa che l’occhio sia un sistema fisico misurabile e il cervello un sistema d’inferenza modellabile. La proposta: la percezione è un’inferenza, simile all’inferenza scientifica esplicita, ma compiuta automaticamente e sotto la soglia della consapevolezza, sulla base dell’esperienza accumulata.
1912 — Wertheimer, “Experimentelle Studien über das Sehen von Bewegung”. Wertheimer pubblica sul Zeitschrift für Psychologie lo studio del phi phenomenon: due luci che lampeggiano in successione vengono percepite come un’unica luce in movimento, anche se non c’è movimento fisico. Il fatto è ovvio per chiunque guardi una pubblicità luminosa, ma Wertheimer ne fa un argomento contro l’atomismo percettivo: la percezione non è somma di stimoli puntuali, è organizzazione globale. Da qui nascono le leggi della Gestalt — prossimità, similarità, chiusura, continuità, figura-sfondo, pregnanza — formalizzate insieme a Wolfgang Köhler (1887–1967) e Kurt Koffka (1886–1941). Le leggi della Gestalt sono, in linguaggio moderno, priors strutturali: regolarità del mondo che il sistema percettivo assume come default.
1947 — Bruner & Goodman, “Value and need as organizing factors in perception”. Pubblicato sul Journal of Abnormal and Social Psychology, l’esperimento è semplice: bambini di dieci anni, alcuni da famiglie povere, altri da famiglie benestanti, devono stimare al volo la dimensione di monete di valore crescente — 1, 5, 10, 25, 50 cent — confrontandole con un disco luminoso regolabile. I bambini poveri sovrastimano sistematicamente, e la sovrastima cresce col valore della moneta. Bruner e Cecil Goodman ne traggono la tesi del New Look in perception: la percezione non è data sense-only, è modulata da motivazione, valore, aspettative. L’idea sarà contestata negli anni Cinquanta — i critici ridurranno l’effetto a un bias di risposta — ma il principio sopravvive: il prior comprende anche stati motivazionali del soggetto.
1970/1997 — Gregory, Eye and Brain. Richard Gregory eredita Helmholtz, e in The Intelligent Eye (1970) e nelle successive edizioni di Eye and Brain (cinque edizioni dal 1966 al 1997, Princeton University Press) propone una formulazione esplicita: la percezione è hypothesis testing. Il sistema visivo formula ipotesi sul mondo, e le illusioni sono casi in cui l’ipotesi vincente è sistematicamente sbagliata per quel particolare stimolo, ma sarebbe stata corretta nella stragrande maggioranza dei casi naturali. Gregory inventa la hollow-mask illusion: una maschera cava di un volto, illuminata in modo da rivelarne la concavità, è percepita come convessa. L’esperimento è cruciale perché il prior “le facce sono convesse” è così robusto da vincere su ombreggiatura e parallasse, due segnali geometrici che dovrebbero rivelare la concavità.
1979 — Gibson, The Ecological Approach to Visual Perception. Gibson è la voce contraria. Per Gibson la percezione è diretta: l’informazione invariante presente nel flusso ottico (texture gradients, optic flow, occlusione) è già sufficiente a specificare la scena, senza bisogno di inferenze interne. Il concetto chiave è affordances: l’ambiente offre direttamente all’organismo le sue possibilità d’azione (una sedia “afforda” il sedersi), e il sistema percettivo è un risuonatore tarato per cogliere queste affordances. La dialettica Gregory–Gibson è la dialettica costruttivismo vs ecologismo. Sintesi moderna: i due programmi non sono incompatibili. Il cervello costruisce, ma costruisce sulla base di un’esposizione ecologica che ha plasmato i suoi priors. I priors sono anche invarianti dell’ambiente di evoluzione e sviluppo.
1996 — Knill & Richards (eds.), Perception as Bayesian Inference. Cambridge University Press. Volume curato dai due, con contributi di vari autori. Fissa il programma: la percezione è massimizzazione del posterior . Il prior codifica le regolarità del mondo; la likelihood codifica il modello di formazione del dato sensoriale; il posterior è la distribuzione di credenza sulla scena dati i sensi; il percetto è la stima di massima probabilità a posteriori (MAP).

1999 — Rao & Ballard, “Predictive coding in the visual cortex”. Nature Neuroscience. Modello gerarchico della corteccia visiva: ogni livello manda predizioni top-down al livello inferiore e riceve indietro l’errore di predizione (la differenza tra l’input atteso e quello effettivo). Le risposte neurali non rappresentano valori bruti dello stimolo, rappresentano errori residui. Il modello predice fenomeni come l’end-stopping (cellule V1 che rispondono di meno a barre lunghe che a barre corte) come effetto di predizione contestuale.
2002 — Ernst & Banks, “Humans integrate visual and haptic information in a statistically optimal fashion”. Nature. Test diretto e quantitativo del programma bayesiano. Soggetti stimano l’altezza di una barretta usando solo la vista, solo il tatto, o entrambi i canali insieme. Quando entrambi i canali sono disponibili, la stima combinata segue quasi esattamente la formula di maximum likelihood estimation per due osservazioni gaussiane indipendenti: ciascun canale viene pesato in proporzione inversa alla sua varianza. Aggiungendo rumore visivo, il peso si sposta verso il tatto, come predetto dal modello.
2010 — Friston, “The free-energy principle: a unified brain theory?”. Nature Reviews Neuroscience. Karl Friston propone una generalizzazione: ogni sistema biologico self-organizing minimizza la free energy variazionale, un upper bound matematico sulla “surprise” (la log-probabilità negativa dei dati sotto il modello generativo del sistema). Nel cervello, percezione e azione sono casi particolari della stessa minimizzazione: la percezione minimizza la free energy aggiornando le rappresentazioni interne; l’azione (active inference) la minimizza modificando il mondo perché si conformi alle predizioni. È una teoria di portata enorme, e — vedremo nella sezione “Dove si rompe” — proprio per questo accusata di essere troppo flessibile per essere falsificabile in modo netto.
2013 — Clark, “Whatever next? Predictive brains, situated agents, and the future of cognitive science”. Behavioral and Brain Sciences 36(3), target article con repliche. Andy Clark consolida il quadro per la filosofia della mente: la mente come prediction machine gerarchica. Percezione, azione, attenzione, emozione sono manifestazioni di un unico meccanismo di minimizzazione di prediction error. La precision — l’inverso della varianza, cioè quanto fidarsi di un canale di errore — è la variabile che modula il peso relativo di top-down vs bottom-up, ed è il punto di contatto formale con l’attenzione discussa in attenzione-psicologia.
L’intuizione: due angoli prima del formalismo
Sezione intitolata “L’intuizione: due angoli prima del formalismo”Prima di entrare nelle formule, due angoli per fissare l’intuizione.
Angolo 1: il fenomeno — illusioni come “errori istruttivi”
Sezione intitolata “Angolo 1: il fenomeno — illusioni come “errori istruttivi””Guarda di nuovo la checker-shadow di Adelson. Le piastrelle A e B emettono la stessa quantità di luce. Tu vedi A chiara e B scura. La spiegazione non è che il tuo occhio sia rotto. Il tuo sistema visivo ha eseguito un calcolo molto utile nella vita ordinaria: dato che B è all’interno di un’ombra (segnale geometrico: il cilindro proietta un cono d’ombra sulla scacchiera), e dato che le ombre attenuano la luce riflessa, una piastrella che dentro un’ombra emette tanta luce quanto una piastrella in piena illuminazione deve essere — di fatto — molto più chiara. Il cervello applica la regola, e produce un percetto di “chiarezza intrinseca”, non di “luminanza pixel”.
Nella stragrande maggioranza degli ambienti naturali questa regola è corretta. Quando guardi un libro per metà al sole e per metà all’ombra, non lo percepisci come un libro a strisce, lo percepisci come un libro uniforme. La costanza percettiva — riconoscere oggetti a dispetto delle variazioni di illuminazione, distanza, angolo — è il principale risultato del lavoro percettivo. Le illusioni sono i casi limite in cui il prior viene applicato in modo inappropriato. La loro funzione epistemica è esattamente questa: rivelare quale prior il sistema sta usando.
Quattro illusioni canoniche, ognuna isola un prior diverso:
- Müller-Lyer (Franz Müller-Lyer, 1889): due segmenti di pari lunghezza con frecce alle estremità — interne o esterne — appaiono di lunghezza differente. Prior: nel mondo carpenterato di interni rettilinei, le frecce esterne segnalano un angolo che si allontana, le frecce interne un angolo che si avvicina. Su uno spigolo lontano si vede più segmento; su uno vicino, meno. Il sistema corregge automaticamente la lunghezza percepita per il prior di profondità.
- Kanizsa triangle (Gaetano Kanizsa, psicologo italiano a Trieste, 1955): tre Pac-Man neri orientati in modo da suggerire un triangolo bianco occludente. Vedi il triangolo, e vedi i suoi contorni, anche dove i contorni fisici non esistono. Prior: gli oggetti occludono altri oggetti, e l’occlusione è la spiegazione più semplice di una configurazione di forme tagliate.
- Adelson checker-shadow (1995, vedi sopra). Prior: le ombre attenuano la luminanza.
- Hollow-mask (Gregory 1970): una maschera cava illuminata da fronte appare convessa. Prior: le facce sono convesse, e questo prior è abbastanza forte da vincere sull’evidenza geometrica contraria.
A queste si aggiungono fenomeni di bistabilità, in cui lo stesso stimolo fisico costante produce due percetti alterni che il soggetto non riesce a stabilizzare con la sola volontà:
- Necker cube (Louis Albert Necker, cristallografo svizzero, 1832): un cubo wireframe disegnato in proiezione assonometrica può essere visto con una faccia in primo piano oppure con la faccia opposta in primo piano. Le due interpretazioni sono entrambe geometricamente coerenti col disegno; nessun prior monocolare le seleziona univocamente; il sistema oscilla.
- Rubin face/vase (Edgar Rubin, psicologo danese, Synsoplevede Figurer, 1915): un’immagine bianco/nero in cui le regioni nere sono due profili simmetrici che si fronteggiano e la regione bianca è un calice. Il sistema decide fra “figura = profili / sfondo = calice” e “figura = calice / sfondo = profili”. È bistabile perché il prior figura-sfondo non ha un perno univoco.
- Yanny vs Laurel (audio illusion, virale maggio 2018): una clip audio sintetica che alcuni ascoltatori percepiscono come “Yanny”, altri come “Laurel”. L’analisi mostra che le frequenze alte favoriscono “Yanny” e le frequenze basse “Laurel”; il bilanciamento individuale (età, dispositivo audio, prior fonetico) seleziona uno dei due percetti. Versione audio del fenomeno di The Dress.
In linguaggio bayesiano: lo stimolo d è genuinamente ambiguo, il posterior ha due modi di altezza simile, e piccole variazioni di prior individuale o di stato del sistema spostano il MAP da uno all’altro modo. Il fatto che la percezione bistabile esista è un argomento forte contro l’ipotesi che il sistema percettivo restituisca distribuzioni complete: restituisce stime puntuali e oscilla quando le stime sono ex aequo.
Angolo 2: la formalizzazione — Bayes come grammatica del percetto
Sezione intitolata “Angolo 2: la formalizzazione — Bayes come grammatica del percetto”Il secondo angolo è formale. Helmholtz aveva detto “inferenza”; Knill e Richards dicono quale inferenza, e in che linguaggio.
Sia la scena (la grandezza che vorresti percepire — profondità, luminosità intrinseca, identità di un oggetto). Sia il dato sensoriale che ricevi (luminanza retinica, parallasse, gradiente). Il problema è che è ambiguo: molte scene diverse possono produrre lo stesso d. È un problema inverso, e i problemi inversi non hanno soluzione unica senza un’informazione aggiuntiva.
L’informazione aggiuntiva è il prior : una distribuzione di probabilità sulle scene possibili, che riflette la statistica del mondo nel quale il sistema percettivo si è sviluppato (su scala evolutiva e ontogenetica). Ad essa si combina il likelihood : la probabilità di osservare il dato d se la scena fosse s. Il teorema di Bayes (vedi [bayes-base](in preparazione) per i dettagli) dà il posterior:
Il denominatore è una costante di normalizzazione che non dipende da s. Per scegliere la scena percepita, il sistema sceglie il valore di s che massimizza il posterior — la stima MAP (maximum a posteriori).
In linguaggio Bayesiano:
- Il prior è “cosa il sistema crede prima di vedere”.
- Il likelihood è “quanto il dato è compatibile con ciascuna scena candidata”.
- Il posterior è “cosa il sistema crede dopo aver visto”.
- Il percetto è il modo del posterior (o un’estrazione, in modelli stocastici).
Questa grammatica unifica tutti i fenomeni discussi sopra:
- Costanza percettiva = prior dominante ( molto piccato) che porta a percetti stabili anche con
dvariabile. - Illusioni = casi in cui il prior è inappropriato per quello specifico
d(la maschera è davvero cava, ma è troppo forte). - New Look = il prior comprende motivazione e valore.
- Bistable figures (Necker cube, Rubin face/vase) = il posterior ha due modi quasi-equivalenti, e il percetto oscilla.
Quello che resta da chiarire è da dove vengono i priors. Risposta breve: dall’esperienza, su due scale temporali. Sulla scala evolutiva (i priors di basso livello: continuità delle superfici, coerenza spaziale, “luce viene dall’alto” perché sulla Terra il sole è in alto). Sulla scala ontogenetica (i priors di alto livello: facce, oggetti familiari, contesti culturali). Il perceptual learning, di cui parleremo, è il meccanismo che aggiorna i priors con l’esperienza individuale.
La meccanica
Sezione intitolata “La meccanica”Bayesian perception: cue combination ottimale
Sezione intitolata “Bayesian perception: cue combination ottimale”Il caso quantitativamente più chiaro è il cue combination. Hai due canali sensoriali indipendenti che stimano la stessa grandezza con rumore gaussiano. Il sistema dovrebbe combinarli con pesi inversamente proporzionali alle loro varianze.
Sia la stima visiva con varianza . Sia la stima haptic (tatto) con varianza . Sotto assunzioni gaussiane di indipendenza, la stima MLE combinata è:
In parole: il canale meno rumoroso pesa di più. La varianza combinata è sempre minore di quella di ciascun canale singolo.
Ernst e Banks 2002 hanno fatto esattamente questo esperimento. Soggetti stimano l’altezza di una barretta usando vista (con livelli di rumore visivo manipolati), tatto, o entrambi. Misurando le varianze individuali nelle condizioni unimodali, predicono — senza parametri liberi — la varianza nella condizione bimodale e il peso che il soggetto dovrebbe dare a ciascun canale. La predizione è quasi esattamente verificata. Quando aggiungono rumore visivo, il peso si sposta verso il tatto secondo la formula. Il sistema percettivo è un combinatore MLE quasi-ottimale.
Il risultato è bayesiano in senso forte: non solo la percezione è inferenza qualitativa, è inferenza statisticamente ottimale sotto i vincoli del rumore.
Predictive coding gerarchico
Sezione intitolata “Predictive coding gerarchico”Rao e Ballard 1999 propongono un’architettura: la corteccia visiva è una gerarchia, e ogni livello manda al livello inferiore una predizione di cosa dovrebbe vedere, e riceve indietro l’errore rispetto a ciò che il livello inferiore vede davvero.
Sia la rappresentazione interna al livello i. Sia la predizione che il livello i invia al livello i-1 (top-down). Il livello i-1 confronta la predizione con la propria stima locale , calcola l’errore , e lo propaga verso l’alto. Il livello i aggiorna per ridurre l’errore.
A regime stazionario, le rappresentazioni codificano una stima della scena a quel livello di astrazione, e i neuroni “errore” codificano lo scarto residuo dopo che la predizione top-down è stata sottratta. Il modello predice diversi fenomeni neurofisiologici, fra cui:
- End-stopping: cellule V1 che rispondono a barre, ma con risposta che diminuisce per barre lunghe oltre un certo limite. Spiegazione predictive: per una barra lunga, i livelli superiori predicono “barra estesa”, e l’errore residuo nei livelli V1 si riduce alle estremità.
- Surround suppression: una cellula V1 risponde meno a uno stimolo nel suo campo recettivo se intorno c’è uno stimolo simile. Spiegazione predictive: i livelli superiori predicono “regione uniforme di texture”, e l’errore residuo nei punti interni è basso.
Il punto profondo è ribaltato rispetto al senso comune. Il senso comune dice: la corteccia rappresenta il mondo. Il predictive coding dice: la corteccia rappresenta dove il modello sbaglia. Le rappresentazioni esplicite del mondo sono nei livelli alti del modello generativo; ciò che si misura come attività neurale ai livelli bassi è prevalentemente residual error, ossia ciò che la predizione top-down non è ancora riuscita a spiegare.
Free energy e active inference
Sezione intitolata “Free energy e active inference”Friston 2010 generalizza. Definisce la free energy variazionale come:
F = E_q[ log q(s) - log p(d, s) ]dove è la distribuzione approssimante interna sulla scena, è il modello generativo congiunto del sistema (che include il prior e il likelihood ). Si dimostra (calcolo che sta in qualunque libro di variational inference) che è un upper bound sulla surprise . Minimizzare significa, in modo trattabile, cercare di minimizzare la surprise sui dati osservati.
Due strategie per minimizzare F:
- Aggiornare
q(s): questa è la percezione. Il sistema aggiorna le sue credenze interne per matchare meglio i dati. - Aggire sul mondo per cambiare
d: questa è l’active inference. Il sistema sceglie azioni che porteranno a osservare dati che il suo modello già spiega bene.
Si capisce perché la teoria sia attraente: unifica percezione, azione e apprendimento sotto un unico principio variazionale. Si capisce anche perché sia controversa: una teoria che spiega tutto rischia di non vincolare nulla. Torneremo sul punto in “Dove si rompe”.
Illusioni in linguaggio bayesiano
Sezione intitolata “Illusioni in linguaggio bayesiano”Riformuliamo le illusioni nel framework. La hollow-mask: il dato retinico d è compatibile sia con una maschera convessa illuminata in un certo modo, sia con una maschera concava illuminata in modo opposto. Il likelihood è bimodale. Ma il prior è fortemente piccato sulla configurazione “convessa” — perché la stragrande maggioranza delle facce viste in una vita è convessa. Il posterior eredita la bimodalità del likelihood ma viene riponderato dal prior: il modo “convessa” diventa molto più alto del modo “concava”. MAP → percetto convesso, anche quando la verità geometrica è concava.
The Dress 2015: lo stimolo retinico è genuinamente ambiguo tra “vestito blu/nero illuminato da luce calda” e “vestito bianco/oro illuminato da luce fredda”. Il posterior è bimodale. Diversi individui hanno priors diversi sull’illuminazione tipica del loro ambiente — chi è più esposto a luce naturale tende a inferire che la fonte luminosa è fredda (Wallisch 2017). Quindi diversi individui MAP-pano modi diversi. È un esperimento naturale che separa likelihood (uguale per tutti) e prior (variabile fra individui).
Esempio 1: hollow-mask come finestra su una patologia
Sezione intitolata “Esempio 1: hollow-mask come finestra su una patologia”Questo è il caso clinico più ricco. Una maschera cava di un volto, illuminata frontalmente in un modo che renderebbe la concavità geometricamente leggibile, è percepita come convessa dal soggetto neurotipico. La percezione è robusta: persiste anche dopo che il soggetto sa razionalmente che la maschera è cava.
In pazienti con schizofrenia, l’illusione è ridotta. Lo studio classico è di Schneider et al. 2002, ma la sintesi è in Sterzer, Adams, Fletcher 2018 (review Biological Psychiatry): i pazienti vedono la maschera cava più spesso come effettivamente cava. Interpretazione predictive coding: nei pazienti, la precision assegnata ai priors di alto livello (qui: “facce convesse”) è ridotta, mentre la precision assegnata ai prediction error sensoriali è aumentata. Risultato netto: meno illusione (perché il prior è meno dominante), ma anche maggiore vulnerabilità a “spurious salience” — anomalie sensoriali che il sistema fatica a sopprimere, predisponendo a esperienze deliranti.
Questo è un esempio potente perché unisce tre livelli: fenomenologico (l’illusione), formale (precision in linguaggio bayesiano), clinico (psicosi). Mostra la forza del framework: una stessa quantità formale — la precision dei priors di alto livello — spiega un fenomeno percettivo specifico e una psicopatologia. Va detto che il legame causale è ancora dibattuto, ma la convergenza esplicativa è significativa.
Esempio 2: cue combination MLE in numeri concreti
Sezione intitolata “Esempio 2: cue combination MLE in numeri concreti”Riprendi Ernst-Banks 2002. Supponi che un soggetto stimi l’altezza di una barretta. Con la sola vista, su molte prove, la sua stima ha media e deviazione standard . Con il solo tatto, e .
Predizione MLE per la condizione combinata vista+tatto:
peso_v = (1/σ_v²) / (1/σ_v² + 1/σ_h²) = (1/4) / (1/4 + 1/16) = 0.25 / 0.3125 = 0.8peso_h = 1 - peso_v = 0.2σ_comb = 1 / sqrt(1/4 + 1/16) ≈ 1.79 mmCioè: il soggetto dovrebbe pesare la vista all’80% e il tatto al 20%, e la sua deviazione standard combinata dovrebbe scendere a circa 1.79 mm — minore di entrambi i singoli canali.
Quando Ernst e Banks aggiungono rumore visivo per portare a 4 mm (uguale al tatto), la predizione cambia: , . E ancora: se portano a 8 mm (peggio del tatto), il peso si sposta sul tatto.
I dati sperimentali seguono la predizione con scarti minimi. È uno dei risultati più puliti delle scienze cognitive: un sistema biologico messo davanti a un compito di stima multimodale fa esattamente quello che farebbe uno statistico bayesiano informato sulle varianze.
Esempio 3: la sindrome di Charles Bonnet come prior senza input
Sezione intitolata “Esempio 3: la sindrome di Charles Bonnet come prior senza input”Charles Bonnet (1720–1793) era un naturalista svizzero. Nel 1760 descrisse un fenomeno che osservò nel proprio nonno, parzialmente cieco per cataratta: il vecchio aveva allucinazioni visive vivide e dettagliate — uomini, donne, edifici, motivi geometrici — pur sapendo perfettamente che erano allucinazioni. La sindrome porta il suo nome.
Il quadro clinico moderno è chiaro: pazienti con perdita parziale di input visivo (macular degeneration, glaucoma avanzato, danni alla via visiva) sviluppano allucinazioni complesse, spesso stereotipate (volti familiari, motivi a scacchi, animali piccoli), tipicamente preservando l’insight — il paziente sa che non sono reali. La prevalenza fra anziani con grave perdita visiva è sostanziale (stime dal 10% al 40% in vari studi). È raramente segnalata perché i pazienti temono di apparire dementi.
L’interpretazione predictive coding è netta. Quando l’input retinico cala drasticamente, i prediction error a basso livello calano (non ci sono più dati da contraddire le predizioni). I livelli alti del modello generativo continuano a generare predizioni top-down basate sui priors interni — facce, oggetti, scene familiari — ma queste predizioni non vengono più “corrette” dai bottom-up errors. Il risultato è un percetto puro-dal-prior, vivo come un percetto normale, ma scollegato dall’input. È l’argomento più forte a favore dell’idea che la percezione normale sia una inferenza in cui i priors sono normalmente ancorati dai dati: togli l’ancora, e i priors fluttuano liberamente.
Il caso clinico ha valore epistemico oltre che terapeutico. Se la percezione fosse semplicemente una funzione lineare degli input retinici, una perdita di input dovrebbe produrre una perdita corrispondente di percetto — vuoto, oscurità, scotomi. Charles Bonnet mostra che invece il sistema riempie attivamente il vuoto. È coerente con tutto il quadro bayesiano-predictive del capitolo, ed è probabilmente l’esempio più persuasivo per chi parte scettico.
Esempio 4: ANN con texture bias (Geirhos 2019)
Sezione intitolata “Esempio 4: ANN con texture bias (Geirhos 2019)”Il terzo esempio è il caso AI, e serve a fare una distinzione precisa che porteremo nella sezione “Eredità oggi”. Robert Geirhos e colleghi (Università di Tübingen) pubblicano a ICLR 2019 lo studio “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness”.
Il design è elegante. Prendono immagini stilizzate combinando la forma di un oggetto (es. un gatto) con la texture di un altro (es. la pelle di un elefante). Una “texture-shape cue conflict image”. Un classificatore CNN addestrato su ImageNet di solito classifica queste immagini sulla base della texture: gatto-con-pelle-di-elefante → “elefante”. Gli osservatori umani classificano sulla base della forma: stesso stimolo → “gatto”.
Il risultato non è banale. Significa che le rappresentazioni interne acquisite dalle CNN durante il training sono strutturalmente diverse da quelle umane: la statistica di ImageNet incentiva il riconoscimento per pattern locali di texture, e la rete impara di conseguenza. Quando Geirhos addestra le stesse architetture su un dataset stilizzato (Stylized-ImageNet, dove le texture sono sostituite con texture di pittura), lo shape bias aumenta e la robustezza ad alcune perturbazioni cresce.
Tradotto in linguaggio bayesiano: il prior indotto dal training è diverso dal prior umano. La percezione umana è guidata da un prior che pesa fortemente la geometria globale; la percezione delle CNN ImageNet-trained è guidata da un prior che pesa la statistica locale. È evidenza concreta che “vedere” non è una funzione universale del visto: dipende dalla storia di chi guarda.
Aggiungo una nota numerica utile per fissare l’intuizione bayesiana. Considera un caso unidimensionale di percezione di profondità da disparità binoculare. Supponi che il likelihood — l’evidenza retinica grezza — sia una gaussiana centrata su 1.5 m con deviazione 0.5 m. Supponi che il prior, basato sul contesto della scena (“sto in una stanza di dimensioni note”), sia una gaussiana centrata su 2.0 m con deviazione 0.2 m. Il posterior gaussiano, prodotto delle due, ha media:
μ_post = (μ_l/σ_l² + μ_p/σ_p²) / (1/σ_l² + 1/σ_p²) = (1.5/0.25 + 2.0/0.04) / (1/0.25 + 1/0.04) = (6 + 50) / (4 + 25) = 56/29 ≈ 1.93 mIl percetto è 1.93 m, molto più vicino al prior (2.0) che al likelihood (1.5), perché il prior è molto meno rumoroso (varianza 0.04 contro 0.25). La deviazione del posterior è circa 0.186 m. Il prior “tira” il percetto a sé in proporzione alla propria precision. Quando in una stanza buia stimi una distanza in modo grossolanamente sbagliato, è perché il likelihood retinico è particolarmente rumoroso e il prior contestuale domina.
Applicazioni e implicazioni
Sezione intitolata “Applicazioni e implicazioni”Il framework bayesiano-predictive ha applicazioni dirette in diverse aree:
Vision science clinica: la calibrazione individuale dei priors è una variabile diagnostica. Sterzer 2018 e successori usano la riduzione dell’illusione hollow-mask come bio-marker indiretto per profili di precision alterati in psicosi. Studi simili su autismo (Pellicano-Burr 2012, ipotesi “hyper-precision di low-level priors”) sono più controversi e meno consolidati.
Audiologia e linguaggio: lo speech recognition umano è multisensoriale e fortemente top-down. L’effetto McGurk — Harry McGurk (1936–1998, psicologo dello sviluppo all’Università del Surrey) e John MacDonald in Nature 1976, “Hearing lips and seeing voices” — mostra che il visivo /ga/ combinato con l’auditivo /ba/ produce il percetto /da/, un fonema che non è in nessuno dei due input. È uno dei risultati più replicati delle scienze cognitive: l’effetto sopravvive anche al sapere che si tratta di un’illusione, anche all’attenzione focalizzata sull’audio. La spiegazione predictive è semplice: il sistema fonetico cerca un fonema che sia compatibile sia col gesto labiale visto sia col tratto acustico udito, e /da/ è il candidato che minimizza l’errore congiunto. Ventriloquismo, lip-reading, comprensione del parlato in ambiente rumoroso: tutti sono casi di cue combination con priors fonetici e contestuali. Lo stesso meccanismo spiega perché i sottotitoli aiutano la comprensione di un audio scadente: forniscono un prior testuale che disambigua il segnale acustico.
Body ownership: la rubber hand illusion (Botvinick-Cohen 1998, Nature) — il soggetto vede una mano di gomma essere accarezzata in sincrono con la propria mano nascosta, e dopo trenta secondi la “sente” come propria — è cue combination tra visivo, tattile, propriocettivo. Il prior corporeo è plastico ed è ricalibrato in tempo reale dall’evidenza multisensoriale. Spiega anche fenomeni come il phantom limb descritto da V. S. Ramachandran (1951–, neurologo indo-americano a UCSD): l’amputato continua a sentire l’arto perché il prior corporeo persiste senza input.
Perceptual learning: il sistema percettivo aggiorna i propri priors con esperienza. Asaf Ahissar e Shaul Hochstein in Trends in Cognitive Sciences 2004 propongono la reverse hierarchy theory: l’apprendimento parte dai livelli alti (rapido, grossolano) e scende verso quelli bassi (lento, fine-grained). Takeo Watanabe e Yuka Sasaki (review Annual Review of Psychology 2015) mappano la letteratura. Il caso pratico: un radiologo esperto vede pattern in una radiografia che il novizio non vede. Non è un trucco di attenzione, è un prior raffinato attraverso esposizione.
Sviluppo: la finestra di acquisizione dei priors percettivi ha vincoli temporali. David Hubel (1926–2013) e Torsten Wiesel (1924–, premi Nobel 1981, allora ad Harvard) negli esperimenti del 1962-1970 sui gattini mostrano che la chiusura monoculare durante un periodo critico (4–12 settimane) lascia conseguenze permanenti sull’organizzazione corticale: le colonne di dominanza oculare in V1 si riorganizzano per favorire l’occhio aperto, e la riapertura tardiva del secondo occhio non recupera la rappresentazione perduta. Negli umani, Ayelet McKyton e colleghi (Current Biology 2015, “The limits of shape recognition following late emergence from blindness”) studiano pazienti operati per cataratta congenita in tarda età: l’acuità di base si recupera entro mesi, ma il riconoscimento di forme complesse, soprattutto in condizioni di occlusione parziale o illuminazione non standard, resta deficitario anche a distanza di anni. I priors sviluppistici hanno una finestra, e oltre quella la riconfigurazione è limitata. È un dato a cui la perception research deve molta della sua autorità clinica: un sistema percettivo non è universalmente plastico, e la statistica dell’ambiente di esposizione precoce vincola in modo persistente cosa il sistema sa percepire.
Una linea collegata: statistical learning in lattanti. Jenny Saffran, Richard Aslin e Elissa Newport (Science 1996, “Statistical learning by 8-month-old infants”) mostrano che lattanti di otto mesi imparano in pochi minuti le probabilità di transizione fra sillabe in un flusso di parole inventate, e usano queste probabilità per segmentare le parole. È evidenza che il sistema percettivo precoce è già un macchina d’inferenza statistica, non un foglio bianco da riempire con primitive innate. József Fiser e Aslin (Psychological Science 2002) estendono il risultato al dominio visivo: gli adulti imparano implicitamente regolarità statistiche in scene visive senza sapere di averle imparate. I priors di alto livello che guidano la percezione adulta sono prodotto di un’esposizione che parte molto presto.
Eredità oggi
Sezione intitolata “Eredità oggi”[DATATO 2026-04] — Sezione presentista in un capitolo storico-scientifico. Quanto segue è la materia che cambia più rapidamente; il resto del capitolo è impostato per durare. Discutiamo qui i punti di contatto fra perception research e AI moderna, marcando con cura le classi di affermazioni — analogia, filiazione, equivalenza, convergenza concettuale.
Quattro temi.
Hallucination LLM ↔ percezione con prior dominante
Sezione intitolata “Hallucination LLM ↔ percezione con prior dominante”Punto di contatto. Quando un large language model genera un’affermazione fattualmente errata ma stilisticamente fluente, lo fa perché il suo prior — la distribuzione di probabilità sui token appresa in pre-training — assegna alta plausibilità a quella sequenza, anche in assenza di grounding fattuale. L’analogia con la sindrome di Charles Bonnet è suggestiva: in un paziente con macular degeneration, il sistema visivo deafferentato (privato di input retinici significativi) continua a generare percetti vividi sulla base dei priors interni — visioni di volti, paesaggi, animali geometrici, di solito riconosciute dal paziente come allucinazioni. In entrambi i casi il sistema generativo continua a produrre output coerente con i propri priors anche quando l’input correttivo manca.
Classe: analogia produttiva, con caveat espliciti. Asimmetrie:
- L’LLM produce token, non percetti. Il “percetto” ha qualità fenomenologica, l’output di un LLM è una sequenza simbolica.
- Il loop di prediction error nel cervello è continuo, gerarchico, multiscale. L’LLM è autoregressivo a token, single-pass dentro la finestra.
- I priors umani sono incarnati in un sistema biologico evoluto in un ambiente specifico. I priors di un LLM sono indotti dalla statistica di un training corpus.
Quindi: l’analogia è didattica, NON è equivalenza meccanica. Vedi anche [hallucination](in preparazione) per la trattazione tecnica nel libro.
Adversarial examples e priors strutturalmente diversi
Sezione intitolata “Adversarial examples e priors strutturalmente diversi”Christian Szegedy e colleghi (Google) pubblicano nel 2013 (arXiv:1312.6199, ICLR 2014) “Intriguing properties of neural networks”: una perturbazione di pochi pixel — impercettibile per un umano — può cambiare la classificazione di una CNN da “panda” a “gibbone” con confidenza alta. Ian Goodfellow (2014) fornisce una spiegazione semplice (Fast Gradient Sign Method) e mostra che la patologia è ubiquita.
Il fatto è che l’umano e la CNN, di fronte alla stessa immagine perturbata, vedono cose diverse. Il prior umano sulla struttura visiva è invariante alla perturbazione adversarial; il prior della CNN no. È l’evidenza più chiara che le due “percezioni” condividono il termine ma non il contenuto.
Classe: convergenza concettuale (entrambi i sistemi hanno priors), divergenza meccanica (i priors sono strutturalmente diversi). Non c’è filiazione: le tecniche adversarial sono nate dentro la deep learning research, non dalla perception research. Vedi [adversarial-examples](in preparazione).
Texture bias: prior della rete vs prior umano
Sezione intitolata “Texture bias: prior della rete vs prior umano”Già discusso nell’esempio 3. Ribadisco la classe: Geirhos 2019 è una misura quantitativa di quanto il prior implicito di una CNN ImageNet-trained diverga dal prior umano. È materia per chiunque progetti sistemi di vision in produzione: la CNN non “vede come noi”, anche su task elementari.
Predictive coding ↔ next-token prediction
Sezione intitolata “Predictive coding ↔ next-token prediction”Suggestione ricorrente in talk e divulgazione: il cervello predice il prossimo input sensoriale, il transformer predice il prossimo token. Quindi sono “lo stesso meccanismo”.
No. Sono parenti concettuali, non lo stesso meccanismo. Differenze strutturali:
- Predictive coding è gerarchico, con loop di feedback continui tra livelli. Il transformer è autoregressivo a livello di token, e dentro la finestra di contesto è feedforward (nessun feedback dinamico tra layer durante il forward pass).
- I “prediction errors” del predictive coding sono quantità neurali residuali dopo che la predizione top-down è stata sottratta. La cross-entropy loss dell’NTP è una distanza tra distribuzione predetta e token osservato durante il training, non un segnale che circola dinamicamente nel modello a inference time.
- Predictive coding opera su molte scale temporali simultaneamente. NTP opera token per token.
Yann LeCun e altri hanno menzionato il parallelo concettuale, talvolta come argomento per sistemi alternativi al transformer (es. JEPA architectures). Ma l’eredità documentata è scarsa: il transformer (Vaswani et al. 2017) non cita Rao-Ballard o Friston come ispirazione.
Classe: analogia evocativa, NON filiazione, NON equivalenza meccanica. Diffidare di chiunque presenti la frase “il transformer fa predictive coding” senza qualificarla.
Multimodal models e cue combination
Sezione intitolata “Multimodal models e cue combination”I modelli moderni che combinano vista e linguaggio — CLIP (Alec Radford et al., OpenAI 2021, “Learning Transferable Visual Models From Natural Language Supervision”), Flamingo, GPT-4V, Claude vision — apprendono uno spazio congiunto in cui immagini e testo coesistono come vettori vicini quando descrivono la stessa cosa. Un osservatore che cercasse un parallelo con la perception research lo troverebbe nell’integrazione multisensoriale audio-visiva (McGurk, ventriloquismo) o visuo-haptic (Ernst-Banks).
Il parallelo è tentante ma asimmetrico. Le reti multimodali imparano un prior congiunto attraverso contrastive learning (avvicinare embedding di coppie corrispondenti, allontanare quelle sbagliate). Il sistema percettivo umano impara cue combination attraverso meccanismi probabilmente diversi (Hebbian, error-driven, statistical learning), e in particolare opera su distribuzioni con varianza esplicitamente rappresentata, cosa che le rappresentazioni vector-based dei modelli multimodali non fanno in modo nativo.
Classe: convergenza concettuale sulla nozione di “spazio di rappresentazione condiviso fra modalità”, divergenza meccanica sui dettagli di apprendimento e di rappresentazione dell’incertezza. Vedi multimodal-vision (in preparazione) per la trattazione tecnica.
Bayesian deep learning e diffusion models
Sezione intitolata “Bayesian deep learning e diffusion models”Due note brevi. Bayesian deep learning (David MacKay 1992 in Neural Computation; Yarin Gal e Zoubin Ghahramani 2016 con MC Dropout) tratta i pesi della rete come distribuzioni anziché come punti, abilitando uncertainty quantification. È figlio del bayesianesimo statistico, non della perception research specifica. Diffusion models (Jonathan Ho, Ajay Jain, Pieter Abbeel 2020, “Denoising Diffusion Probabilistic Models”, NeurIPS) implementano un prior generativo learned: imparano durante il training, e durante il sampling partono da rumore gaussiano e denoise iterativamente. Si può dire che incarnano “un prior”, ma non sono modelli percettivi (input → percetto): sono modelli generativi (rumore → campione). L’analogia “diffusion = sistema percettivo” è debole e va evitata. Vedi [diffusion](in preparazione).
Dove si rompe
Sezione intitolata “Dove si rompe”Il framework bayesiano-predictive è potente ma ha punti deboli reali. Non sono dettagli pedanti: condizionano cosa si può sostenere e cosa è speculazione.
Il presentismo del cliché “vediamo la realtà oggettivamente”
Sezione intitolata “Il presentismo del cliché “vediamo la realtà oggettivamente””Va smontato esplicitamente. Il senso comune adulto continua a credere che gli occhi forniscano “ciò che c’è”, e la scienza percettiva — incluso questo capitolo — combatte questo cliché. Ma il cliché opposto è altrettanto ingannevole: “tutto è costruito, niente è reale”. I priors percettivi sono ben tarati sull’ambiente in cui l’organismo si è evoluto e sviluppato. Le illusioni sono casi limite, non la norma. Nella maggior parte delle scene quotidiane il sistema produce percetti che corrispondono accuratamente alla geometria fisica. Il messaggio non è “non ti fidare dei tuoi occhi”; è “ciò che gli occhi ti danno è il prodotto di un’inferenza, e l’inferenza è solo quasi sempre giusta”.
Quando le illusioni non funzionano
Sezione intitolata “Quando le illusioni non funzionano”C’è una controparte trascurata della letteratura sulle illusioni: i casi in cui un’illusione robusta in una popolazione non si verifica in un’altra. La Müller-Lyer, su cui generazioni di studenti di psicologia si sono esercitati, è stata studiata cross-culturalmente da Marshall Segall, Donald Campbell e Melville Herskovits in The Influence of Culture on Visual Perception (1966). Soggetti di alcune culture africane non urbane mostrano l’illusione molto attenuata o assente. L’interpretazione costruttivista è coerente: se il prior responsabile dell’illusione è “le frecce esterne segnalano un angolo lontano in un mondo di stanze rettangolari”, allora chi cresce in un mondo non-carpenterato non sviluppa il prior nella stessa forma.
Il dato è discusso (alcuni studi successivi mostrano effetti più ridotti della differenza cross-culturale), ma la lezione resta: i priors percettivi non sono immutabili universali biologici, sono modulati dall’esposizione ecologica. Un sistema percettivo è un sistema percettivo specifico, plasmato da una storia statistica specifica. La generalizzazione “tutti gli umani vedono X così” va presa con cautela quando “X” implica un prior di alto livello.
Critica di Gibson al costruttivismo
Sezione intitolata “Critica di Gibson al costruttivismo”Gibson ha argomenti seri. Se l’informazione invariante nel flusso ottico è già sufficiente a specificare la scena per un organismo che si muove nell’ambiente, allora l’inferenza “interna” è meno necessaria di quanto i costruttivisti suppongono. Il programma ecologico ha prodotto risultati robusti su locomozione, controllo motorio, percezione di self-motion. La sintesi che i bayesiani propongono — “i priors sono invarianti dell’ambiente” — concede molto a Gibson, ma alcuni gibsoniani la trovano insufficiente: rimane la domanda se l’inferenza interna sia descritta accuratamente come Bayes o sia un epifenomeno della risuonanza diretta. Il dibattito è aperto. Vedi cognitivismo-ecologico.
Free energy principle: troppo flessibile?
Sezione intitolata “Free energy principle: troppo flessibile?”Il free energy principle di Friston ha critici noti. Jakob Hohwy, Eric Schwitzgebel e altri hanno argomentato che la teoria, nella sua forma più generale, spiega tutto e proprio per questo predice poco di falsificabile. Quando chiunque azione e percezione sono “minimizzazione di free energy”, la teoria diventa tautologica: ogni risposta del sistema può essere riformulata come “ha minimizzato la free energy data una qualche distribuzione q”. I sostenitori rispondono che il principio è una lingua franca unificante, non una teoria empirica diretta, e che modelli specifici di active inference sono falsificabili. Resta il fatto che la falsificabilità a livello generale è bassa.
Pellicano-Burr 2012 e l’autismo
Sezione intitolata “Pellicano-Burr 2012 e l’autismo”Elizabeth Pellicano e David Burr propongono nel 2012 (Trends in Cognitive Sciences) che l’autismo possa essere caratterizzato da “hyper-precision di low-level priors”, o in formulazioni successive da “hypo-priors”. L’idea ha attirato attenzione mediatica e clinica. È controversa: gli studi successivi danno evidenze contrastanti, e parlare di “Bayesian autism” ha rischi di semplificazione eccessiva. Il punto è che applicare il framework bayesiano alle psicopatologie è promettente, ma richiede prudenza diagnostica.
Equivalenze AI ingiuste
Sezione intitolata “Equivalenze AI ingiuste”Già detto, ma sintetizzo le tentazioni da evitare:
- “Hallucination LLM = percezione umana con prior” → analogia, non equivalenza.
- “Predictive coding = next-token prediction” → analogia evocativa, meccanismi diversi.
- “Diffusion = sistema percettivo” → no.
- “ANN attention = attenzione visiva” → trattato in ponte-attenzione-transformer, in breve: nome condiviso, oggetti diversi.
L’ingiustizia non è solo terminologica. Quando una metafora si solidifica in equivalenza, due cose succedono: la perception research perde specificità (ridotta a una caricatura di “cervello bayesiano”), e l’AI guadagna autorità impropria (suggerendo che gli LLM “vedano” come noi). Marcare le classi di affermazioni è un’operazione di igiene scientifica.
Il problema della rappresentazione delle distribuzioni nei neuroni
Sezione intitolata “Il problema della rappresentazione delle distribuzioni nei neuroni”Una difficoltà tecnica spesso trascurata nelle presentazioni divulgative: il framework bayesiano richiede che il sistema rappresenti distribuzioni di probabilità (prior, likelihood, posterior), non solo stime puntuali. Come fa una popolazione di neuroni a codificare una distribuzione? Tre proposte coesistono in letteratura, ciascuna con limiti:
- Probabilistic population codes (Ma, Beck, Latham, Pouget, Nature Neuroscience 2006): la varianza della distribuzione è codificata nella varianza dell’attività di una popolazione di neuroni con tuning curves sovrapposte. Eleganza matematica, ma vincolata a famiglie esponenziali.
- Sampling: il sistema rappresenta una distribuzione campionando da essa, e la fluttuazione neurale a riposo (spontaneous activity) è il “campionamento” del prior. Spiega la bistabilità come oscillazione fra campioni alternativi del posterior. Critiche: il sampling è lento rispetto ai tempi percettivi.
- Variational schemes: come in Friston, il sistema mantiene una distribuzione approssimante con pochi parametri (tipicamente media e precision), e aggiorna iterativamente i parametri.
Nessuna delle tre ha vinto in modo conclusivo. Il framework bayesiano-predictive è quindi più solido come descrizione computazionale (livello di Marr 1) che come implementazione neurale (livello di Marr 3). È una distinzione che vale la pena tenere a mente.
Scarsa filiazione documentata
Sezione intitolata “Scarsa filiazione documentata”A onor del vero. Il transformer non è figlio di Rao-Ballard. Le architetture diffusion non sono figlie di Knill-Richards. Bayesian deep learning ha radici in MacKay 1992, indipendenti dalla perception research. La cross-fertilization fra le due aree esiste — JEPA, predictive coding-inspired networks, sparse coding di Olshausen-Field 1996 — ma è limitata. Quando si parla di “priors” in entrambi gli ambiti, è prevalentemente convergenza concettuale, non lineage.
Collegamenti
Sezione intitolata “Collegamenti”Il capitolo è un nodo della Parte III e si collega a numerosi altri.
- [cervello-basi](in preparazione): le strutture neurali — V1, V2, V4, IT, prefrontale — su cui il predictive coding è mappato.
- attenzione-psicologia: la precision in predictive processing è il punto di contatto formale con l’attenzione. Modulare la precision di un canale di errore equivale a “prestargli attenzione”.
- memoria-working: il visuospatial sketchpad di Baddeley è il buffer su cui i priors percettivi operano nel breve termine.
- [memoria-lungo-termine](in preparazione): i priors di alto livello (facce, oggetti familiari) sono memoria semantica acquisita, non solo strutturale.
- [dual-process-kahneman](in preparazione): Sistema 1 / Sistema 2 ha un parallelo nella distinzione automatic/controlled del processing percettivo. La percezione è prevalentemente Sistema 1.
- [bayes-base](in preparazione): il teorema di Bayes formale di cui questo capitolo è un’applicazione.
- cognitivismo-ecologico: la critica gibsoniana al costruttivismo computazionale.
- [hallucination](in preparazione): l’hallucination LLM, da leggere DOPO questo capitolo per evitare l’equivalenza facile.
- [adversarial-examples](in preparazione): perché i priors degli ANN divergono dai priors umani, con implicazioni di sicurezza.
- [diffusion](in preparazione): i diffusion models come prior generativo, con il caveat che non sono modelli percettivi.
- multimodal-vision (in preparazione): CLIP e simili come priors multimodali learned.
Le illusioni di basso livello e il problema della “cognitive penetrability”
Sezione intitolata “Le illusioni di basso livello e il problema della “cognitive penetrability””Una distinzione finale importante. Alcune illusioni — Müller-Lyer in particolare — non si dissolvono con la conoscenza esplicita. Se ti dicono “questi due segmenti sono uguali”, continui a vederli diversi. La percezione è cognitively impenetrable rispetto al sapere esplicito: i priors di basso livello non vengono sovrascritti dal contenuto proposizionale. Altre illusioni, di livello più alto, sono parzialmente penetrabili: una volta che impari a riconoscere il pattern dei “magic eye” stereogrammi, lo vedi più facilmente la volta dopo.
La distinzione fra penetrabile e impenetrabile è stata teorizzata da Zenon Pylyshyn (filosofo cognitivo canadese, Behavioral and Brain Sciences 1999) come argomento contro la tesi che la percezione sia interamente top-down. La sintesi predictive contemporanea acconsente: i priors di basso livello sono cablati nei circuiti corticali precoci e cambiano molto lentamente; i priors di alto livello sono più plastici e accessibili. La cognitive penetrability è una variabile, non un binario.
Implicazione per chi progetta interfacce o sistemi di safety-critical visualization: una volta che un osservatore vede una piastrella come chiara, non puoi convincerlo razionalmente che sia scura. Devi cambiare il contesto visivo, perché è il contesto a fornire il prior che il sistema applica.
Un’ultima nota legata. Il fenomeno del change blindness — la difficoltà a notare cambiamenti graduali in una scena visiva quando un evento mascherante (un flicker, un movimento oculare) interrompe la continuità — è coerente con il quadro: il sistema visivo non mantiene una rappresentazione fotografica del campo visivo, mantiene un modello con priors che vengono aggiornati selettivamente sulla base di errori salienti. Se l’errore è nascosto da un disturbo, l’aggiornamento non avviene, e la rappresentazione interna resta stabile pur essendo obsoleta. Daniel Simons e Daniel Levin (1997) hanno mostrato esempi sorprendenti: in una conversazione interrotta da un’ostruzione momentanea, il soggetto non si accorge che l’interlocutore è stato sostituito da un’altra persona. Mostra ancora una volta che il “vedere” è fortemente economizzato: il sistema non duplica il mondo, ne mantiene un modello al minimo necessario per agire.
Glossario operativo
Sezione intitolata “Glossario operativo”Per riferimento rapido. Decoder già introdotti nel capitolo, qui condensati.
- Prior : distribuzione di probabilità sulle scene possibili, codifica le regolarità del mondo apprese o evolute.
- Likelihood : probabilità del dato sensoriale
ddato che la scena sias. Codifica il modello di formazione del dato. - Posterior : distribuzione di credenza sulla scena dato il dato osservato. Per Bayes, proporzionale a .
- MAP (maximum a posteriori): la scena
sche massimizza il posterior. Stima puntuale del percetto. - MLE (maximum likelihood estimation): la scena che massimizza solo il likelihood. Equivalente al MAP con prior uniforme.
- Cue combination: integrazione di più canali sensoriali per stimare la stessa grandezza, con pesi inversi alle varianze.
- Precision: inverso della varianza. In predictive processing modula quanto un prediction error pesa nell’aggiornamento del modello.
- Prediction error: differenza fra predizione top-down e dato bottom-up. Variabile centrale del predictive coding.
- Active inference: minimizzazione di prediction error agendo sul mondo invece che aggiornando il modello.
- Free energy (variazionale): upper bound sulla surprise; minimizzarla è una formulazione unificante di percezione e azione.
- Affordance: possibilità d’azione che l’ambiente offre direttamente, concetto gibsoniano.
- Generative model: modello probabilistico congiunto che genera dati dati gli stati. Nel cervello: il modello che il sistema “porta dentro” e usa per fare predizioni top-down.
- Cognitive penetrability: misura in cui la percezione può essere modificata da conoscenze esplicite. I priors di basso livello sono prevalentemente impenetrabili.
Per andare oltre
Sezione intitolata “Per andare oltre”Cinque letture che valgono il tempo, ordinate dalla più accessibile alla più tecnica.
-
Gregory, Eye and Brain, 5a ed., Princeton University Press 1997. Divulgativo ma rigoroso. Punto di ingresso ideale alla tradizione costruttivista, scritto da uno dei suoi protagonisti. Esiste traduzione italiana in edizioni precedenti.
-
Clark, Surfing Uncertainty: Prediction, Action, and the Embodied Mind, Oxford University Press 2016. Sintesi filosofica del programma predictive processing. Il testo di riferimento per chi vuole il quadro concettuale completo, dalle illusioni al free energy principle.
-
Knill & Richards (eds.), Perception as Bayesian Inference, Cambridge University Press 1996. Volume più tecnico, con contributi di vari autori. Letture selezionate sufficienti per fissare il formalismo bayesiano applicato alla vision.
-
Friston, “The free-energy principle: a unified brain theory?”, Nature Reviews Neuroscience 11(2), 2010, pp. 127–138. Il manifesto. Da leggere con attenzione critica: la matematica è densa, la portata è grande, le critiche sono legittime.
-
Geirhos et al., “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness”, ICLR 2019. Lettura obbligatoria per chi lavora con vision systems: misura quantitativa della differenza fra prior umano e prior di una CNN, con implicazioni dirette sulla robustezza.
A queste si possono aggiungere, per chi voglia approfondire aspetti specifici: Marr, Vision, Freeman 1982 (la distinzione computazionale-algoritmica-implementativa che usiamo qui); Hohwy, The Predictive Mind, Oxford University Press 2013 (lettura filosofica complementare a Clark); Sterzer, Adams, Fletcher et al., “The predictive coding account of psychosis”, Biological Psychiatry 84(9), 2018 (per il versante clinico). Per chi parte completamente da zero sul Bayesianesimo, i primi capitoli di Pearl, Probabilistic Reasoning in Intelligent Systems, Morgan Kaufmann 1988, restano un’ottima introduzione conceptual prima di tuffarsi nella perception literature.